Function call¶
This chapter introduces support for subroutine and function calls in backend translation. A significant amount of code is required to support function calls, and it is organized using LLVM-supplied interfaces for clarity.
The chapter begins by introducing the MIPS stack frame structure, as many parts of the ABI are borrowed from it. Although each CPU has its own ABI, most RISC CPU ABIs share similar characteristics.
Section “4.5 DAG Lowering” of tricore_llvm.pdf provides insight into the lowering process. Section “4.5.1 Calling Conventions” in the same document is also a helpful reference for further understanding.
If you have difficulty understanding the stack frame illustrated in the first three sections of this chapter, you may consult the following resources: Appendix B, “Procedure Call Convention,” in Computer Organization and Design, 1st Edition [1]; “Run Time Memory” in a compiler textbook; or “Function Call Sequence” and “Stack Frame” in the MIPS ABI [3].
MIPS Stack Frame¶
The first step in designing Cpu0 function calls is deciding how to pass arguments. There are two options:
Pass all arguments on the stack.
Pass arguments using registers reserved for function arguments, and place any remaining arguments on the stack once the registers are full.
For example, MIPS passes the first four arguments in registers $a0, $a1, $a2, and $a3. Any additional arguments are passed on the stack. Fig. 39 illustrates the MIPS stack frame.
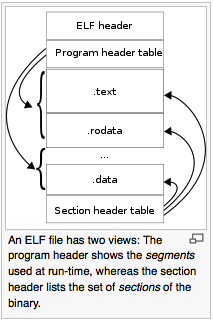
Fig. 39 Mips stack frame¶
Run llc -march=mips on ch9_1.bc, and you will get the following result.
See the comments marked with “//”.
lbdex/input/ch9_1.cpp
int gI = 100;
int sum_i(int x1, int x2, int x3, int x4, int x5, int x6)
{
int sum = gI + x1 + x2 + x3 + x4 + x5 + x6;
return sum;
}
int main()
{
int a = sum_i(1, 2, 3, 4, 5, 6);
return a;
}
118-165-78-230:input Jonathan$ clang -target mips-unknown-linux-gnu -c
ch9_1.cpp -emit-llvm -o ch9_1.bc
118-165-78-230:input Jonathan$ /Users/Jonathan/llvm/test/build/
bin/llc -march=mips -relocation-model=pic -filetype=asm ch9_1.bc -o
ch9_1.mips.s
118-165-78-230:input Jonathan$ cat ch9_1.mips.s
.section .mdebug.abi32
.previous
.file "ch9_1.bc"
.text
.globl _Z5sum_iiiiiii
.align 2
.type _Z5sum_iiiiiii,@function
.set nomips16 # @_Z5sum_iiiiiii
.ent _Z5sum_iiiiiii
_Z5sum_iiiiiii:
.cfi_startproc
.frame $sp,32,$ra
.mask 0x00000000,0
.fmask 0x00000000,0
.set noreorder
.set nomacro
.set noat
# BB#0:
addiu $sp, $sp, -32
$tmp1:
.cfi_def_cfa_offset 32
sw $4, 28($sp)
sw $5, 24($sp)
sw $t9, 20($sp)
sw $7, 16($sp)
lw $1, 48($sp) // load argument 5
sw $1, 12($sp)
lw $1, 52($sp) // load argument 6
sw $1, 8($sp)
lw $2, 24($sp)
lw $3, 28($sp)
addu $2, $3, $2
lw $3, 20($sp)
addu $2, $2, $3
lw $3, 16($sp)
addu $2, $2, $3
lw $3, 12($sp)
addu $2, $2, $3
addu $2, $2, $1
sw $2, 4($sp)
jr $ra
addiu $sp, $sp, 32
.set at
.set macro
.set reorder
.end _Z5sum_iiiiiii
$tmp2:
.size _Z5sum_iiiiiii, ($tmp2)-_Z5sum_iiiiiii
.cfi_endproc
.globl main
.align 2
.type main,@function
.set nomips16 # @main
.ent main
main:
.cfi_startproc
.frame $sp,40,$ra
.mask 0x80000000,-4
.fmask 0x00000000,0
.set noreorder
.set nomacro
.set noat
# BB#0:
lui $2, %hi(_gp_disp)
ori $2, $2, %lo(_gp_disp)
addiu $sp, $sp, -40
$tmp5:
.cfi_def_cfa_offset 40
sw $ra, 36($sp) # 4-byte Folded Spill
$tmp6:
.cfi_offset 31, -4
addu $gp, $2, $25
sw $zero, 32($sp)
addiu $1, $zero, 6
sw $1, 20($sp) // Save argument 6 to 20($sp)
addiu $1, $zero, 5
sw $1, 16($sp) // Save argument 5 to 16($sp)
lw $25, %call16(_Z5sum_iiiiiii)($gp)
addiu $4, $zero, 1 // Pass argument 1 to $4 (=$a0)
addiu $5, $zero, 2 // Pass argument 2 to $5 (=$a1)
addiu $t9, $zero, 3
jalr $25
addiu $7, $zero, 4
sw $2, 28($sp)
lw $ra, 36($sp) # 4-byte Folded Reload
jr $ra
addiu $sp, $sp, 40
.set at
.set macro
.set reorder
.end main
$tmp7:
.size main, ($tmp7)-main
.cfi_endproc
From the MIPS assembly code generated above, we can see that the first four arguments are saved in registers $a0 to $a3, and the last two arguments are saved at memory locations 16($sp) and 20($sp).
Fig. 40 shows the location of the arguments in the example code ch9_1.cpp.
In the sum_i() function, argument 5 is loaded from 48($sp) because it was stored at 16($sp) in the main() function. Since the stack size of sum_i() is 32, the address of the incoming argument 5 is calculated as 16 + 32 = 48($sp).
Fig. 40 Mips arguments location in stack frame¶
The document 007-2418-003.pdf referenced in [2] is the MIPS assembly language manual. The MIPS Application Binary Interface, referenced in [3], includes the diagram shown in Fig. 39.
Load Incoming Arguments from Stack Frame¶
As discussed in the previous section, supporting function calls requires implementing an argument-passing mechanism using the stack frame.
Before proceeding with the implementation, let’s run the old version of the code in Chapter8_2/ with ch9_1.cpp and observe what happens.
118-165-79-31:input Jonathan$ /Users/Jonathan/llvm/test/
build/bin/llc -march=cpu0 -relocation-model=pic -filetype=asm
ch9_1.bc -o ch9_1.cpu0.s
Assertion failed: (InVals.size() == Ins.size() && "LowerFormalArguments didn't
emit the correct number of values!"), function LowerArguments, file /Users/
Jonathan/llvm/test/llvm/lib/CodeGen/SelectionDAG/
SelectionDAGBuilder.cpp, ...
...
0. Program arguments: /Users/Jonathan/llvm/test/build/
bin/llc -march=cpu0 -relocation-model=pic -filetype=asm ch9_1.bc -o
ch9_1.cpu0.s
1. Running pass 'Function Pass Manager' on module 'ch9_1.bc'.
2. Running pass 'CPU0 DAG->DAG Pattern Instruction Selection' on function
'@_Z5sum_iiiiiii'
Illegal instruction: 4
Since Chapter8_2/ defines LowerFormalArguments() with an empty body, we receive the error messages shown above.
Before implementing LowerFormalArguments(), we must first decide how to pass arguments in a function call.
For demonstration purposes, Cpu0 passes the first two arguments in registers by
default, which corresponds to the setting llc -cpu0-s32-calls=false.
When using llc -cpu0-s32-calls=true, Cpu0 passes all its arguments on the
stack.
The function LowerFormalArguments() is responsible for creating the incoming arguments. We define it as follows:
lbdex/chapters/Chapter9_1/Cpu0ISelLowering.h
class Cpu0TargetLowering : public TargetLowering {
/// Cpu0CC - This class provides methods used to analyze formal and call
/// arguments and inquire about calling convention information.
class Cpu0CC {
void analyzeFormalArguments(const SmallVectorImpl<ISD::InputArg> &Ins,
bool IsSoftFloat,
Function::const_arg_iterator FuncArg);
/// regSize - Size (in number of bits) of integer registers.
unsigned regSize() const { return IsO32 ? 4 : 4; }
/// numIntArgRegs - Number of integer registers available for calls.
unsigned numIntArgRegs() const;
/// Return pointer to array of integer argument registers.
const ArrayRef<MCPhysReg> intArgRegs() const;
void handleByValArg(unsigned ValNo, MVT ValVT, MVT LocVT,
CCValAssign::LocInfo LocInfo,
ISD::ArgFlagsTy ArgFlags);
/// useRegsForByval - Returns true if the calling convention allows the
/// use of registers to pass byval arguments.
bool useRegsForByval() const { return CallConv != CallingConv::Fast; }
/// Return the function that analyzes fixed argument list functions.
llvm::CCAssignFn *fixedArgFn() const;
void allocateRegs(ByValArgInfo &ByVal, unsigned ByValSize,
unsigned Align);
};
...
/// isEligibleForTailCallOptimization - Check whether the call is eligible
/// for tail call optimization.
virtual bool
isEligibleForTailCallOptimization(const Cpu0CC &Cpu0CCInfo,
unsigned NextStackOffset,
const Cpu0FunctionInfo& FI) const = 0;
/// copyByValArg - Copy argument registers which were used to pass a byval
/// argument to the stack. Create a stack frame object for the byval
/// argument.
void copyByValRegs(SDValue Chain, const SDLoc &DL,
std::vector<SDValue> &OutChains, SelectionDAG &DAG,
const ISD::ArgFlagsTy &Flags,
SmallVectorImpl<SDValue> &InVals,
const Argument *FuncArg,
const Cpu0CC &CC, const ByValArgInfo &ByVal) const;
SDValue LowerCall(TargetLowering::CallLoweringInfo &CLI,
SmallVectorImpl<SDValue> &InVals) const override;
...
}
lbdex/chapters/Chapter9_1/Cpu0ISelLowering.cpp
// addLiveIn - This helper function adds the specified physical register to the
// MachineFunction as a live in value. It also creates a corresponding
// virtual register for it.
static unsigned
addLiveIn(MachineFunction &MF, unsigned PReg, const TargetRegisterClass *RC)
{
unsigned VReg = MF.getRegInfo().createVirtualRegister(RC);
MF.getRegInfo().addLiveIn(PReg, VReg);
return VReg;
}
//===----------------------------------------------------------------------===//
// TODO: Implement a generic logic using tblgen that can support this.
// Cpu0 32 ABI rules:
// ---
//===----------------------------------------------------------------------===//
// Passed in stack only.
static bool CC_Cpu0S32(unsigned ValNo, MVT ValVT, MVT LocVT,
CCValAssign::LocInfo LocInfo, ISD::ArgFlagsTy ArgFlags,
CCState &State) {
// Do not process byval args here.
if (ArgFlags.isByVal())
return true;
// Promote i8 and i16
if (LocVT == MVT::i8 || LocVT == MVT::i16) {
LocVT = MVT::i32;
if (ArgFlags.isSExt())
LocInfo = CCValAssign::SExt;
else if (ArgFlags.isZExt())
LocInfo = CCValAssign::ZExt;
else
LocInfo = CCValAssign::AExt;
}
Align OrigAlign = ArgFlags.getNonZeroOrigAlign();
unsigned Offset = State.AllocateStack(ValVT.getSizeInBits() >> 3,
OrigAlign);
State.addLoc(CCValAssign::getMem(ValNo, ValVT, Offset, LocVT, LocInfo));
return false;
}
// Passed first two i32 arguments in registers and others in stack.
static bool CC_Cpu0O32(unsigned ValNo, MVT ValVT, MVT LocVT,
CCValAssign::LocInfo LocInfo, ISD::ArgFlagsTy ArgFlags,
CCState &State) {
static const MCPhysReg IntRegs[] = { Cpu0::A0, Cpu0::A1 };
// Do not process byval args here.
if (ArgFlags.isByVal())
return true;
// Promote i8 and i16
if (LocVT == MVT::i8 || LocVT == MVT::i16) {
LocVT = MVT::i32;
if (ArgFlags.isSExt())
LocInfo = CCValAssign::SExt;
else if (ArgFlags.isZExt())
LocInfo = CCValAssign::ZExt;
else
LocInfo = CCValAssign::AExt;
}
unsigned Reg;
// f32 and f64 are allocated in A0, A1 when either of the following
// is true: function is vararg, argument is 3rd or higher, there is previous
// argument which is not f32 or f64.
bool AllocateFloatsInIntReg = true;
Align OrigAlign = ArgFlags.getNonZeroOrigAlign();
bool isI64 = (ValVT == MVT::i32 && OrigAlign == 8);
if (ValVT == MVT::i32 || (ValVT == MVT::f32 && AllocateFloatsInIntReg)) {
Reg = State.AllocateReg(IntRegs);
// If this is the first part of an i64 arg,
// the allocated register must be A0.
if (isI64 && (Reg == Cpu0::A1))
Reg = State.AllocateReg(IntRegs);
LocVT = MVT::i32;
} else if (ValVT == MVT::f64 && AllocateFloatsInIntReg) {
// Allocate int register. If first
// available register is Cpu0::A1, shadow it too.
Reg = State.AllocateReg(IntRegs);
if (Reg == Cpu0::A1)
Reg = State.AllocateReg(IntRegs);
State.AllocateReg(IntRegs);
LocVT = MVT::i32;
} else
llvm_unreachable("Cannot handle this ValVT.");
if (!Reg) {
unsigned Offset = State.AllocateStack(ValVT.getSizeInBits() >> 3,
Align(OrigAlign));
State.addLoc(CCValAssign::getMem(ValNo, ValVT, Offset, LocVT, LocInfo));
} else
State.addLoc(CCValAssign::getReg(ValNo, ValVT, Reg, LocVT, LocInfo));
return false;
}
//===----------------------------------------------------------------------===//
// Call Calling Convention Implementation
//===----------------------------------------------------------------------===//
static const MCPhysReg O32IntRegs[] = {
Cpu0::A0, Cpu0::A1
};
//@LowerCall {
/// LowerCall - functions arguments are copied from virtual regs to
/// (physical regs)/(stack frame), CALLSEQ_START and CALLSEQ_END are emitted.
SDValue
Cpu0TargetLowering::LowerCall(TargetLowering::CallLoweringInfo &CLI,
SmallVectorImpl<SDValue> &InVals) const {
//@LowerCall {
/// LowerCall - functions arguments are copied from virtual regs to
/// (physical regs)/(stack frame), CALLSEQ_START and CALLSEQ_END are emitted.
SDValue
Cpu0TargetLowering::LowerCall(TargetLowering::CallLoweringInfo &CLI,
SmallVectorImpl<SDValue> &InVals) const {
return CLI.Chain;
}
//===----------------------------------------------------------------------===//
//@LowerFormalArguments {
/// LowerFormalArguments - transform physical registers into virtual registers
/// and generate load operations for arguments places on the stack.
SDValue
Cpu0TargetLowering::LowerFormalArguments(SDValue Chain,
CallingConv::ID CallConv,
bool IsVarArg,
const SmallVectorImpl<ISD::InputArg> &Ins,
const SDLoc &DL, SelectionDAG &DAG,
SmallVectorImpl<SDValue> &InVals)
const {
MachineFunction &MF = DAG.getMachineFunction();
MachineFrameInfo &MFI = MF.getFrameInfo();
Cpu0FunctionInfo *Cpu0FI = MF.getInfo<Cpu0FunctionInfo>();
Cpu0FI->setVarArgsFrameIndex(0);
// Assign locations to all of the incoming arguments.
SmallVector<CCValAssign, 16> ArgLocs;
CCState CCInfo(CallConv, IsVarArg, DAG.getMachineFunction(),
ArgLocs, *DAG.getContext());
Cpu0CC Cpu0CCInfo(CallConv, ABI.IsO32(),
CCInfo);
const Function &Func = DAG.getMachineFunction().getFunction();
Function::const_arg_iterator FuncArg = Func.arg_begin();
bool UseSoftFloat = Subtarget.abiUsesSoftFloat();
Cpu0CCInfo.analyzeFormalArguments(Ins, UseSoftFloat, FuncArg);
Cpu0FI->setFormalArgInfo(CCInfo.getNextStackOffset(),
Cpu0CCInfo.hasByValArg());
// Used with vargs to acumulate store chains.
std::vector<SDValue> OutChains;
unsigned CurArgIdx = 0;
Cpu0CC::byval_iterator ByValArg = Cpu0CCInfo.byval_begin();
//@2 {
for (unsigned i = 0, e = ArgLocs.size(); i != e; ++i) {
//@2 }
CCValAssign &VA = ArgLocs[i];
if (Ins[i].isOrigArg()) {
std::advance(FuncArg, Ins[i].getOrigArgIndex() - CurArgIdx);
CurArgIdx = Ins[i].getOrigArgIndex();
}
EVT ValVT = VA.getValVT();
ISD::ArgFlagsTy Flags = Ins[i].Flags;
bool IsRegLoc = VA.isRegLoc();
//@byval pass {
if (Flags.isByVal()) {
assert(Flags.getByValSize() &&
"ByVal args of size 0 should have been ignored by front-end.");
assert(ByValArg != Cpu0CCInfo.byval_end());
copyByValRegs(Chain, DL, OutChains, DAG, Flags, InVals, &*FuncArg,
Cpu0CCInfo, *ByValArg);
++ByValArg;
continue;
}
//@byval pass }
// Arguments stored on registers
if (ABI.IsO32() && IsRegLoc) {
MVT RegVT = VA.getLocVT();
unsigned ArgReg = VA.getLocReg();
const TargetRegisterClass *RC = getRegClassFor(RegVT);
// Transform the arguments stored on
// physical registers into virtual ones
unsigned Reg = addLiveIn(DAG.getMachineFunction(), ArgReg, RC);
SDValue ArgValue = DAG.getCopyFromReg(Chain, DL, Reg, RegVT);
// If this is an 8 or 16-bit value, it has been passed promoted
// to 32 bits. Insert an assert[sz]ext to capture this, then
// truncate to the right size.
if (VA.getLocInfo() != CCValAssign::Full) {
unsigned Opcode = 0;
if (VA.getLocInfo() == CCValAssign::SExt)
Opcode = ISD::AssertSext;
else if (VA.getLocInfo() == CCValAssign::ZExt)
Opcode = ISD::AssertZext;
if (Opcode)
ArgValue = DAG.getNode(Opcode, DL, RegVT, ArgValue,
DAG.getValueType(ValVT));
ArgValue = DAG.getNode(ISD::TRUNCATE, DL, ValVT, ArgValue);
}
// Handle floating point arguments passed in integer registers.
if ((RegVT == MVT::i32 && ValVT == MVT::f32) ||
(RegVT == MVT::i64 && ValVT == MVT::f64))
ArgValue = DAG.getNode(ISD::BITCAST, DL, ValVT, ArgValue);
InVals.push_back(ArgValue);
} else { // VA.isRegLoc()
MVT LocVT = VA.getLocVT();
// sanity check
assert(VA.isMemLoc());
// The stack pointer offset is relative to the caller stack frame.
int FI = MFI.CreateFixedObject(ValVT.getSizeInBits()/8,
VA.getLocMemOffset(), true);
// Create load nodes to retrieve arguments from the stack
SDValue FIN = DAG.getFrameIndex(FI, getPointerTy(DAG.getDataLayout()));
SDValue Load = DAG.getLoad(
LocVT, DL, Chain, FIN,
MachinePointerInfo::getFixedStack(DAG.getMachineFunction(), FI));
InVals.push_back(Load);
OutChains.push_back(Load.getValue(1));
}
}
//@Ordinary struct type: 1 {
for (unsigned i = 0, e = ArgLocs.size(); i != e; ++i) {
// The cpu0 ABIs for returning structs by value requires that we copy
// the sret argument into $v0 for the return. Save the argument into
// a virtual register so that we can access it from the return points.
if (Ins[i].Flags.isSRet()) {
unsigned Reg = Cpu0FI->getSRetReturnReg();
if (!Reg) {
Reg = MF.getRegInfo().createVirtualRegister(
getRegClassFor(MVT::i32));
Cpu0FI->setSRetReturnReg(Reg);
}
SDValue Copy = DAG.getCopyToReg(DAG.getEntryNode(), DL, Reg, InVals[i]);
Chain = DAG.getNode(ISD::TokenFactor, DL, MVT::Other, Copy, Chain);
break;
}
}
//@Ordinary struct type: 1 }
// All stores are grouped in one node to allow the matching between
// the size of Ins and InVals. This only happens when on varg functions
if (!OutChains.empty()) {
OutChains.push_back(Chain);
Chain = DAG.getNode(ISD::TokenFactor, DL, MVT::Other, OutChains);
}
return Chain;
}
// @LowerFormalArguments }
//===----------------------------------------------------------------------===//
void Cpu0TargetLowering::Cpu0CC::
analyzeFormalArguments(const SmallVectorImpl<ISD::InputArg> &Args,
bool IsSoftFloat, Function::const_arg_iterator FuncArg) {
unsigned NumArgs = Args.size();
llvm::CCAssignFn *FixedFn = fixedArgFn();
unsigned CurArgIdx = 0;
for (unsigned I = 0; I != NumArgs; ++I) {
MVT ArgVT = Args[I].VT;
ISD::ArgFlagsTy ArgFlags = Args[I].Flags;
if (Args[I].isOrigArg()) {
std::advance(FuncArg, Args[I].getOrigArgIndex() - CurArgIdx);
CurArgIdx = Args[I].getOrigArgIndex();
}
CurArgIdx = Args[I].OrigArgIndex;
if (ArgFlags.isByVal()) {
handleByValArg(I, ArgVT, ArgVT, CCValAssign::Full, ArgFlags);
continue;
}
MVT RegVT = getRegVT(ArgVT, IsSoftFloat);
if (!FixedFn(I, ArgVT, RegVT, CCValAssign::Full, ArgFlags, CCInfo))
continue;
#ifndef NDEBUG
dbgs() << "Formal Arg #" << I << " has unhandled type "
<< EVT(ArgVT).getEVTString();
#endif
llvm_unreachable(nullptr);
}
}
void Cpu0TargetLowering::Cpu0CC::handleByValArg(unsigned ValNo, MVT ValVT,
MVT LocVT,
CCValAssign::LocInfo LocInfo,
ISD::ArgFlagsTy ArgFlags) {
assert(ArgFlags.getByValSize() && "Byval argument's size shouldn't be 0.");
struct ByValArgInfo ByVal;
unsigned RegSize = regSize();
unsigned ByValSize = alignTo(ArgFlags.getByValSize(), RegSize);
Align Alignment = std::min(std::max(ArgFlags.getNonZeroByValAlign(), Align(RegSize)),
Align(RegSize * 2));
if (useRegsForByval())
allocateRegs(ByVal, ByValSize, Alignment.value());
// Allocate space on caller's stack.
ByVal.Address = CCInfo.AllocateStack(ByValSize - RegSize * ByVal.NumRegs,
Alignment);
CCInfo.addLoc(CCValAssign::getMem(ValNo, ValVT, ByVal.Address, LocVT,
LocInfo));
ByValArgs.push_back(ByVal);
}
unsigned Cpu0TargetLowering::Cpu0CC::numIntArgRegs() const {
return IsO32 ? array_lengthof(O32IntRegs) : 0;
}
const ArrayRef<MCPhysReg> Cpu0TargetLowering::Cpu0CC::intArgRegs() const {
return makeArrayRef(O32IntRegs);
}
llvm::CCAssignFn *Cpu0TargetLowering::Cpu0CC::fixedArgFn() const {
if (IsO32)
return CC_Cpu0O32;
else // IsS32
return CC_Cpu0S32;
}
void Cpu0TargetLowering::Cpu0CC::allocateRegs(ByValArgInfo &ByVal,
unsigned ByValSize,
unsigned Align) {
unsigned RegSize = regSize(), NumIntArgRegs = numIntArgRegs();
const ArrayRef<MCPhysReg> IntArgRegs = intArgRegs();
assert(!(ByValSize % RegSize) && !(Align % RegSize) &&
"Byval argument's size and alignment should be a multiple of"
"RegSize.");
ByVal.FirstIdx = CCInfo.getFirstUnallocated(IntArgRegs);
// If Align > RegSize, the first arg register must be even.
if ((Align > RegSize) && (ByVal.FirstIdx % 2)) {
CCInfo.AllocateReg(IntArgRegs[ByVal.FirstIdx]);
++ByVal.FirstIdx;
}
// Mark the registers allocated.
for (unsigned I = ByVal.FirstIdx; ByValSize && (I < NumIntArgRegs);
ByValSize -= RegSize, ++I, ++ByVal.NumRegs)
CCInfo.AllocateReg(IntArgRegs[I]);
}
As reviewed in the section “Global variable” [4], we handled global variable translation by first creating the IR DAG in LowerGlobalAddress(), and then completing instruction selection based on the corresponding machine instruction DAGs in Cpu0InstrInfo.td.
LowerGlobalAddress() is called when llc encounters a global variable access. Similarly, LowerFormalArguments() is called when entering a function.
Before entering the “for loop”, it gathers incoming argument information using CCInfo(CallConv, …, ArgLocs, …).
In ch9_1.cpp, the function sum_i(…) has 6 arguments. Thus, ArgLocs.size() is 6, with each argument’s information stored in ArgLocs[i].
If VA.isRegLoc() returns true, the argument is passed via register.
If VA.isMemLoc() returns true, the argument is passed via memory stack.
For register-passed arguments, the register is marked as “live-in”, and the value is copied directly from the register.
For stack-passed arguments, a stack offset is created for the frame index object. A load node is then created using this offset and added to the InVals vector.
When using llc -cpu0-s32-calls=false, the first two arguments are passed in
registers, and the remaining arguments are passed in the stack frame.
When using llc -cpu0-s32-calls=true, all arguments are passed in the stack
frame.
Before handling arguments, analyzeFormalArguments() is called. Inside it, fixedArgFn() is used to return the function pointer to either CC_Cpu0O32() or CC_Cpu0S32().
ArgFlags.isByVal() will be true for “struct pointer byval” arguments, such as %struct.S* byval in tailcall.ll.
With llc -cpu0-s32-calls=false, the stack offset begins at 8 (to allow space
in case argument registers are spilled). With llc -cpu0-s32-calls=true, the
stack offset begins at 0.
For example, when running ch9_1.cpp with llc -cpu0-s32-calls=true
(memory stack only), LowerFormalArguments() will be called twice:
First, for sum_i(), it will create six load DAGs for the six incoming arguments.
Second, for main(), no load DAG is created, as there are no incoming arguments.
In addition to LowerFormalArguments(), we use loadRegFromStackSlot() (defined in an earlier chapter) to generate the machine instruction “ld $r, offset($sp)”, which loads arguments from the stack frame.
GetMemOperand(…, FI, …) returns the memory location of the frame index variable, representing the offset.
For the input ch9_incoming.cpp shown below, LowerFormalArguments() will
generate the red-boxed DAG nodes illustrated in Fig. 41
and Fig. 42, corresponding to
llc -cpu0-s32-calls=true and llc -cpu0-s32-calls=false, respectively.
The root node at the bottom is created by:
lbdex/input/ch9_incoming.cpp
int sum_i(int x1, int x2, int x3)
{
int sum = x1 + x2 + x3;
return sum;
}
JonathantekiiMac:input Jonathan$ clang -O3 -target mips-unknown-linux-gnu -c
ch9_incoming.cpp -emit-llvm -o ch9_incoming.bc
JonathantekiiMac:input Jonathan$ /Users/Jonathan/llvm/test/build/
bin/llvm-dis ch9_incoming.bc -o -
...
define i32 @_Z5sum_iiii(i32 %x1, i32 %x2, i32 %x3) #0 {
%1 = add nsw i32 %x2, %x1
%2 = add nsw i32 %1, %x3
ret i32 %2
}
![digraph "dag-combine1 input for _Z5sum_iiii:" {
rankdir="BT";
// label="Incoming arguments DAG created for ch9_incoming.cpp with -cpu0-s32-calls=true";
subgraph cluster_0 {
fontcolor=red;
fontsize=24;
label = "LowerFormalArguments";
Node0x102f0dbe0 [shape=record,shape=Mrecord,label="{EntryToken|t0|{<d0>ch}}"];
Node0x10304e800 [shape=record,shape=Mrecord,label="{FrameIndex\<-1\>|t1|{<d0>i32}}"];
Node0x10304e870 [shape=record,shape=Mrecord,label="{undef|t2|{<d0>i32}}"];
Node0x10304e8e0 [shape=record,shape=Mrecord,label="{{<s0>0|<s1>1|<s2>2}|load\<LD4[FixedStack-1]\>|t3|{<d0>i32|<d1>ch}}"];
Node0x10304e8e0:s0 -> Node0x102f0dbe0:d0[color=blue,style=dashed];
Node0x10304e8e0:s1 -> Node0x10304e800:d0;
Node0x10304e8e0:s2 -> Node0x10304e870:d0;
Node0x10304e950 [shape=record,shape=Mrecord,label="{FrameIndex\<-2\>|t4|{<d0>i32}}"];
Node0x10304e9c0 [shape=record,shape=Mrecord,label="{{<s0>0|<s1>1|<s2>2}|load\<LD4[FixedStack-2]\>|t5|{<d0>i32|<d1>ch}}"];
Node0x10304e9c0:s0 -> Node0x102f0dbe0:d0[color=blue,style=dashed];
Node0x10304e9c0:s1 -> Node0x10304e950:d0;
Node0x10304e9c0:s2 -> Node0x10304e870:d0;
Node0x10304ea30 [shape=record,shape=Mrecord,label="{FrameIndex\<-3\>|t6|{<d0>i32}}"];
Node0x10304eaa0 [shape=record,shape=Mrecord,label="{{<s0>0|<s1>1|<s2>2}|load\<LD4[FixedStack-3]\>|t7|{<d0>i32|<d1>ch}}"];
Node0x10304eaa0:s0 -> Node0x102f0dbe0:d0[color=blue,style=dashed];
Node0x10304eaa0:s1 -> Node0x10304ea30:d0;
Node0x10304eaa0:s2 -> Node0x10304e870:d0;
Node0x10304eb10 [shape=record,shape=Mrecord,label="{{<s0>0|<s1>1|<s2>2|<s3>3}|TokenFactor|t8|{<d0>ch}}"];
Node0x10304eb10:s0 -> Node0x10304e8e0:d1[color=blue,style=dashed];
Node0x10304eb10:s1 -> Node0x10304e9c0:d1[color=blue,style=dashed];
Node0x10304eb10:s2 -> Node0x10304eaa0:d1[color=blue,style=dashed];
Node0x10304eb10:s3 -> Node0x102f0dbe0:d0[color=blue,style=dashed];
Node0x10304eb80 [shape=record,shape=Mrecord,label="{{<s0>0|<s1>1}|add|t9|{<d0>i32}}"];
Node0x10304eb80:s0 -> Node0x10304e9c0:d0;
Node0x10304eb80:s1 -> Node0x10304e8e0:d0;
Node0x10304ebf0 [shape=record,shape=Mrecord,label="{{<s0>0|<s1>1}|add|t10|{<d0>i32}}"];
Node0x10304ebf0:s0 -> Node0x10304eb80:d0;
Node0x10304ebf0:s1 -> Node0x10304eaa0:d0;
Node0x10304ec60 [shape=record,shape=Mrecord,label="{Register %V0|t11|{<d0>i32}}"];
}
subgraph cluster_1 {
fontcolor=red;
fontsize=24;
label = "LowerReturn";
Node0x10304ecd0 [shape=record,shape=Mrecord,label="{{<s0>0|<s1>1|<s2>2}|CopyToReg|t12|{<d0>ch|<d1>glue}}"];
Node0x10304ecd0:s0 -> Node0x10304eb10:d0[color=blue,style=dashed];
Node0x10304ecd0:s1 -> Node0x10304ec60:d0;
Node0x10304ecd0:s2 -> Node0x10304ebf0:d0;
Node0x10304ed40 [shape=record,shape=Mrecord,label="{{<s0>0|<s1>1|<s2>2}|Cpu0ISD::Ret|t13|{<d0>ch}}"];
Node0x10304ed40:s0 -> Node0x10304ecd0:d0[color=blue,style=dashed];
Node0x10304ed40:s1 -> Node0x10304ec60:d0;
Node0x10304ed40:s2 -> Node0x10304ecd0:d1[color=red,style=bold];
}
Node0x0[ plaintext=circle, label ="GraphRoot"];
Node0x0 -> Node0x10304ed40:d0[color=blue,style=dashed];
}](_images/graphviz-b0110886547f51c2775ce9092a35be35d6cc7b17.png)
Fig. 41 Incoming arguments DAG created for ch9_incoming.cpp with -cpu0-s32-calls=true¶
![digraph "dag-combine1 input for _Z5sum_iiii:" {
rankdir="BT";
// label="Figure: Incoming arguments DAG created for ch9_incoming.cpp with -cpu0-s32-calls=false";
subgraph cluster_0 {
fontcolor=red;
fontsize=24;
label = "LowerFormalArguments";
Node0x102f0e0f0 [shape=record,shape=Mrecord,label="{EntryToken|t0|{<d0>ch}}"];
Node0x10305c200 [shape=record,shape=Mrecord,label="{Register %vreg0|t1|{<d0>i32}}"];
Node0x10305c270 [shape=record,shape=Mrecord,label="{{<s0>0|<s1>1}|CopyFromReg|t2|{<d0>i32|<d1>ch}}"];
Node0x10305c270:s0 -> Node0x102f0e0f0:d0[color=blue,style=dashed];
Node0x10305c270:s1 -> Node0x10305c200:d0;
Node0x10305c2e0 [shape=record,shape=Mrecord,label="{Register %vreg1|t3|{<d0>i32}}"];
Node0x10305c350 [shape=record,shape=Mrecord,label="{{<s0>0|<s1>1}|CopyFromReg|t4|{<d0>i32|<d1>ch}}"];
Node0x10305c350:s0 -> Node0x102f0e0f0:d0[color=blue,style=dashed];
Node0x10305c350:s1 -> Node0x10305c2e0:d0;
Node0x10305c3c0 [shape=record,shape=Mrecord,label="{FrameIndex\<-1\>|t5|{<d0>i32}}"];
Node0x10305c430 [shape=record,shape=Mrecord,label="{undef|t6|{<d0>i32}}"];
Node0x10305c4a0 [shape=record,shape=Mrecord,label="{{<s0>0|<s1>1|<s2>2}|load\<LD4[FixedStack-1]\>|t7|{<d0>i32|<d1>ch}}"];
Node0x10305c4a0:s0 -> Node0x102f0e0f0:d0[color=blue,style=dashed];
Node0x10305c4a0:s1 -> Node0x10305c3c0:d0;
Node0x10305c4a0:s2 -> Node0x10305c430:d0;
Node0x10305c510 [shape=record,shape=Mrecord,label="{{<s0>0|<s1>1}|add|t8|{<d0>i32}}"];
Node0x10305c510:s0 -> Node0x10305c350:d0;
Node0x10305c510:s1 -> Node0x10305c270:d0;
Node0x10305c580 [shape=record,shape=Mrecord,label="{{<s0>0|<s1>1}|add|t9|{<d0>i32}}"];
Node0x10305c580:s0 -> Node0x10305c510:d0;
Node0x10305c580:s1 -> Node0x10305c4a0:d0;
Node0x10305c5f0 [shape=record,shape=Mrecord,label="{Register %V0|t10|{<d0>i32}}"];
}
subgraph cluster_1 {
fontcolor=red;
fontsize=24;
label = "LowerReturn";
Node0x10305c660 [shape=record,shape=Mrecord,label="{{<s0>0|<s1>1|<s2>2}|CopyToReg|t11|{<d0>ch|<d1>glue}}"];
Node0x10305c660:s0 -> Node0x10305c4a0:d1[color=blue,style=dashed];
Node0x10305c660:s1 -> Node0x10305c5f0:d0;
Node0x10305c660:s2 -> Node0x10305c580:d0;
Node0x10305c6d0 [shape=record,shape=Mrecord,label="{{<s0>0|<s1>1|<s2>2}|Cpu0ISD::Ret|t12|{<d0>ch}}"];
Node0x10305c6d0:s0 -> Node0x10305c660:d0[color=blue,style=dashed];
Node0x10305c6d0:s1 -> Node0x10305c5f0:d0;
Node0x10305c6d0:s2 -> Node0x10305c660:d1[color=red,style=bold];
}
Node0x0[ plaintext=circle, label ="GraphRoot"];
Node0x0 -> Node0x10305c6d0:d0[color=blue,style=dashed];
}](_images/graphviz-5ed0ca5360e7d6c34af46f48366be7aa4a1c765c.png)
Fig. 42 Incoming arguments DAG created for ch9_incoming.cpp with -cpu0-s32-calls=false¶
In addition to the calling convention and LowerFormalArguments(), Chapter9_1/ adds support for instruction selection and printing of the Cpu0 instructions swi (software interrupt), jsub, and jalr (function call).
lbdex/chapters/Chapter9_1/Cpu0InstrInfo.td
def SDT_Cpu0JmpLink : SDTypeProfile<0, 1, [SDTCisVT<0, iPTR>]>;
// Call
def Cpu0JmpLink : SDNode<"Cpu0ISD::JmpLink",SDT_Cpu0JmpLink,
[SDNPHasChain, SDNPOutGlue, SDNPOptInGlue,
SDNPVariadic]>;
class IsTailCall {
bit isCall = 1;
bit isTerminator = 1;
bit isReturn = 1;
bit isBarrier = 1;
bit hasExtraSrcRegAllocReq = 1;
bit isCodeGenOnly = 1;
}
def calltarget : Operand<iPTR> {
let EncoderMethod = "getJumpTargetOpValue";
let OperandType = "OPERAND_PCREL";
}
let Predicates = [Ch9_1] in {
// Jump and Link (Call)
let isCall=1, hasDelaySlot=1 in {
//@JumpLink {
class JumpLink<bits<8> op, string instr_asm>:
FJ<op, (outs), (ins calltarget:$target, variable_ops),
!strconcat(instr_asm, "\t$target"), [(Cpu0JmpLink imm:$target)],
IIBranch> {
//#if CH >= CH10_1 2
let DecoderMethod = "DecodeJumpTarget";
//#endif
}
//@JumpLink }
class JumpLinkReg<bits<8> op, string instr_asm,
RegisterClass RC>:
FA<op, (outs), (ins RC:$rb, variable_ops),
!strconcat(instr_asm, "\t$rb"), [(Cpu0JmpLink RC:$rb)], IIBranch> {
let rc = 0;
let ra = 14;
let shamt = 0;
}
}
/// Jump & link and Return Instructions
let Predicates = [Ch9_1] in {
def JSUB : JumpLink<0x3b, "jsub">;
}
let Predicates = [Ch9_1] in {
def JALR : JumpLinkReg<0x39, "jalr", GPROut>;
}
let Predicates = [Ch9_1] in {
def : Pat<(Cpu0JmpLink (i32 tglobaladdr:$dst)),
(JSUB tglobaladdr:$dst)>;
def : Pat<(Cpu0JmpLink (i32 texternalsym:$dst)),
(JSUB texternalsym:$dst)>;
}
lbdex/chapters/Chapter9_1/Cpu0MCInstLower.cpp
MCOperand Cpu0MCInstLower::LowerSymbolOperand(const MachineOperand &MO,
MachineOperandType MOTy,
unsigned Offset) const {
MCSymbolRefExpr::VariantKind Kind = MCSymbolRefExpr::VK_None;
Cpu0MCExpr::Cpu0ExprKind TargetKind = Cpu0MCExpr::CEK_None;
const MCSymbol *Symbol;
switch(MO.getTargetFlags()) {
case Cpu0II::MO_GOT_CALL:
TargetKind = Cpu0MCExpr::CEK_GOT_CALL;
break;
...
}
switch (MOTy) {
. ...
case MachineOperand::MO_ExternalSymbol:
Symbol = AsmPrinter.GetExternalSymbolSymbol(MO.getSymbolName());
Offset += MO.getOffset();
break;
...
}
...
}
MCOperand Cpu0MCInstLower::LowerOperand(const MachineOperand& MO,
unsigned offset) const {
MachineOperandType MOTy = MO.getType();
switch (MOTy) {
//@2
case MachineOperand::MO_ExternalSymbol:
return LowerSymbolOperand(MO, MOTy, offset);
...
}
...
}
lbdex/chapters/Chapter9_1/MCTargetDesc/Cpu0AsmBackend.cpp
// Prepare value for the target space for it
static unsigned adjustFixupValue(const MCFixup &Fixup, uint64_t Value,
MCContext &Ctx) {
unsigned Kind = Fixup.getKind();
// Add/subtract and shift
switch (Kind) {
case Cpu0::fixup_Cpu0_CALL16:
...
}
...
}
lbdex/chapters/Chapter9_1/MCTargetDesc/Cpu0ELFObjectWriter.cpp
unsigned Cpu0ELFObjectWriter::getRelocType(MCContext &Ctx,
const MCValue &Target,
const MCFixup &Fixup,
bool IsPCRel) const {
// determine the type of the relocation
unsigned Type = (unsigned)ELF::R_CPU0_NONE;
unsigned Kind = (unsigned)Fixup.getKind();
switch (Kind) {
case Cpu0::fixup_Cpu0_CALL16:
Type = ELF::R_CPU0_CALL16;
break;
...
}
...
}
lbdex/chapters/Chapter9_1/MCTargetDesc/Cpu0FixupKinds.h
enum Fixups {
// resulting in - R_CPU0_CALL16.
fixup_Cpu0_CALL16,
...
. }
lbdex/chapters/Chapter9_1/MCTargetDesc/Cpu0MCCodeEmitter.cpp
unsigned Cpu0MCCodeEmitter::
getJumpTargetOpValue(const MCInst &MI, unsigned OpNo,
SmallVectorImpl<MCFixup> &Fixups,
const MCSubtargetInfo &STI) const {
if (Opcode == Cpu0::JSUB || Opcode == Cpu0::JMP || Opcode == Cpu0::BAL)
#elif CH >= CH8_2 //1
if (Opcode == Cpu0::JMP || Opcode == Cpu0::BAL)
Fixups.push_back(MCFixup::create(0, Expr,
MCFixupKind(Cpu0::fixup_Cpu0_PC24)));
...
}
unsigned Cpu0MCCodeEmitter::
getExprOpValue(const MCExpr *Expr,SmallVectorImpl<MCFixup> &Fixups,
const MCSubtargetInfo &STI) const {
// switch(cast<MCSymbolRefExpr>(Expr)->getKind()) {
case Cpu0MCExpr::CEK_GOT_CALL:
FixupKind = Cpu0::fixup_Cpu0_CALL16;
break;
...
}
...
}
lbdex/chapters/Chapter9_1/Cpu0MachineFunction.h
/// Cpu0FunctionInfo - This class is derived from MachineFunction private
/// Cpu0 target-specific information for each MachineFunction.
class Cpu0FunctionInfo : public MachineFunctionInfo {
public:
Cpu0FunctionInfo(MachineFunction& MF)
: MF(MF),
VarArgsFrameIndex(0),
InArgFIRange(std::make_pair(-1, 0)),
OutArgFIRange(std::make_pair(-1, 0)), GPFI(0), DynAllocFI(0),
bool isInArgFI(int FI) const {
return FI <= InArgFIRange.first && FI >= InArgFIRange.second;
}
void setLastInArgFI(int FI) { InArgFIRange.second = FI; }
bool isOutArgFI(int FI) const {
return FI <= OutArgFIRange.first && FI >= OutArgFIRange.second;
}
int getGPFI() const { return GPFI; }
void setGPFI(int FI) { GPFI = FI; }
bool isGPFI(int FI) const { return GPFI && GPFI == FI; }
bool isDynAllocFI(int FI) const { return DynAllocFI && DynAllocFI == FI; }
// Range of frame object indices.
// InArgFIRange: Range of indices of all frame objects created during call to
// LowerFormalArguments.
// OutArgFIRange: Range of indices of all frame objects created during call to
// LowerCall except for the frame object for restoring $gp.
std::pair<int, int> InArgFIRange, OutArgFIRange;
mutable int DynAllocFI; // Frame index of dynamically allocated stack area.
...
};
lbdex/chapters/Chapter9_1/Cpu0SEFrameLowering.h
bool spillCalleeSavedRegisters(MachineBasicBlock &MBB,
MachineBasicBlock::iterator MI,
ArrayRef<CalleeSavedInfo> CSI,
const TargetRegisterInfo *TRI) const override;
lbdex/chapters/Chapter9_1/Cpu0SEFrameLowering.cpp
bool Cpu0SEFrameLowering::
spillCalleeSavedRegisters(MachineBasicBlock &MBB,
MachineBasicBlock::iterator MI,
ArrayRef<CalleeSavedInfo> CSI,
const TargetRegisterInfo *TRI) const {
MachineFunction *MF = MBB.getParent();
MachineBasicBlock *EntryBlock = &MF->front();
const TargetInstrInfo &TII = *MF->getSubtarget().getInstrInfo();
for (unsigned i = 0, e = CSI.size(); i != e; ++i) {
// Add the callee-saved register as live-in. Do not add if the register is
// LR and return address is taken, because it has already been added in
// method Cpu0TargetLowering::LowerRETURNADDR.
// It's killed at the spill, unless the register is LR and return address
// is taken.
unsigned Reg = CSI[i].getReg();
bool IsRAAndRetAddrIsTaken = (Reg == Cpu0::LR)
&& MF->getFrameInfo().isReturnAddressTaken();
if (!IsRAAndRetAddrIsTaken)
EntryBlock->addLiveIn(Reg);
// Insert the spill to the stack frame.
bool IsKill = !IsRAAndRetAddrIsTaken;
const TargetRegisterClass *RC = TRI->getMinimalPhysRegClass(Reg);
TII.storeRegToStackSlot(*EntryBlock, MI, Reg, IsKill,
CSI[i].getFrameIdx(), RC, TRI);
}
return true;
}
Both JSUB and JALR, defined in Cpu0InstrInfo.td as shown above, use the Cpu0JmpLink node. They are distinguishable by their operand types: JSUB uses an imm (immediate) operand, while JALR uses a register operand.
lbdex/chapters/Chapter9_1/Cpu0InstrInfo.td
let Predicates = [Ch9_1] in {
def : Pat<(Cpu0JmpLink (i32 tglobaladdr:$dst)),
(JSUB tglobaladdr:$dst)>;
def : Pat<(Cpu0JmpLink (i32 texternalsym:$dst)),
(JSUB texternalsym:$dst)>;
The code instructs TableGen to generate pattern-matching logic that first matches the “imm” operand for the “tglobaladdr” pattern. If that match fails, it then attempts to match the “texternalsym” pattern.
A user-defined function belongs to the “tglobaladdr” category. For example, the function sum_i(…) defined in ch9_1.cpp falls under “tglobaladdr”.
On the other hand, functions implicitly used by LLVM, such as memcpy, belong to “texternalsym”. The memcpy function is typically generated when defining a long string. The file ch9_1_2.cpp is an example that triggers a call to memcpy. This will be shown in the next section with the Chapter9_2 example code.
The file Cpu0GenDAGISel.inc contains the pattern-matching information for JSUB and JALR, which is generated by TableGen as follows:
/*SwitchOpcode*/ 74, TARGET_VAL(Cpu0ISD::JmpLink),// ->734
/*660*/ OPC_RecordNode, // #0 = 'Cpu0JmpLink' chained node
/*661*/ OPC_CaptureGlueInput,
/*662*/ OPC_RecordChild1, // #1 = $target
/*663*/ OPC_Scope, 57, /*->722*/ // 2 children in Scope
/*665*/ OPC_MoveChild, 1,
/*667*/ OPC_SwitchOpcode /*3 cases */, 22, TARGET_VAL(ISD::Constant),
// ->693
/*671*/ OPC_MoveParent,
/*672*/ OPC_EmitMergeInputChains1_0,
/*673*/ OPC_EmitConvertToTarget, 1,
/*675*/ OPC_Scope, 7, /*->684*/ // 2 children in Scope
/*684*/ /*Scope*/ 7, /*->692*/
/*685*/ OPC_MorphNodeTo, TARGET_VAL(Cpu0::JSUB), 0|OPFL_Chain|
OPFL_GlueInput|OPFL_GlueOutput|OPFL_Variadic1,
0/*#VTs*/, 1/*#Ops*/, 2,
// Src: (Cpu0JmpLink (imm:iPTR):$target) - Complexity = 6
// Dst: (JSUB (imm:iPTR):$target)
/*692*/ 0, /*End of Scope*/
/*SwitchOpcode*/ 11, TARGET_VAL(ISD::TargetGlobalAddress),// ->707
/*696*/ OPC_CheckType, MVT::i32,
/*698*/ OPC_MoveParent,
/*699*/ OPC_EmitMergeInputChains1_0,
/*700*/ OPC_MorphNodeTo, TARGET_VAL(Cpu0::JSUB), 0|OPFL_Chain|
OPFL_GlueInput|OPFL_GlueOutput|OPFL_Variadic1,
0/*#VTs*/, 1/*#Ops*/, 1,
// Src: (Cpu0JmpLink (tglobaladdr:i32):$dst) - Complexity = 6
// Dst: (JSUB (tglobaladdr:i32):$dst)
/*SwitchOpcode*/ 11, TARGET_VAL(ISD::TargetExternalSymbol),// ->721
/*710*/ OPC_CheckType, MVT::i32,
/*712*/ OPC_MoveParent,
/*713*/ OPC_EmitMergeInputChains1_0,
/*714*/ OPC_MorphNodeTo, TARGET_VAL(Cpu0::JSUB), 0|OPFL_Chain|
OPFL_GlueInput|OPFL_GlueOutput|OPFL_Variadic1,
0/*#VTs*/, 1/*#Ops*/, 1,
// Src: (Cpu0JmpLink (texternalsym:i32):$dst) - Complexity = 6
// Dst: (JSUB (texternalsym:i32):$dst)
0, // EndSwitchOpcode
/*722*/ /*Scope*/ 10, /*->733*/
/*723*/ OPC_CheckChild1Type, MVT::i32,
/*725*/ OPC_EmitMergeInputChains1_0,
/*726*/ OPC_MorphNodeTo, TARGET_VAL(Cpu0::JALR), 0|OPFL_Chain|
OPFL_GlueInput|OPFL_GlueOutput|OPFL_Variadic1,
0/*#VTs*/, 1/*#Ops*/, 1,
// Src: (Cpu0JmpLink CPURegs:i32:$rb) - Complexity = 3
// Dst: (JALR CPURegs:i32:$rb)
/*733*/ 0, /*End of Scope*/
After applying the above changes, you can run Chapter9_1/ with ch9_1.cpp and observe the results as shown below:
118-165-79-83:input Jonathan$ /Users/Jonathan/llvm/test/
build/bin/llc -march=cpu0 -relocation-model=pic -filetype=asm
ch9_1.bc -o ch9_1.cpu0.s
Assertion failed: ((CLI.IsTailCall || InVals.size() == CLI.Ins.size()) &&
"LowerCall didn't emit the correct number of values!"), function LowerCallTo,
file /Users/Jonathan/llvm/test/llvm/lib/CodeGen/SelectionDAG/SelectionDAGBuilder.
cpp, ...
...
0. Program arguments: /Users/Jonathan/llvm/test/build/
bin/llc -march=cpu0 -relocation-model=pic -filetype=asm ch9_1.bc -o
ch9_1.cpu0.s
1. Running pass 'Function Pass Manager' on module 'ch9_1.bc'.
2. Running pass 'CPU0 DAG->DAG Pattern Instruction Selection' on function
'@main'
Illegal instruction: 4
Now, the LowerFormalArguments() has the correct number, but LowerCall() has not the correct number of values!
Store Outgoing Arguments to Stack Frame¶
Fig. 40 illustrates two steps involved in argument passing:
Storing outgoing arguments in the caller function.
Loading incoming arguments in the callee function.
In the previous section, we implemented LowerFormalArguments() to handle “loading incoming arguments” in the callee function.
Now, we will implement the part responsible for “storing outgoing arguments” in the caller function.
This task is handled by the LowerCall() function. Its implementation is shown below:
lbdex/chapters/Chapter9_2/Cpu0MachineFunction.h
/// Create a MachinePointerInfo that has an ExternalSymbolPseudoSourceValue
/// object representing a GOT entry for an external function.
MachinePointerInfo callPtrInfo(const char *ES);
/// Create a MachinePointerInfo that has a GlobalValuePseudoSourceValue object
/// representing a GOT entry for a global function.
MachinePointerInfo callPtrInfo(const GlobalValue *GV);
lbdex/chapters/Chapter9_2/Cpu0MachineFunction.cpp
MachinePointerInfo Cpu0FunctionInfo::callPtrInfo(const char *ES) {
return MachinePointerInfo(MF.getPSVManager().getExternalSymbolCallEntry(ES));
}
MachinePointerInfo Cpu0FunctionInfo::callPtrInfo(const GlobalValue *GV) {
return MachinePointerInfo(MF.getPSVManager().getGlobalValueCallEntry(GV));
}
lbdex/chapters/Chapter9_2/Cpu0ISelLowering.h
/// This function fills Ops, which is the list of operands that will later
/// be used when a function call node is created. It also generates
/// copyToReg nodes to set up argument registers.
virtual void
getOpndList(SmallVectorImpl<SDValue> &Ops,
std::deque< std::pair<unsigned, SDValue> > &RegsToPass,
bool IsPICCall, bool GlobalOrExternal, bool InternalLinkage,
CallLoweringInfo &CLI, SDValue Callee, SDValue Chain) const;
/// Cpu0CC - This class provides methods used to analyze formal and call
/// arguments and inquire about calling convention information.
class Cpu0CC {
void analyzeCallOperands(const SmallVectorImpl<ISD::OutputArg> &Outs,
bool IsVarArg, bool IsSoftFloat,
const SDNode *CallNode,
std::vector<ArgListEntry> &FuncArgs);
. };
Cpu0CC::SpecialCallingConvType getSpecialCallingConv(SDValue Callee) const;
// Lower Operand helpers
SDValue LowerCallResult(SDValue Chain, SDValue InFlag,
CallingConv::ID CallConv, bool isVarArg,
const SmallVectorImpl<ISD::InputArg> &Ins,
const SDLoc &dl, SelectionDAG &DAG,
SmallVectorImpl<SDValue> &InVals,
const SDNode *CallNode, const Type *RetTy) const;
/// passByValArg - Pass a byval argument in registers or on stack.
void passByValArg(SDValue Chain, const SDLoc &DL,
std::deque< std::pair<unsigned, SDValue> > &RegsToPass,
SmallVectorImpl<SDValue> &MemOpChains, SDValue StackPtr,
MachineFrameInfo &MFI, SelectionDAG &DAG, SDValue Arg,
const Cpu0CC &CC, const ByValArgInfo &ByVal,
const ISD::ArgFlagsTy &Flags, bool isLittle) const;
SDValue passArgOnStack(SDValue StackPtr, unsigned Offset, SDValue Chain,
SDValue Arg, const SDLoc &DL, bool IsTailCall,
SelectionDAG &DAG) const;
bool CanLowerReturn(CallingConv::ID CallConv, MachineFunction &MF,
bool isVarArg,
const SmallVectorImpl<ISD::OutputArg> &Outs,
LLVMContext &Context) const override;
lbdex/chapters/Chapter9_2/Cpu0ISelLowering.cpp
SDValue
Cpu0TargetLowering::passArgOnStack(SDValue StackPtr, unsigned Offset,
SDValue Chain, SDValue Arg, const SDLoc &DL,
bool IsTailCall, SelectionDAG &DAG) const {
if (!IsTailCall) {
SDValue PtrOff =
DAG.getNode(ISD::ADD, DL, getPointerTy(DAG.getDataLayout()), StackPtr,
DAG.getIntPtrConstant(Offset, DL));
return DAG.getStore(Chain, DL, Arg, PtrOff, MachinePointerInfo());
}
MachineFrameInfo &MFI = DAG.getMachineFunction().getFrameInfo();
int FI = MFI.CreateFixedObject(Arg.getValueSizeInBits() / 8, Offset, false);
SDValue FIN = DAG.getFrameIndex(FI, getPointerTy(DAG.getDataLayout()));
return DAG.getStore(Chain, DL, Arg, FIN, MachinePointerInfo(),
/* Alignment = */ 0, MachineMemOperand::MOVolatile);
}
void Cpu0TargetLowering::
getOpndList(SmallVectorImpl<SDValue> &Ops,
std::deque< std::pair<unsigned, SDValue> > &RegsToPass,
bool IsPICCall, bool GlobalOrExternal, bool InternalLinkage,
CallLoweringInfo &CLI, SDValue Callee, SDValue Chain) const {
// T9 should contain the address of the callee function if
// -reloction-model=pic or it is an indirect call.
if (IsPICCall || !GlobalOrExternal) {
unsigned T9Reg = Cpu0::T9;
RegsToPass.push_front(std::make_pair(T9Reg, Callee));
} else
Ops.push_back(Callee);
// Insert node "GP copy globalreg" before call to function.
//
// R_CPU0_CALL* operators (emitted when non-internal functions are called
// in PIC mode) allow symbols to be resolved via lazy binding.
// The lazy binding stub requires GP to point to the GOT.
if (IsPICCall && !InternalLinkage) {
unsigned GPReg = Cpu0::GP;
EVT Ty = MVT::i32;
RegsToPass.push_back(std::make_pair(GPReg, getGlobalReg(CLI.DAG, Ty)));
}
// Build a sequence of copy-to-reg nodes chained together with token
// chain and flag operands which copy the outgoing args into registers.
// The InFlag in necessary since all emitted instructions must be
// stuck together.
SDValue InFlag;
for (unsigned i = 0, e = RegsToPass.size(); i != e; ++i) {
Chain = CLI.DAG.getCopyToReg(Chain, CLI.DL, RegsToPass[i].first,
RegsToPass[i].second, InFlag);
InFlag = Chain.getValue(1);
}
// Add argument registers to the end of the list so that they are
// known live into the call.
for (unsigned i = 0, e = RegsToPass.size(); i != e; ++i)
Ops.push_back(CLI.DAG.getRegister(RegsToPass[i].first,
RegsToPass[i].second.getValueType()));
// Add a register mask operand representing the call-preserved registers.
const TargetRegisterInfo *TRI = Subtarget.getRegisterInfo();
const uint32_t *Mask =
TRI->getCallPreservedMask(CLI.DAG.getMachineFunction(), CLI.CallConv);
assert(Mask && "Missing call preserved mask for calling convention");
Ops.push_back(CLI.DAG.getRegisterMask(Mask));
if (InFlag.getNode())
Ops.push_back(InFlag);
}
/// LowerCall - functions arguments are copied from virtual regs to
/// (physical regs)/(stack frame), CALLSEQ_START and CALLSEQ_END are emitted.
SDValue
Cpu0TargetLowering::LowerCall(TargetLowering::CallLoweringInfo &CLI,
SmallVectorImpl<SDValue> &InVals) const {
SelectionDAG &DAG = CLI.DAG;
SDLoc DL = CLI.DL;
SmallVectorImpl<ISD::OutputArg> &Outs = CLI.Outs;
SmallVectorImpl<SDValue> &OutVals = CLI.OutVals;
SmallVectorImpl<ISD::InputArg> &Ins = CLI.Ins;
SDValue Chain = CLI.Chain;
SDValue Callee = CLI.Callee;
bool &IsTailCall = CLI.IsTailCall;
CallingConv::ID CallConv = CLI.CallConv;
bool IsVarArg = CLI.IsVarArg;
MachineFunction &MF = DAG.getMachineFunction();
MachineFrameInfo &MFI = MF.getFrameInfo();
const TargetFrameLowering *TFL = MF.getSubtarget().getFrameLowering();
Cpu0FunctionInfo *FuncInfo = MF.getInfo<Cpu0FunctionInfo>();
bool IsPIC = isPositionIndependent();
Cpu0FunctionInfo *Cpu0FI = MF.getInfo<Cpu0FunctionInfo>();
// Analyze operands of the call, assigning locations to each operand.
SmallVector<CCValAssign, 16> ArgLocs;
CCState CCInfo(CallConv, IsVarArg, DAG.getMachineFunction(),
ArgLocs, *DAG.getContext());
Cpu0CC::SpecialCallingConvType SpecialCallingConv =
getSpecialCallingConv(Callee);
Cpu0CC Cpu0CCInfo(CallConv, ABI.IsO32(),
CCInfo, SpecialCallingConv);
Cpu0CCInfo.analyzeCallOperands(Outs, IsVarArg,
Subtarget.abiUsesSoftFloat(),
Callee.getNode(), CLI.getArgs());
// Get a count of how many bytes are to be pushed on the stack.
unsigned NextStackOffset = CCInfo.getNextStackOffset();
//@TailCall 1 {
// Check if it's really possible to do a tail call.
if (IsTailCall)
IsTailCall =
isEligibleForTailCallOptimization(Cpu0CCInfo, NextStackOffset,
*MF.getInfo<Cpu0FunctionInfo>());
if (!IsTailCall && CLI.CB && CLI.CB->isMustTailCall())
report_fatal_error("failed to perform tail call elimination on a call "
"site marked musttail");
if (IsTailCall)
++NumTailCalls;
//@TailCall 1 }
// Chain is the output chain of the last Load/Store or CopyToReg node.
// ByValChain is the output chain of the last Memcpy node created for copying
// byval arguments to the stack.
unsigned StackAlignment = TFL->getStackAlignment();
NextStackOffset = alignTo(NextStackOffset, StackAlignment);
SDValue NextStackOffsetVal = DAG.getIntPtrConstant(NextStackOffset, DL, true);
//@TailCall 2 {
if (!IsTailCall)
Chain = DAG.getCALLSEQ_START(Chain, NextStackOffset, 0, DL);
//@TailCall 2 }
SDValue StackPtr =
DAG.getCopyFromReg(Chain, DL, Cpu0::SP,
getPointerTy(DAG.getDataLayout()));
// With EABI is it possible to have 16 args on registers.
std::deque< std::pair<unsigned, SDValue> > RegsToPass;
SmallVector<SDValue, 8> MemOpChains;
Cpu0CC::byval_iterator ByValArg = Cpu0CCInfo.byval_begin();
//@1 {
// Walk the register/memloc assignments, inserting copies/loads.
for (unsigned i = 0, e = ArgLocs.size(); i != e; ++i) {
//@1 }
SDValue Arg = OutVals[i];
CCValAssign &VA = ArgLocs[i];
MVT LocVT = VA.getLocVT();
ISD::ArgFlagsTy Flags = Outs[i].Flags;
//@ByVal Arg {
if (Flags.isByVal()) {
assert(Flags.getByValSize() &&
"ByVal args of size 0 should have been ignored by front-end.");
assert(ByValArg != Cpu0CCInfo.byval_end());
assert(!IsTailCall &&
"Do not tail-call optimize if there is a byval argument.");
passByValArg(Chain, DL, RegsToPass, MemOpChains, StackPtr, MFI, DAG, Arg,
Cpu0CCInfo, *ByValArg, Flags, Subtarget.isLittle());
++ByValArg;
continue;
}
//@ByVal Arg }
// Promote the value if needed.
switch (VA.getLocInfo()) {
default: llvm_unreachable("Unknown loc info!");
case CCValAssign::Full:
break;
case CCValAssign::SExt:
Arg = DAG.getNode(ISD::SIGN_EXTEND, DL, LocVT, Arg);
break;
case CCValAssign::ZExt:
Arg = DAG.getNode(ISD::ZERO_EXTEND, DL, LocVT, Arg);
break;
case CCValAssign::AExt:
Arg = DAG.getNode(ISD::ANY_EXTEND, DL, LocVT, Arg);
break;
}
// Arguments that can be passed on register must be kept at
// RegsToPass vector
if (VA.isRegLoc()) {
RegsToPass.push_back(std::make_pair(VA.getLocReg(), Arg));
continue;
}
// Register can't get to this point...
assert(VA.isMemLoc());
// emit ISD::STORE whichs stores the
// parameter value to a stack Location
MemOpChains.push_back(passArgOnStack(StackPtr, VA.getLocMemOffset(),
Chain, Arg, DL, IsTailCall, DAG));
}
// Transform all store nodes into one single node because all store
// nodes are independent of each other.
if (!MemOpChains.empty())
Chain = DAG.getNode(ISD::TokenFactor, DL, MVT::Other, MemOpChains);
// If the callee is a GlobalAddress/ExternalSymbol node (quite common, every
// direct call is) turn it into a TargetGlobalAddress/TargetExternalSymbol
// node so that legalize doesn't hack it.
bool IsPICCall = IsPIC; // true if calls are translated to
// jalr $t9
bool GlobalOrExternal = false, InternalLinkage = false;
EVT Ty = Callee.getValueType();
if (GlobalAddressSDNode *G = dyn_cast<GlobalAddressSDNode>(Callee)) {
if (IsPICCall) {
const GlobalValue *Val = G->getGlobal();
InternalLinkage = Val->hasInternalLinkage();
if (InternalLinkage)
Callee = getAddrLocal(G, Ty, DAG);
else
Callee = getAddrGlobal(G, Ty, DAG, Cpu0II::MO_GOT_CALL, Chain,
FuncInfo->callPtrInfo(Val));
} else
Callee = DAG.getTargetGlobalAddress(G->getGlobal(), DL,
getPointerTy(DAG.getDataLayout()), 0,
Cpu0II::MO_NO_FLAG);
GlobalOrExternal = true;
}
else if (ExternalSymbolSDNode *S = dyn_cast<ExternalSymbolSDNode>(Callee)) {
const char *Sym = S->getSymbol();
if (!IsPIC) // static
Callee = DAG.getTargetExternalSymbol(Sym,
getPointerTy(DAG.getDataLayout()),
Cpu0II::MO_NO_FLAG);
else // PIC
Callee = getAddrGlobal(S, Ty, DAG, Cpu0II::MO_GOT_CALL, Chain,
FuncInfo->callPtrInfo(Sym));
GlobalOrExternal = true;
}
SmallVector<SDValue, 8> Ops(1, Chain);
SDVTList NodeTys = DAG.getVTList(MVT::Other, MVT::Glue);
getOpndList(Ops, RegsToPass, IsPICCall, GlobalOrExternal, InternalLinkage,
CLI, Callee, Chain);
//@TailCall 3 {
if (IsTailCall)
return DAG.getNode(Cpu0ISD::TailCall, DL, MVT::Other, Ops);
//@TailCall 3 }
Chain = DAG.getNode(Cpu0ISD::JmpLink, DL, NodeTys, Ops);
SDValue InFlag = Chain.getValue(1);
// Create the CALLSEQ_END node.
Chain = DAG.getCALLSEQ_END(Chain, NextStackOffsetVal,
DAG.getIntPtrConstant(0, DL, true), InFlag, DL);
InFlag = Chain.getValue(1);
// Handle result values, copying them out of physregs into vregs that we
// return.
return LowerCallResult(Chain, InFlag, CallConv, IsVarArg,
Ins, DL, DAG, InVals, CLI.Callee.getNode(), CLI.RetTy);
}
/// LowerCallResult - Lower the result values of a call into the
/// appropriate copies out of appropriate physical registers.
SDValue
Cpu0TargetLowering::LowerCallResult(SDValue Chain, SDValue InFlag,
CallingConv::ID CallConv, bool IsVarArg,
const SmallVectorImpl<ISD::InputArg> &Ins,
const SDLoc &DL, SelectionDAG &DAG,
SmallVectorImpl<SDValue> &InVals,
const SDNode *CallNode,
const Type *RetTy) const {
// Assign locations to each value returned by this call.
SmallVector<CCValAssign, 16> RVLocs;
CCState CCInfo(CallConv, IsVarArg, DAG.getMachineFunction(),
RVLocs, *DAG.getContext());
Cpu0CC Cpu0CCInfo(CallConv, ABI.IsO32(), CCInfo);
Cpu0CCInfo.analyzeCallResult(Ins, Subtarget.abiUsesSoftFloat(),
CallNode, RetTy);
// Copy all of the result registers out of their specified physreg.
for (unsigned i = 0; i != RVLocs.size(); ++i) {
SDValue Val = DAG.getCopyFromReg(Chain, DL, RVLocs[i].getLocReg(),
RVLocs[i].getLocVT(), InFlag);
Chain = Val.getValue(1);
InFlag = Val.getValue(2);
if (RVLocs[i].getValVT() != RVLocs[i].getLocVT())
Val = DAG.getNode(ISD::BITCAST, DL, RVLocs[i].getValVT(), Val);
InVals.push_back(Val);
}
return Chain;
}
bool
Cpu0TargetLowering::CanLowerReturn(CallingConv::ID CallConv,
MachineFunction &MF, bool IsVarArg,
const SmallVectorImpl<ISD::OutputArg> &Outs,
LLVMContext &Context) const {
SmallVector<CCValAssign, 16> RVLocs;
CCState CCInfo(CallConv, IsVarArg, MF,
RVLocs, Context);
return CCInfo.CheckReturn(Outs, RetCC_Cpu0);
}
Cpu0TargetLowering::Cpu0CC::SpecialCallingConvType
Cpu0TargetLowering::getSpecialCallingConv(SDValue Callee) const {
Cpu0CC::SpecialCallingConvType SpecialCallingConv =
Cpu0CC::NoSpecialCallingConv;
return SpecialCallingConv;
}
void Cpu0TargetLowering::Cpu0CC::
analyzeCallOperands(const SmallVectorImpl<ISD::OutputArg> &Args,
bool IsVarArg, bool IsSoftFloat, const SDNode *CallNode,
std::vector<ArgListEntry> &FuncArgs) {
//@analyzeCallOperands body {
assert((CallConv != CallingConv::Fast || !IsVarArg) &&
"CallingConv::Fast shouldn't be used for vararg functions.");
unsigned NumOpnds = Args.size();
llvm::CCAssignFn *FixedFn = fixedArgFn();
//@3 {
for (unsigned I = 0; I != NumOpnds; ++I) {
//@3 }
MVT ArgVT = Args[I].VT;
ISD::ArgFlagsTy ArgFlags = Args[I].Flags;
bool R;
if (ArgFlags.isByVal()) {
handleByValArg(I, ArgVT, ArgVT, CCValAssign::Full, ArgFlags);
continue;
}
{
MVT RegVT = getRegVT(ArgVT, IsSoftFloat);
R = FixedFn(I, ArgVT, RegVT, CCValAssign::Full, ArgFlags, CCInfo);
}
if (R) {
#ifndef NDEBUG
dbgs() << "Call operand #" << I << " has unhandled type "
<< EVT(ArgVT).getEVTString();
#endif
llvm_unreachable(nullptr);
}
}
}
Just like loading incoming arguments from the stack frame, we call CCInfo(CallConv, …, ArgLocs, …) to obtain outgoing argument information before entering the “for loop”.
The loop structure is almost identical to that in LowerFormalArguments(), except that LowerCall() creates a “store DAG vector” instead of a “load DAG vector”.
After the “for loop”, it generates the instruction `ld $t9, %call16(_Z5sum_iiiiiii)($gp)` followed by jalr $t9 to call the subroutine (where $6 is $t9) in PIC (Position Independent Code) mode.
As with loading incoming arguments, we need to implement storeRegToStackSlot() in an earlier chapter to handle storing outgoing arguments.
Pseudo Hook Instructions ADJCALLSTACKDOWN and ADJCALLSTACKUP¶
DAG.getCALLSEQ_START() and DAG.getCALLSEQ_END() are invoked before and after the “for loop”, respectively. These insert CALLSEQ_START and CALLSEQ_END, which are later translated into the pseudo machine instructions ADJCALLSTACKDOWN and ADJCALLSTACKUP.
These pseudo instructions are defined in Cpu0InstrInfo.td as shown below:
lbdex/chapters/Chapter9_2/Cpu0InstrInfo.td
def SDT_Cpu0CallSeqStart : SDCallSeqStart<[SDTCisVT<0, i32>]>;
def SDT_Cpu0CallSeqEnd : SDCallSeqEnd<[SDTCisVT<0, i32>, SDTCisVT<1, i32>]>;
// These are target-independent nodes, but have target-specific formats.
def callseq_start : SDNode<"ISD::CALLSEQ_START", SDT_Cpu0CallSeqStart,
[SDNPHasChain, SDNPOutGlue]>;
def callseq_end : SDNode<"ISD::CALLSEQ_END", SDT_Cpu0CallSeqEnd,
[SDNPHasChain, SDNPOptInGlue, SDNPOutGlue]>;
//===----------------------------------------------------------------------===//
// Pseudo instructions
//===----------------------------------------------------------------------===//
let Predicates = [Ch9_2] in {
// As stack alignment is always done with addiu, we need a 16-bit immediate
let Defs = [SP], Uses = [SP] in {
def ADJCALLSTACKDOWN : Cpu0Pseudo<(outs), (ins uimm16:$amt1, uimm16:$amt2),
"!ADJCALLSTACKDOWN $amt1",
[(callseq_start timm:$amt1, timm:$amt2)]>;
def ADJCALLSTACKUP : Cpu0Pseudo<(outs), (ins uimm16:$amt1, uimm16:$amt2),
"!ADJCALLSTACKUP $amt1",
[(callseq_end timm:$amt1, timm:$amt2)]>;
}
//@def CPRESTORE {
// When handling PIC code the assembler needs .cpload and .cprestore
// directives. If the real instructions corresponding these directives
// are used, we have the same behavior, but get also a bunch of warnings
// from the assembler.
let hasSideEffects = 0 in
def CPRESTORE : Cpu0Pseudo<(outs), (ins i32imm:$loc, CPURegs:$gp),
".cprestore\t$loc", []>;
} // let Predicates = [Ch9_2]
With the definition below, eliminateCallFramePseudoInstr() will be called when LLVM encounters the pseudo instructions ADJCALLSTACKDOWN and ADJCALLSTACKUP.
This function simply discards these two pseudo instructions. LLVM will then automatically adjust the stack offset as needed.
lbdex/chapters/Chapter9_2/Cpu0InstrInfo.cpp
Cpu0InstrInfo::Cpu0InstrInfo(const Cpu0Subtarget &STI)
:
Cpu0GenInstrInfo(Cpu0::ADJCALLSTACKDOWN, Cpu0::ADJCALLSTACKUP),
lbdex/chapters/Chapter9_2/Cpu0FrameLowering.h
MachineBasicBlock::iterator
eliminateCallFramePseudoInstr(MachineFunction &MF,
MachineBasicBlock &MBB,
MachineBasicBlock::iterator I) const override;
lbdex/chapters/Chapter9_2/Cpu0FrameLowering.cpp
// Eliminate ADJCALLSTACKDOWN, ADJCALLSTACKUP pseudo instructions
MachineBasicBlock::iterator Cpu0FrameLowering::
eliminateCallFramePseudoInstr(MachineFunction &MF, MachineBasicBlock &MBB,
MachineBasicBlock::iterator I) const {
return MBB.erase(I);
}
Read LowerCall() with Graphviz’s Help¶
The complete DAGs created for outgoing arguments are shown in Fig. 43 for ch9_outgoing.cpp with cpu032I.
The LowerCall() function (excluding the call to LowerCallResult()) will generate the DAG nodes shown in Fig. 44 for ch9_outgoing.cpp with cpu032I.
The corresponding code for the DAG nodes Store and TargetGlobalAddress is listed in the figures. Users can match other DAG nodes to the LowerCall() function code accordingly.
By using the Graphviz tool with the llc option -view-dag-combine1-dags, you can design a small input in C or LLVM IR, then inspect the DAGs to better understand the behavior of LowerCall() and LowerFormalArguments().
In the later sub-sections, “Variable Arguments” and “Dynamic Stack Allocation Support”, you can create input examples that demonstrate these features. You can then use the DAGs to confirm your understanding of the logic in these two functions.
For more information about Graphviz, refer to the section “Display LLVM IR Nodes with Graphviz” in Chapter 4, Arithmetic and Logic Instructions.
The DAG diagrams can be generated using the llc option as shown below:
lbdex/input/ch9_outgoing.cpp
extern int sum_i(int x1);
int call_sum_i() {
return sum_i(1);
}
JonathantekiiMac:input Jonathan$ clang -O3 -target mips-unknown-linux-gnu -c
ch9_outgoing.cpp -emit-llvm -o ch9_outgoing.bc
JonathantekiiMac:input Jonathan$ /Users/Jonathan/llvm/test/build/
bin/llvm-dis ch9_outgoing.bc -o -
...
define i32 @_Z10call_sum_iv() #0 {
%1 = tail call i32 @_Z5sum_ii(i32 1)
ret i32 %1
}
JonathantekiiMac:input Jonathan$ /Users/Jonathan/llvm/test/build/
bin/llc -march=cpu0 -mcpu=cpu032I -view-dag-combine1-dags -relocation-
model=static -filetype=asm ch9_outgoing.bc -o -
.text
.section .mdebug.abiS32
.previous
.file "ch9_outgoing.bc"
Writing '/var/folders/rf/8bgdgt9d6vgf5sn8h8_zycd00000gn/T/dag._Z10call_sum_iv-
0dfaf1.dot'... done.
Running 'Graphviz' program...
![digraph "dag-combine1 input for _Z10call_sum_iv:" {
rankdir="BT";
// label="Figure Outgoing arguments DAG (A) created for ch9_outgoing.cpp with -cpu0-s32-calls=true";
subgraph cluster_0 {
fontcolor=red;
fontsize=24;
label = "LowerCall";
Node0x102f0d060 [shape=record,shape=Mrecord,label="{EntryToken|t0|{<d0>ch}}"];
Node0x10304f200 [shape=record,shape=Mrecord,label="{GlobalAddress\<i32 (i32)* @_Z5sum_ii\> 0|t1|{<d0>i32}}"];
Node0x10304f270 [shape=record,shape=Mrecord,label="{Constant\<1\>|t2|{<d0>i32}}"];
Node0x10304f2e0 [shape=record,shape=Mrecord,label="{TargetConstant\<8\>|t3|{<d0>i32}}"];
Node0x10304f350 [shape=record,shape=Mrecord,label="{{<s0>0|<s1>1}|callseq_start|t4|{<d0>ch|<d1>glue}}"];
Node0x10304f350:s0 -> Node0x102f0d060:d0[color=blue,style=dashed];
Node0x10304f350:s1 -> Node0x10304f2e0:d0;
Node0x10304f3c0 [shape=record,shape=Mrecord,label="{Register %SP|t5|{<d0>i32}}"];
Node0x10304f430 [shape=record,shape=Mrecord,label="{{<s0>0|<s1>1}|CopyFromReg|t6|{<d0>i32|<d1>ch}}"];
Node0x10304f430:s0 -> Node0x10304f350:d0[color=blue,style=dashed];
Node0x10304f430:s1 -> Node0x10304f3c0:d0;
Node0x10304f4a0 [shape=record,shape=Mrecord,label="{Constant\<0\>|t7|{<d0>i32}}"];
Node0x10304f510 [shape=record,shape=Mrecord,label="{undef|t8|{<d0>i32}}"];
Node0x10304f580 [shape=record,shape=Mrecord,label="{{<s0>0|<s1>1|<s2>2|<s3>3}|store\<ST4[\<unknown\>]\>|t9|{<d0>ch}}"];
Node0x10304f580:s0 -> Node0x10304f350:d0[color=blue,style=dashed];
Node0x10304f580:s1 -> Node0x10304f270:d0;
Node0x10304f580:s2 -> Node0x10304f430:d0;
Node0x10304f580:s3 -> Node0x10304f510:d0;
Node0x10304f5f0 [shape=record,shape=Mrecord,label="{TargetGlobalAddress\<i32 (i32)* @_Z5sum_ii\> 0|t10|{<d0>i32}}"];
Node0x10304f660 [shape=record,shape=Mrecord,label="{RegisterMask|t11|{<d0>Untyped}}"];
Node0x10304f6d0 [shape=record,shape=Mrecord,label="{{<s0>0|<s1>1|<s2>2}|Cpu0ISD::JmpLink|t12|{<d0>ch|<d1>glue}}"];
Node0x10304f6d0:s0 -> Node0x10304f580:d0[color=blue,style=dashed];
Node0x10304f6d0:s1 -> Node0x10304f5f0:d0;
Node0x10304f6d0:s2 -> Node0x10304f660:d0;
Node0x10304f740 [shape=record,shape=Mrecord,label="{TargetConstant\<0\>|t13|{<d0>i32}}"];
Node0x10304f7b0 [shape=record,shape=Mrecord,label="{{<s0>0|<s1>1|<s2>2|<s3>3}|callseq_end|t14|{<d0>ch|<d1>glue}}"];
Node0x10304f7b0:s0 -> Node0x10304f6d0:d0[color=blue,style=dashed];
Node0x10304f7b0:s1 -> Node0x10304f2e0:d0;
Node0x10304f7b0:s2 -> Node0x10304f740:d0;
Node0x10304f7b0:s3 -> Node0x10304f6d0:d1[color=red,style=bold];
}
subgraph cluster_1 {
fontcolor=red;
fontsize=24;
label = "LowerCallResult";
Node0x10304f820 [shape=record,shape=Mrecord,label="{Register %V0|t15|{<d0>i32}}"];
Node0x10304f890 [shape=record,shape=Mrecord,label="{{<s0>0|<s1>1|<s2>2}|CopyFromReg|t16|{<d0>i32|<d1>ch|<d2>glue}}"];
}
subgraph cluster_2 {
fontcolor=red;
fontsize=24;
label = "LowerReturn";
Node0x10304f900 [shape=record,shape=Mrecord,label="{{<s0>0|<s1>1|<s2>2}|CopyToReg|t17|{<d0>ch|<d1>glue}}"];
Node0x10304f970 [shape=record,shape=Mrecord,label="{{<s0>0|<s1>1|<s2>2}|Cpu0ISD::Ret|t18|{<d0>ch}}"];
}
Node0x10304f890:s0 -> Node0x10304f7b0:d0[color=blue,style=dashed];
Node0x10304f890:s1 -> Node0x10304f820:d0;
Node0x10304f890:s2 -> Node0x10304f7b0:d1[color=red,style=bold];
Node0x10304f900:s0 -> Node0x10304f890:d1[color=blue,style=dashed];
Node0x10304f900:s1 -> Node0x10304f820:d0;
Node0x10304f900:s2 -> Node0x10304f890:d0;
Node0x10304f970:s0 -> Node0x10304f900:d0[color=blue,style=dashed];
Node0x10304f970:s1 -> Node0x10304f820:d0;
Node0x10304f970:s2 -> Node0x10304f900:d1[color=red,style=bold];
Node0x0[ plaintext=circle, label ="GraphRoot"];
Node0x0 -> Node0x10304f970:d0[color=blue,style=dashed];
}](_images/graphviz-2ff535f052608d39fd4598743c0a09315e673459.png)
Fig. 43 Outgoing arguments DAG (A) created for ch9_outgoing.cpp with -cpu0-s32-calls=true¶
![digraph "isel input for _Z10call_sum_iv:" {
rankdir="BT";
// label="Figure Outgoing arguments DAG (B) created by LowerCall() for ch9_outgoing.cpp with -cpu0-s32-calls=true";
Node0x102f0d060 [shape=record,shape=Mrecord,label="{EntryToken|t0|{<d0>ch}}"];
Node0x10304f270 [shape=record,shape=Mrecord,label="{Constant\<1\>|t2|{<d0>i32}}"];
Node0x10304f2e0 [shape=record,shape=Mrecord,label="{TargetConstant\<8\>|t3|{<d0>i32}}"];
Node0x10304f350 [shape=record,shape=Mrecord,label="{{<s0>0|<s1>1}|callseq_start|t4|{<d0>ch|<d1>glue}}"];
Node0x10304f350:s0 -> Node0x102f0d060:d0[color=blue,style=dashed];
Node0x10304f350:s1 -> Node0x10304f2e0:d0;
Node0x10304f3c0 [shape=record,shape=Mrecord,label="{Register %SP|t5|{<d0>i32}}"];
Node0x10304f430 [shape=record,shape=Mrecord,label="{{<s0>0|<s1>1}|CopyFromReg|t6|{<d0>i32|<d1>ch}}"];
Node0x10304f430:s0 -> Node0x10304f350:d0[color=blue,style=dashed];
Node0x10304f430:s1 -> Node0x10304f3c0:d0;
Node0x10304f510 [shape=record,shape=Mrecord,label="{undef|t8|{<d0>i32}}"];
Node0x10304f580 [shape=record,shape=Mrecord,label="{{<s0>0|<s1>1|<s2>2|<s3>3}|store\<ST4[\<unknown\>]\>|t9|{<d0>ch}}"];
Node0x10304f580:s0 -> Node0x10304f350:d0[color=blue,style=dashed];
Node0x10304f580:s1 -> Node0x10304f270:d0;
Node0x10304f580:s2 -> Node0x10304f430:d0;
Node0x10304f580:s3 -> Node0x10304f510:d0;
Node0x10304f5f0 [shape=record,shape=Mrecord,label="{TargetGlobalAddress\<i32 (i32)* @_Z5sum_ii\> 0|t10|{<d0>i32}}"];
Node0x10304f660 [shape=record,shape=Mrecord,label="{RegisterMask|t11|{<d0>Untyped}}"];
Node0x10304f6d0 [shape=record,shape=Mrecord,label="{{<s0>0|<s1>1|<s2>2}|Cpu0ISD::JmpLink|t12|{<d0>ch|<d1>glue}}"];
Node0x10304f6d0:s0 -> Node0x10304f580:d0[color=blue,style=dashed];
Node0x10304f6d0:s1 -> Node0x10304f5f0:d0;
Node0x10304f6d0:s2 -> Node0x10304f660:d0;
Node0x10304f740 [shape=record,shape=Mrecord,label="{TargetConstant\<0\>|t13|{<d0>i32}}"];
Node0x10304f7b0 [shape=record,shape=Mrecord,label="{{<s0>0|<s1>1|<s2>2|<s3>3}|callseq_end|t14|{<d0>ch|<d1>glue}}"];
Node0x10304f7b0:s0 -> Node0x10304f6d0:d0[color=blue,style=dashed];
Node0x10304f7b0:s1 -> Node0x10304f2e0:d0;
Node0x10304f7b0:s2 -> Node0x10304f740:d0;
Node0x10304f7b0:s3 -> Node0x10304f6d0:d1[color=red,style=bold];
NodeComment1 [ penwidth = 1, fontname = "Courier New", shape = "note", label =<<table border="0" cellborder="0" cellpadding="3" bgcolor="gray">
<tr><td align="left">// Transform all store nodes into one single node because all store</td></tr>
<tr><td align="left" port="f1">// nodes are independent of each other.</td></tr>
<tr><td align="left" port="f2">if (!MemOpChains.empty())</td></tr>
<tr><td align="left" port="f3"> Chain = DAG.getNode(ISD::TokenFactor, DL, MVT::Other, MemOpChains);</td></tr>
<tr><td align="left"> ...</td></tr>
</table>> ];
NodeComment2 [ penwidth = 1, fontname = "Courier New", shape = "note", label =<<table border="0" cellborder="0" cellpadding="3" bgcolor="gray">
<tr><td align="left">if (!IsPIC) // static</td></tr>
<tr><td align="left" port="f1"> Callee = DAG.getTargetExternalSymbol(Sym,</td></tr>
<tr><td align="left" port="f2"> getPointerTy(DAG.getDataLayout()),</td></tr>
<tr><td align="left" port="f3"> Cpu0II::MO_NO_FLAG);</td></tr>
<tr><td align="left"> ...</td></tr>
</table>> ];
Node0x10304f580 -> NodeComment1[color=black,style=dashed];
NodeComment2:n -> Node0x10304f6d0:e[color=black,style=dashed];
}](_images/graphviz-1278f18ff1ad05a8af2e93b2e3df50121888a5df.png)
Fig. 44 Outgoing arguments DAG (B) created by LowerCall() for ch9_outgoing.cpp with -cpu0-s32-calls=true¶
As mentioned in the previous section, the option llc -cpu0-s32-calls=true
uses the S32 calling convention, which passes all arguments in registers.
In contrast, the option llc -cpu0-s32-calls=false uses the O32 convention,
which passes the first two arguments in registers and the remaining arguments
on the stack.
The resulting behavior is shown as follows:
118-165-78-230:input Jonathan$ /Users/Jonathan/llvm/test/build/
bin/llc -march=cpu0 -mcpu=cpu032I -cpu0-s32-calls=true
-relocation-model=pic -filetype=asm ch9_1.bc -o -
.text
.section .mdebug.abiS32
.previous
.file "ch9_1.bc"
.globl _Z5sum_iiiiiii
.align 2
.type _Z5sum_iiiiiii,@function
.ent _Z5sum_iiiiiii # @_Z5sum_iiiiiii
_Z5sum_iiiiiii:
.frame $fp,32,$lr
.mask 0x00000000,0
.set noreorder
.cpload $t9
.set nomacro
# BB#0:
addiu $sp, $sp, -32
ld $2, 52($sp)
ld $3, 48($sp)
ld $4, 44($sp)
ld $5, 40($sp)
ld $t9, 36($sp)
ld $7, 32($sp)
st $7, 28($sp)
st $t9, 24($sp)
st $5, 20($sp)
st $4, 16($sp)
st $3, 12($sp)
lui $3, %got_hi(gI)
addu $3, $3, $gp
st $2, 8($sp)
ld $3, %got_lo(gI)($3)
ld $3, 0($3)
ld $4, 28($sp)
addu $3, $3, $4
ld $4, 24($sp)
addu $3, $3, $4
ld $4, 20($sp)
addu $3, $3, $4
ld $4, 16($sp)
addu $3, $3, $4
ld $4, 12($sp)
addu $3, $3, $4
addu $2, $3, $2
st $2, 4($sp)
addiu $sp, $sp, 32
ret $lr
nop
.set macro
.set reorder
.end _Z5sum_iiiiiii
$tmp0:
.size _Z5sum_iiiiiii, ($tmp0)-_Z5sum_iiiiiii
.globl main
.align 2
.type main,@function
.ent main # @main
main:
.frame $fp,40,$lr
.mask 0x00004000,-4
.set noreorder
.cpload $t9
.set nomacro
# BB#0:
addiu $sp, $sp, -40
st $lr, 36($sp) # 4-byte Folded Spill
addiu $2, $zero, 0
st $2, 32($sp)
addiu $2, $zero, 6
st $2, 20($sp)
addiu $2, $zero, 5
st $2, 16($sp)
addiu $2, $zero, 4
st $2, 12($sp)
addiu $2, $zero, 3
st $2, 8($sp)
addiu $2, $zero, 2
st $2, 4($sp)
addiu $2, $zero, 1
st $2, 0($sp)
ld $t9, %call16(_Z5sum_iiiiiii)($gp)
jalr $t9
nop
st $2, 28($sp)
ld $lr, 36($sp) # 4-byte Folded Reload
addiu $sp, $sp, 40
ret $lr
nop
.set macro
.set reorder
.end main
$tmp1:
.size main, ($tmp1)-main
.type gI,@object # @gI
.data
.globl gI
.align 2
gI:
.4byte 100 # 0x64
.size gI, 4
118-165-78-230:input Jonathan$ /Users/Jonathan/llvm/test/build/
bin/llc -march=cpu0 -mcpu=cpu032II -cpu0-s32-calls=false
-relocation-model=pic -filetype=asm ch9_1.bc -o -
...
.globl main
.align 2
.type main,@function
.ent main # @main
main:
.frame $fp,40,$lr
.mask 0x00004000,-4
.set noreorder
.cpload $t9
.set nomacro
# BB#0:
addiu $sp, $sp, -40
st $lr, 36($sp) # 4-byte Folded Spill
addiu $2, $zero, 0
st $2, 32($sp)
addiu $2, $zero, 6
st $2, 20($sp)
addiu $2, $zero, 5
st $2, 16($sp)
addiu $2, $zero, 4
st $2, 12($sp)
addiu $2, $zero, 3
st $2, 8($sp)
ld $t9, %call16(_Z5sum_iiiiiii)($gp)
addiu $4, $zero, 1
addiu $5, $zero, 2
jalr $t9
nop
st $2, 28($sp)
ld $lr, 36($sp) # 4-byte Folded Reload
addiu $sp, $sp, 40
ret $lr
nop
.set macro
.set reorder
.end main
Long and Short String Initialization¶
In the previous section, we mentioned the JSUB texternalsym pattern.
Run Chapter9_2 with ch9_1_2.cpp to observe the following results:
For a long string, LLVM generates a call to memcpy() to initialize the string—for example, char str[81] = “Hello world”.
For a short string, the call memcpy is optimized and translated into a direct store with a constant value during the optimization stages.
lbdex/input/ch9_1_2.cpp
int main()
{
char str[81] = "Hello world";
char s[6] = "Hello";
return 0;
}
JonathantekiiMac:input Jonathan$ llvm-dis ch9_1_2.bc -o -
; ModuleID = 'ch9_1_2.bc'
...
@_ZZ4mainE3str = private unnamed_addr constant [81 x i8] c"Hello world\00\00\00\
00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00
\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\0
0\00\00\00\00\00\00\00\00\00\00\00\00\00", align 1
@_ZZ4mainE1s = private unnamed_addr constant [6 x i8] c"Hello\00", align 1
; Function Attrs: nounwind
define i32 @main() #0 {
entry:
%retval = alloca i32, align 4
%str = alloca [81 x i8], align 1
store i32 0, i32* %retval
%0 = bitcast [81 x i8]* %str to i8*
call void @llvm.memcpy.p0i8.p0i8.i32(i8* %0, i8* getelementptr inbounds
([81 x i8]* @_ZZ4mainE3str, i32 0, i32 0), i32 81, i32 1, i1 false)
%1 = bitcast [6 x i8]* %s to i8*
call void @llvm.memcpy.p0i8.p0i8.i32(i8* %1, i8* getelementptr inbounds
([6 x i8]* @_ZZ4mainE1s, i32 0, i32 0), i32 6, i32 1, i1 false)
ret i32 0
}
JonathantekiiMac:input Jonathan$ clang -target mips-unknown-linux-gnu -c
ch9_1_2.cpp -emit-llvm -o ch9_1_2.bc
JonathantekiiMac:input Jonathan$ /Users/Jonathan/llvm/test/build
/bin/llc -march=cpu0 -mcpu=cpu032II -cpu0-s32-calls=true
-relocation-model=static -filetype=asm ch9_1_2.bc -o -
.section .mdebug.abi32
...
lui $2, %hi($_ZZ4mainE3str)
ori $2, $2, %lo($_ZZ4mainE3str)
st $2, 4($sp)
addiu $2, $sp, 24
st $2, 0($sp)
jsub memcpy
nop
lui $2, %hi($_ZZ4mainE1s)
ori $2, $2, %lo($_ZZ4mainE1s)
lbu $3, 4($2)
shl $3, $3, 8
lbu $4, 5($2)
or $3, $3, $4
sh $3, 20($sp)
lbu $3, 2($2)
shl $3, $3, 8
lbu $4, 3($2)
or $3, $3, $4
lbu $4, 1($2)
lbu $2, 0($2)
shl $2, $2, 8
or $2, $2, $4
shl $2, $2, 16
or $2, $2, $3
st $2, 16($sp)
...
.type $_ZZ4mainE3str,@object # @_ZZ4mainE3str
.section .rodata,"a",@progbits
$_ZZ4mainE3str:
.asciz "Hello world\000\000\000\000\000\000\000\000\000\000\000\000\000\000
\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000
\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000
\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000"
.size $_ZZ4mainE3str, 81
.type $_ZZ4mainE1s,@object # @_ZZ4mainE1s
.section .rodata.str1.1,"aMS",@progbits,1
$_ZZ4mainE1s:
.asciz "Hello"
.size $_ZZ4mainE1s, 6
The call memcpy for a short string is optimized by LLVM before the “DAG-to-DAG Pattern Instruction Selection” stage.
It is translated into a store with a constant value, as shown below:
JonathantekiiMac:input Jonathan$ /Users/Jonathan/llvm/test/build
/bin/llc -march=cpu0 -mcpu=cpu032II -cpu0-s32-calls=true
-relocation-model=static -filetype=asm ch9_1_2.bc -debug -o -
Initial selection DAG: BB#0 'main:entry'
SelectionDAG has 35 nodes:
...
0x7fd909030810: <multiple use>
0x7fd909030c10: i32 = Constant<1214606444> // 1214606444=0x48656c6c="Hell"
0x7fd909030910: <multiple use>
0x7fd90902d810: <multiple use>
0x7fd909030d10: ch = store 0x7fd909030810, 0x7fd909030c10, 0x7fd909030910,
0x7fd90902d810<ST4[%1]>
0x7fd909030810: <multiple use>
0x7fd909030e10: i16 = Constant<28416> // 28416=0x6f00="o\0"
...
0x7fd90902d810: <multiple use>
0x7fd909031210: ch = store 0x7fd909030810, 0x7fd909030e10, 0x7fd909031010,
0x7fd90902d810<ST2[%1+4](align=4)>
...
The incoming arguments refer to the formal arguments as defined in compiler and programming language literature. The outgoing arguments refer to the actual arguments passed during a function call.
Summary as Table: Callee incoming arguments and caller outgoing arguments.
Description |
Callee |
Caller |
|---|---|---|
Charged Function |
LowerFormalArguments() |
LowerCall() |
Charged Function Created |
Create load vectors for incoming arguments |
Create store vectors for outgoing arguments |
Structure Type Support¶
Ordinary Struct Type¶
The following code in Chapter9_1/ and Chapter3_4/ supports ordinary structure types in function calls.
lbdex/chapters/Chapter9_1/Cpu0ISelLowering.cpp
/// LowerFormalArguments - transform physical registers into virtual registers
/// and generate load operations for arguments places on the stack.
SDValue
Cpu0TargetLowering::LowerFormalArguments(SDValue Chain,
CallingConv::ID CallConv,
bool IsVarArg,
const SmallVectorImpl<ISD::InputArg> &Ins,
const SDLoc &DL, SelectionDAG &DAG,
SmallVectorImpl<SDValue> &InVals)
const {
for (unsigned i = 0, e = ArgLocs.size(); i != e; ++i) {
// The cpu0 ABIs for returning structs by value requires that we copy
// the sret argument into $v0 for the return. Save the argument into
// a virtual register so that we can access it from the return points.
if (Ins[i].Flags.isSRet()) {
unsigned Reg = Cpu0FI->getSRetReturnReg();
if (!Reg) {
Reg = MF.getRegInfo().createVirtualRegister(
getRegClassFor(MVT::i32));
Cpu0FI->setSRetReturnReg(Reg);
}
SDValue Copy = DAG.getCopyToReg(DAG.getEntryNode(), DL, Reg, InVals[i]);
Chain = DAG.getNode(ISD::TokenFactor, DL, MVT::Other, Copy, Chain);
break;
}
}
}
SDValue
Cpu0TargetLowering::LowerReturn(SDValue Chain,
CallingConv::ID CallConv, bool IsVarArg,
const SmallVectorImpl<ISD::OutputArg> &Outs,
const SmallVectorImpl<SDValue> &OutVals,
const SDLoc &DL, SelectionDAG &DAG) const {
// The cpu0 ABIs for returning structs by value requires that we copy
// the sret argument into $v0 for the return. We saved the argument into
// a virtual register in the entry block, so now we copy the value out
// and into $v0.
if (MF.getFunction().hasStructRetAttr()) {
Cpu0FunctionInfo *Cpu0FI = MF.getInfo<Cpu0FunctionInfo>();
unsigned Reg = Cpu0FI->getSRetReturnReg();
if (!Reg)
llvm_unreachable("sret virtual register not created in the entry block");
SDValue Val =
DAG.getCopyFromReg(Chain, DL, Reg, getPointerTy(DAG.getDataLayout()));
unsigned V0 = Cpu0::V0;
Chain = DAG.getCopyToReg(Chain, DL, V0, Val, Flag);
Flag = Chain.getValue(1);
RetOps.push_back(DAG.getRegister(V0, getPointerTy(DAG.getDataLayout())));
}
}
In addition to the code above, we defined the calling convention in an earlier chapter as follows:
lbdex/chapters/Chapter3_4/Cpu0CallingConv.td
def RetCC_Cpu0EABI : CallingConv<[
// i32 are returned in registers V0, V1, A0, A1
CCIfType<[i32], CCAssignToReg<[V0, V1, A0, A1]>>
]>;
This means that for the return value, we store it in registers V0, V1, A0, and A1 if the size of the return value does not exceed four registers.
If it exceeds four registers, Cpu0 will store the value in memory and return a pointer to that memory in a register.
For demonstration, let’s run Chapter9_2/ with ch9_1_struct.cpp and explain using this example.
lbdex/input/ch9_1_struct.cpp
extern "C" int printf(const char *format, ...);
struct Date
{
int year;
int month;
int day;
int hour;
int minute;
int second;
};
static Date gDate = {2012, 10, 12, 1, 2, 3};
struct Time
{
int hour;
int minute;
int second;
};
static Time gTime = {2, 20, 30};
static Date getDate()
{
return gDate;
}
static Date copyDate(Date date)
{
return date;
}
static Date copyDate(Date* date)
{
return *date;
}
static Time copyTime(Time time)
{
return time;
}
static Time copyTime(Time* time)
{
return *time;
}
int test_func_arg_struct()
{
Time time1 = {1, 10, 12};
Date date1 = getDate();
Date date2 = copyDate(date1);
Date date3 = copyDate(&date1);
Time time2 = copyTime(time1);
Time time3 = copyTime(&time1);
if (!(date1.year == 2012 && date1.month == 10 && date1.day == 12 && date1.hour
== 1 && date1.minute == 2 && date1.second == 3))
return 1;
if (!(date2.year == 2012 && date2.month == 10 && date2.day == 12 && date2.hour
== 1 && date2.minute == 2 && date2.second == 3))
return 1;
if (!(time2.hour == 1 && time2.minute == 10 && time2.second == 12))
return 1;
if (!(time3.hour == 1 && time3.minute == 10 && time3.second == 12))
return 1;
#ifdef PRINT_TEST
printf("date1 = %d %d %d %d %d %d", date1.year, date1.month, date1.day,
date1.hour, date1.minute, date1.second); // date1 = 2012 10 12 1 2 3
if (date1.year == 2012 && date1.month == 10 && date1.day == 12 && date1.hour
== 1 && date1.minute == 2 && date1.second == 3)
printf(", PASS\n");
else
printf(", FAIL\n");
printf("date2 = %d %d %d %d %d %d", date2.year, date2.month, date2.day,
date2.hour, date2.minute, date2.second); // date2 = 2012 10 12 1 2 3
if (date2.year == 2012 && date2.month == 10 && date2.day == 12 && date2.hour
== 1 && date2.minute == 2 && date2.second == 3)
printf(", PASS\n");
else
printf(", FAIL\n");
// time2 = 1 10 12
printf("time2 = %d %d %d", time2.hour, time2.minute, time2.second);
if (time2.hour == 1 && time2.minute == 10 && time2.second == 12)
printf(", PASS\n");
else
printf(", FAIL\n");
// time3 = 1 10 12
printf("time3 = %d %d %d", time3.hour, time3.minute, time3.second);
if (time3.hour == 1 && time3.minute == 10 && time3.second == 12)
printf(", PASS\n");
else
printf(", FAIL\n");
#endif
return 0;
}
JonathantekiiMac:input Jonathan$ /Users/Jonathan/llvm/test/build/
bin/llc -march=cpu0 -mcpu=cpu032I -relocation-model=pic -filetype=asm
ch9_1_struct.bc -o -
.section .mdebug.abi32
.previous
.file "ch9_1_struct.bc"
.text
.globl _Z7getDatev
.align 2
.type _Z7getDatev,@function
.ent _Z7getDatev # @_Z7getDatev
_Z7getDatev:
.cfi_startproc
.frame $sp,0,$lr
.mask 0x00000000,0
.set noreorder
.cpload $t9
.set nomacro
# BB#0:
lui $2, %got_hi(gDate)
addu $2, $2, $gp
ld $3, %got_lo(gDate)($2)
ld $2, 0($sp)
ld $4, 20($3) // save gDate contents to 212..192($sp)
st $4, 20($2)
ld $4, 16($3)
st $4, 16($2)
ld $4, 12($3)
st $4, 12($2)
ld $4, 8($3)
st $4, 8($2)
ld $4, 4($3)
st $4, 4($2)
ld $3, 0($3)
st $3, 0($2)
ret $lr
nop
.set macro
.set reorder
.end _Z7getDatev
$tmp0:
.size _Z7getDatev, ($tmp0)-_Z7getDatev
.cfi_endproc
...
.globl _Z20test_func_arg_structv
.align 2
.type _Z20test_func_arg_structv,@function
.ent _Z20test_func_arg_structv # @main
_Z20test_func_arg_structv:
.cfi_startproc
.frame $sp,248,$lr
.mask 0x00004180,-4
.set noreorder
.cpload $t9
.set nomacro
# BB#0:
addiu $sp, $sp, -200
st $lr, 196($sp) # 4-byte Folded Spill
st $8, 192($sp) # 4-byte Folded Spill
ld $2, %got($_ZZ20test_func_arg_structvE5time1)($gp)
ori $2, $2, %lo($_ZZ20test_func_arg_structvE5time1)
ld $3, 8($2)
st $3, 184($sp)
ld $3, 4($2)
st $3, 180($sp)
ld $2, 0($2)
st $2, 176($sp)
addiu $8, $sp, 152
st $8, 0($sp)
ld $t9, %call16(_Z7getDatev)($gp) // copy gDate contents to date1, 176..152($sp)
jalr $t9
nop
ld $gp, 176($sp)
ld $2, 172($sp)
st $2, 124($sp)
ld $2, 168($sp)
st $2, 120($sp)
ld $2, 164($sp)
st $2, 116($sp)
ld $2, 160($sp)
st $2, 112($sp)
ld $2, 156($sp)
st $2, 108($sp)
ld $2, 152($sp)
st $2, 104($sp)
...
The ch9_1_constructor.cpp includes an implementation of the C++ class Date.
This can also be translated by the Cpu0 backend, since the frontend (Clang, in this case) translates C++ classes into equivalent C language constructs.
If you comment out the if hasStructRetAttr() part in both of the functions mentioned above, the output Cpu0 code for ch9_1_struct.cpp will use register $3 instead of $2 as the return register, as shown below:
.text
.section .mdebug.abiS32
.previous
.file "ch9_1_struct.bc"
.globl _Z7getDatev
.align 2
.type _Z7getDatev,@function
.ent _Z7getDatev # @_Z7getDatev
_Z7getDatev:
.frame $fp,0,$lr
.mask 0x00000000,0
.set noreorder
.cpload $t9
.set nomacro
# BB#0:
lui $2, %got_hi(gDate)
addu $2, $2, $gp
ld $2, %got_lo(gDate)($2)
ld $3, 0($sp)
ld $4, 20($2)
st $4, 20($3)
ld $4, 16($2)
st $4, 16($3)
ld $4, 12($2)
st $4, 12($3)
ld $4, 8($2)
st $4, 8($3)
ld $4, 4($2)
st $4, 4($3)
ld $2, 0($2)
st $2, 0($3)
ret $lr
nop
...
According to the MIPS ABI, the address for returning a struct variable must be placed in register $2.
Byval Struct Type¶
The following code in Chapter9_1/ and Chapter9_2/ supports the byval structure type in function calls.
lbdex/chapters/Chapter9_1/Cpu0ISelLowering.cpp
void Cpu0TargetLowering::
copyByValRegs(SDValue Chain, const SDLoc &DL, std::vector<SDValue> &OutChains,
SelectionDAG &DAG, const ISD::ArgFlagsTy &Flags,
SmallVectorImpl<SDValue> &InVals, const Argument *FuncArg,
const Cpu0CC &CC, const ByValArgInfo &ByVal) const {
MachineFunction &MF = DAG.getMachineFunction();
MachineFrameInfo &MFI = MF.getFrameInfo();
unsigned RegAreaSize = ByVal.NumRegs * CC.regSize();
unsigned FrameObjSize = std::max(Flags.getByValSize(), RegAreaSize);
int FrameObjOffset;
const ArrayRef<MCPhysReg> ByValArgRegs = CC.intArgRegs();
if (RegAreaSize)
FrameObjOffset = (int)CC.reservedArgArea() -
(int)((CC.numIntArgRegs() - ByVal.FirstIdx) * CC.regSize());
else
FrameObjOffset = ByVal.Address;
// Create frame object.
EVT PtrTy = getPointerTy(DAG.getDataLayout());
int FI = MFI.CreateFixedObject(FrameObjSize, FrameObjOffset, true);
SDValue FIN = DAG.getFrameIndex(FI, PtrTy);
InVals.push_back(FIN);
if (!ByVal.NumRegs)
return;
// Copy arg registers.
MVT RegTy = MVT::getIntegerVT(CC.regSize() * 8);
const TargetRegisterClass *RC = getRegClassFor(RegTy);
for (unsigned I = 0; I < ByVal.NumRegs; ++I) {
unsigned ArgReg = ByValArgRegs[ByVal.FirstIdx + I];
unsigned VReg = addLiveIn(MF, ArgReg, RC);
unsigned Offset = I * CC.regSize();
SDValue StorePtr = DAG.getNode(ISD::ADD, DL, PtrTy, FIN,
DAG.getConstant(Offset, DL, PtrTy));
SDValue Store = DAG.getStore(Chain, DL, DAG.getRegister(VReg, RegTy),
StorePtr, MachinePointerInfo(FuncArg, Offset));
OutChains.push_back(Store);
}
}
/// LowerFormalArguments - transform physical registers into virtual registers
/// and generate load operations for arguments places on the stack.
SDValue
Cpu0TargetLowering::LowerFormalArguments(SDValue Chain,
CallingConv::ID CallConv,
bool IsVarArg,
const SmallVectorImpl<ISD::InputArg> &Ins,
const SDLoc &DL, SelectionDAG &DAG,
SmallVectorImpl<SDValue> &InVals)
const {
for (unsigned i = 0, e = ArgLocs.size(); i != e; ++i) {
if (Flags.isByVal()) {
assert(Flags.getByValSize() &&
"ByVal args of size 0 should have been ignored by front-end.");
assert(ByValArg != Cpu0CCInfo.byval_end());
copyByValRegs(Chain, DL, OutChains, DAG, Flags, InVals, &*FuncArg,
Cpu0CCInfo, *ByValArg);
++ByValArg;
continue;
}
...
. }
for (unsigned i = 0, e = ArgLocs.size(); i != e; ++i) {
// The cpu0 ABIs for returning structs by value requires that we copy
// the sret argument into $v0 for the return. Save the argument into
// a virtual register so that we can access it from the return points.
if (Ins[i].Flags.isSRet()) {
unsigned Reg = Cpu0FI->getSRetReturnReg();
if (!Reg) {
Reg = MF.getRegInfo().createVirtualRegister(
getRegClassFor(MVT::i32));
Cpu0FI->setSRetReturnReg(Reg);
}
SDValue Copy = DAG.getCopyToReg(DAG.getEntryNode(), DL, Reg, InVals[i]);
Chain = DAG.getNode(ISD::TokenFactor, DL, MVT::Other, Copy, Chain);
break;
}
}
...
}
lbdex/chapters/Chapter9_2/Cpu0ISelLowering.cpp
// Copy byVal arg to registers and stack.
void Cpu0TargetLowering::
passByValArg(SDValue Chain, const SDLoc &DL,
std::deque< std::pair<unsigned, SDValue> > &RegsToPass,
SmallVectorImpl<SDValue> &MemOpChains, SDValue StackPtr,
MachineFrameInfo &MFI, SelectionDAG &DAG, SDValue Arg,
const Cpu0CC &CC, const ByValArgInfo &ByVal,
const ISD::ArgFlagsTy &Flags, bool isLittle) const {
unsigned ByValSizeInBytes = Flags.getByValSize();
unsigned OffsetInBytes = 0; // From beginning of struct
unsigned RegSizeInBytes = CC.regSize();
unsigned Alignment = std::min((unsigned)Flags.getNonZeroByValAlign().value(), RegSizeInBytes);
EVT PtrTy = getPointerTy(DAG.getDataLayout()),
RegTy = MVT::getIntegerVT(RegSizeInBytes * 8);
if (ByVal.NumRegs) {
const ArrayRef<MCPhysReg> ArgRegs = CC.intArgRegs();
bool LeftoverBytes = (ByVal.NumRegs * RegSizeInBytes > ByValSizeInBytes);
unsigned I = 0;
// Copy words to registers.
for (; I < ByVal.NumRegs - LeftoverBytes;
++I, OffsetInBytes += RegSizeInBytes) {
SDValue LoadPtr = DAG.getNode(ISD::ADD, DL, PtrTy, Arg,
DAG.getConstant(OffsetInBytes, DL, PtrTy));
SDValue LoadVal = DAG.getLoad(RegTy, DL, Chain, LoadPtr,
MachinePointerInfo());
MemOpChains.push_back(LoadVal.getValue(1));
unsigned ArgReg = ArgRegs[ByVal.FirstIdx + I];
RegsToPass.push_back(std::make_pair(ArgReg, LoadVal));
}
// Return if the struct has been fully copied.
if (ByValSizeInBytes == OffsetInBytes)
return;
// Copy the remainder of the byval argument with sub-word loads and shifts.
if (LeftoverBytes) {
assert((ByValSizeInBytes > OffsetInBytes) &&
(ByValSizeInBytes < OffsetInBytes + RegSizeInBytes) &&
"Size of the remainder should be smaller than RegSizeInBytes.");
SDValue Val;
for (unsigned LoadSizeInBytes = RegSizeInBytes / 2, TotalBytesLoaded = 0;
OffsetInBytes < ByValSizeInBytes; LoadSizeInBytes /= 2) {
unsigned RemainingSizeInBytes = ByValSizeInBytes - OffsetInBytes;
if (RemainingSizeInBytes < LoadSizeInBytes)
continue;
// Load subword.
SDValue LoadPtr = DAG.getNode(ISD::ADD, DL, PtrTy, Arg,
DAG.getConstant(OffsetInBytes, DL, PtrTy));
SDValue LoadVal = DAG.getExtLoad(
ISD::ZEXTLOAD, DL, RegTy, Chain, LoadPtr, MachinePointerInfo(),
MVT::getIntegerVT(LoadSizeInBytes * 8), Alignment);
MemOpChains.push_back(LoadVal.getValue(1));
// Shift the loaded value.
unsigned Shamt;
if (isLittle)
Shamt = TotalBytesLoaded * 8;
else
Shamt = (RegSizeInBytes - (TotalBytesLoaded + LoadSizeInBytes)) * 8;
SDValue Shift = DAG.getNode(ISD::SHL, DL, RegTy, LoadVal,
DAG.getConstant(Shamt, DL, MVT::i32));
if (Val.getNode())
Val = DAG.getNode(ISD::OR, DL, RegTy, Val, Shift);
else
Val = Shift;
OffsetInBytes += LoadSizeInBytes;
TotalBytesLoaded += LoadSizeInBytes;
Alignment = std::min(Alignment, LoadSizeInBytes);
}
unsigned ArgReg = ArgRegs[ByVal.FirstIdx + I];
RegsToPass.push_back(std::make_pair(ArgReg, Val));
return;
}
}
// Copy remainder of byval arg to it with memcpy.
unsigned MemCpySize = ByValSizeInBytes - OffsetInBytes;
SDValue Src = DAG.getNode(ISD::ADD, DL, PtrTy, Arg,
DAG.getConstant(OffsetInBytes, DL, PtrTy));
SDValue Dst = DAG.getNode(ISD::ADD, DL, PtrTy, StackPtr,
DAG.getIntPtrConstant(ByVal.Address, DL));
Chain = DAG.getMemcpy(Chain, DL, Dst, Src,
DAG.getConstant(MemCpySize, DL, PtrTy),
Align(Alignment), /*isVolatile=*/false, /*AlwaysInline=*/false,
/*isTailCall=*/false,
MachinePointerInfo(), MachinePointerInfo());
MemOpChains.push_back(Chain);
}
/// LowerCall - functions arguments are copied from virtual regs to
/// (physical regs)/(stack frame), CALLSEQ_START and CALLSEQ_END are emitted.
SDValue
Cpu0TargetLowering::LowerCall(TargetLowering::CallLoweringInfo &CLI,
SmallVectorImpl<SDValue> &InVals) const {
// Walk the register/memloc assignments, inserting copies/loads.
for (unsigned i = 0, e = ArgLocs.size(); i != e; ++i) {
if (Flags.isByVal()) {
assert(Flags.getByValSize() &&
"ByVal args of size 0 should have been ignored by front-end.");
assert(ByValArg != Cpu0CCInfo.byval_end());
assert(!IsTailCall &&
"Do not tail-call optimize if there is a byval argument.");
passByValArg(Chain, DL, RegsToPass, MemOpChains, StackPtr, MFI, DAG, Arg,
Cpu0CCInfo, *ByValArg, Flags, Subtarget.isLittle());
++ByValArg;
continue;
}
...
}
...
}
In LowerCall(), Flags.isByVal() will be true if the function call in the caller contains a byval struct type, as shown below:
lbdex/input/tailcall.ll
define internal fastcc i32 @caller9_1() nounwind noinline {
entry:
...
%call = tail call i32 @callee9(%struct.S* byval @gs1) nounwind
ret i32 %call
}
In LowerFormalArguments(), Flags.isByVal() will be true when it encounters a byval parameter in the callee function, as shown below:
lbdex/input/tailcall.ll
define i32 @caller12(%struct.S* nocapture byval %a0) nounwind {
entry:
...
}
At this point, I don’t know how to make Clang generate byval IR using the C language.
Function Call Optimization¶
Tail Call Optimization¶
Tail call optimization is applied in certain function call situations. In some cases, the caller and callee can share the same memory stack.
When applied to recursive function calls, this optimization often reduces the stack space requirement from linear, or O(n), to constant, or O(1) [5].
LLVM IR supports tailcall as described here [6].
The tailcall instructions appearing in Cpu0ISelLowering.cpp and Cpu0InstrInfo.td are used to implement tail call optimization.
lbdex/input/ch9_2_tailcall.cpp
int factorial(int x)
{
if (x > 0)
return x*factorial(x-1);
else
return 1;
}
int test_tailcall(int a)
{
return factorial(a);
}
Run Chapter9_2/ with ch9_2_tailcall.cpp to get the following result.
JonathantekiiMac:input Jonathan$ clang -O1 -target mips-unknown-linux-gnu -c
ch9_2_tailcall.cpp -emit-llvm -o ch9_2_tailcall.bc
JonathantekiiMac:input Jonathan$ ~/llvm/test/build/bin/
llvm-dis ch9_2_tailcall.bc -o -
...
; Function Attrs: nounwind readnone
define i32 @_Z9factoriali(i32 %x) #0 {
%1 = icmp sgt i32 %x, 0
br i1 %1, label %tailrecurse, label %tailrecurse._crit_edge
tailrecurse: ; preds = %tailrecurse, %0
%x.tr2 = phi i32 [ %2, %tailrecurse ], [ %x, %0 ]
%accumulator.tr1 = phi i32 [ %3, %tailrecurse ], [ 1, %0 ]
%2 = add nsw i32 %x.tr2, -1
%3 = mul nsw i32 %x.tr2, %accumulator.tr1
%4 = icmp sgt i32 %2, 0
br i1 %4, label %tailrecurse, label %tailrecurse._crit_edge
tailrecurse._crit_edge: ; preds = %tailrecurse, %0
%accumulator.tr.lcssa = phi i32 [ 1, %0 ], [ %3, %tailrecurse ]
ret i32 %accumulator.tr.lcssa
}
; Function Attrs: nounwind readnone
define i32 @_Z13test_tailcalli(i32 %a) #0 {
%1 = tail call i32 @_Z9factoriali(i32 %a)
ret i32 %1
}
...
JonathantekiiMac:input Jonathan$ ~/llvm/test/build/bin/
llc -march=cpu0 -mcpu=cpu032II -relocation-model=static -filetype=asm
-enable-cpu0-tail-calls ch9_2_tailcall.bc -stats -o -
.text
.section .mdebug.abi32
.previous
.file "ch9_2_tailcall.bc"
.globl _Z9factoriali
.align 2
.type _Z9factoriali,@function
.ent _Z9factoriali # @_Z9factoriali
_Z9factoriali:
.frame $sp,0,$lr
.mask 0x00000000,0
.set noreorder
.set nomacro
# BB#0:
addiu $2, $zero, 1
slt $3, $4, $2
bne $3, $zero, $BB0_2
nop
$BB0_1: # %tailrecurse
# =>This Inner Loop Header: Depth=1
mul $2, $4, $2
addiu $4, $4, -1
addiu $3, $zero, 0
slt $3, $3, $4
bne $3, $zero, $BB0_1
nop
$BB0_2: # %tailrecurse._crit_edge
ret $lr
nop
.set macro
.set reorder
.end _Z9factoriali
$tmp0:
.size _Z9factoriali, ($tmp0)-_Z9factoriali
.globl _Z13test_tailcalli
.align 2
.type _Z13test_tailcalli,@function
.ent _Z13test_tailcalli # @_Z13test_tailcalli
_Z13test_tailcalli:
.frame $sp,0,$lr
.mask 0x00000000,0
.set noreorder
.set nomacro
# BB#0:
jmp _Z9factoriali
nop
.set macro
.set reorder
.end _Z13test_tailcalli
$tmp1:
.size _Z13test_tailcalli, ($tmp1)-_Z13test_tailcalli
===-------------------------------------------------------------------------===
... Statistics Collected ...
===-------------------------------------------------------------------------===
...
1 cpu0-lower - Number of tail calls
...
The tail call optimization shares the caller’s and callee’s stack, and it is applied in cpu032II only for this example (it uses jmp _Z9factoriali instead of jsub _Z9factoriali).
However, cpu032I (which passes all arguments on the stack) does not satisfy the condition NextStackOffset <= FI.getIncomingArgSize() in isEligibleForTailCallOptimization(), and thus returns false for the function, as shown below:
lbdex/chapters/Chapter9_2/Cpu0SEISelLowering.cpp
bool Cpu0SETargetLowering::
isEligibleForTailCallOptimization(const Cpu0CC &Cpu0CCInfo,
unsigned NextStackOffset,
const Cpu0FunctionInfo& FI) const {
if (!EnableCpu0TailCalls)
return false;
// Return false if either the callee or caller has a byval argument.
if (Cpu0CCInfo.hasByValArg() || FI.hasByvalArg())
return false;
// Return true if the callee's argument area is no larger than the
// caller's.
return NextStackOffset <= FI.getIncomingArgSize();
}
lbdex/chapters/Chapter9_2/Cpu0ISelLowering.cpp
/// LowerCall - functions arguments are copied from virtual regs to
/// (physical regs)/(stack frame), CALLSEQ_START and CALLSEQ_END are emitted.
SDValue
Cpu0TargetLowering::LowerCall(TargetLowering::CallLoweringInfo &CLI,
SmallVectorImpl<SDValue> &InVals) const {
// Check if it's really possible to do a tail call.
if (IsTailCall)
IsTailCall =
isEligibleForTailCallOptimization(Cpu0CCInfo, NextStackOffset,
*MF.getInfo<Cpu0FunctionInfo>());
if (!IsTailCall && CLI.CB && CLI.CB->isMustTailCall())
report_fatal_error("failed to perform tail call elimination on a call "
"site marked musttail");
if (IsTailCall)
++NumTailCalls;
if (!IsTailCall)
Chain = DAG.getCALLSEQ_START(Chain, NextStackOffset, 0, DL);
if (IsTailCall)
return DAG.getNode(Cpu0ISD::TailCall, DL, MVT::Other, Ops);
...
}
Since tail call optimization translates the call into a jmp instruction directly instead of jsub, the callseq_start, callseq_end, and the DAG nodes created in LowerCallResult() and LowerReturn() are unnecessary. It creates DAGs for ch9_2_tailcall.cpp as shown in Fig. 45.
![digraph "isel input for _Z13test_tailcalli:" {
rankdir="BT";
// label="Figure: Outgoing arguments DAGs created for ch9_2_tailcall.cpp";
Node0x103a04f20 [shape=record,shape=Mrecord,label="{EntryToken|t0|{<d0>ch}}"];
Node0x10404ef70 [shape=record,shape=Mrecord,label="{Register %vreg0|t1|{<d0>i32}}"];
Node0x10404ebf0 [shape=record,shape=Mrecord,label="{TargetGlobalAddress\<i32 (i32)* @_Z9factoriali\> 0|t7|{<d0>i32}}"];
Node0x10404ea30 [shape=record,shape=Mrecord,label="{Register %A0|t8|{<d0>i32}}"];
Node0x10404ec60 [shape=record,shape=Mrecord,label="{RegisterMask|t10|{<d0>Untyped}}"];
Node0x10404f050 [shape=record,shape=Mrecord,label="{{<s0>0|<s1>1}|CopyFromReg|t2|{<d0>i32|<d1>ch}}"];
Node0x10404f050:s0 -> Node0x103a04f20:d0[color=blue,style=dashed];
Node0x10404f050:s1 -> Node0x10404ef70:d0;
Node0x10404eb10 [shape=record,shape=Mrecord,label="{{<s0>0|<s1>1|<s2>2}|CopyToReg|t9|{<d0>ch|<d1>glue}}"];
Node0x10404eb10:s0 -> Node0x103a04f20:d0[color=blue,style=dashed];
Node0x10404eb10:s1 -> Node0x10404ea30:d0;
Node0x10404eb10:s2 -> Node0x10404f050:d0;
Node0x10404e9c0 [shape=record,shape=Mrecord,label="{{<s0>0|<s1>1|<s2>2|<s3>3|<s4>4}|Cpu0ISD::TailCall|t11|{<d0>ch}}"];
Node0x10404e9c0:s0 -> Node0x103a04f20:d0[color=blue,style=dashed];
Node0x10404e9c0:s1 -> Node0x10404ebf0:d0;
Node0x10404e9c0:s2 -> Node0x10404ea30:d0;
Node0x10404e9c0:s3 -> Node0x10404ec60:d0;
Node0x10404e9c0:s4 -> Node0x10404eb10:d1[color=red,style=bold];
Node0x0[ plaintext=circle, label ="GraphRoot"];
Node0x0 -> Node0x10404e9c0:d0[color=blue,style=dashed];
}](_images/graphviz-9034885399967739d5cb51bf8bee330312802532.png)
Fig. 45 Outgoing arguments DAGs created for ch9_2_tailcall.cpp¶
Finally, the DAGs translation of the tail call is listed in the following table.
Stage |
DAG |
Function |
|---|---|---|
Backend lowering |
Cpu0ISD::TailCall |
LowerCall() |
Instruction selection |
TAILCALL |
note 1 |
Instruction Print |
JMP |
note 2 |
note 1: by Cpu0InstrInfo.td as follows,
lbdex/chapters/Chapter9_1/Cpu0InstrInfo.td
// Tail call
def Cpu0TailCall : SDNode<"Cpu0ISD::TailCall", SDT_Cpu0JmpLink,
[SDNPHasChain, SDNPOptInGlue, SDNPVariadic]>;
def : Pat<(Cpu0TailCall (iPTR tglobaladdr:$dst)),
(TAILCALL tglobaladdr:$dst)>;
def : Pat<(Cpu0TailCall (iPTR texternalsym:$dst)),
(TAILCALL texternalsym:$dst)>;
note 2: by Cpu0InstrInfo.td and emitPseudoExpansionLowering() of Cpu0AsmPrinter.cpp as follows,
lbdex/chapters/Chapter9_1/Cpu0InstrInfo.td
let isCall = 1, isTerminator = 1, isReturn = 1, isBarrier = 1, hasDelaySlot = 1,
hasExtraSrcRegAllocReq = 1, Defs = [AT] in {
class TailCall<Instruction JumpInst> :
PseudoSE<(outs), (ins calltarget:$target), [], IIBranch>,
PseudoInstExpansion<(JumpInst jmptarget:$target)>;
class TailCallReg<RegisterClass RO, Instruction JRInst,
RegisterClass ResRO = RO> :
PseudoSE<(outs), (ins RO:$rs), [(Cpu0TailCall RO:$rs)], IIBranch>,
PseudoInstExpansion<(JRInst ResRO:$rs)>;
}
let Predicates = [Ch9_1] in {
def TAILCALL : TailCall<JMP>;
def TAILCALL_R : TailCallReg<GPROut, JR>;
}
lbdex/chapters/Chapter9_1/Cpu0AsmPrinter.h
// tblgen'erated function.
bool emitPseudoExpansionLowering(MCStreamer &OutStreamer,
const MachineInstr *MI);
lbdex/chapters/Chapter9_1/Cpu0AsmPrinter.cpp
//- emitInstruction() must exists or will have run time error.
void Cpu0AsmPrinter::emitInstruction(const MachineInstr *MI) {
//@EmitInstruction body {
if (MI->isDebugValue()) {
SmallString<128> Str;
raw_svector_ostream OS(Str);
PrintDebugValueComment(MI, OS);
return;
}
//@print out instruction:
// Print out both ordinary instruction and boudle instruction
MachineBasicBlock::const_instr_iterator I = MI->getIterator();
MachineBasicBlock::const_instr_iterator E = MI->getParent()->instr_end();
do {
// Do any auto-generated pseudo lowerings.
if (emitPseudoExpansionLowering(*OutStreamer, &*I))
continue;
if (I->isPseudo() && !isLongBranchPseudo(I->getOpcode()))
llvm_unreachable("Pseudo opcode found in emitInstruction()");
MCInst TmpInst0;
// Call Cpu0MCInstLower::Lower(const MachineInstr *MI, MCInst &OutMI) to
// extracts MCInst from MachineInstr.
MCInstLowering.Lower(&*I, TmpInst0);
OutStreamer->emitInstruction(TmpInst0, getSubtargetInfo());
} while ((++I != E) && I->isInsideBundle()); // Delay slot check
}
The function emitPseudoExpansionLowering() is generated by TableGen and is located in Cpu0GenMCPseudoLowering.inc.
Recursion optimization¶
As mentioned in the last section, cpu032I cannot perform tail call optimization in ch9_2_tailcall.cpp due to the limitation that the argument size condition is not satisfied.
However, when running with the clang -O3 optimization option, it can achieve
the same or even better performance than tail call optimization, as shown below:
JonathantekiiMac:input Jonathan$ clang -O1 -target mips-unknown-linux-gnu -c
ch9_2_tailcall.cpp -emit-llvm -o ch9_2_tailcall.bc
JonathantekiiMac:input Jonathan$ ~/llvm/test/build/bin/
llvm-dis ch9_2_tailcall.bc -o -
...
; Function Attrs: nounwind readnone
define i32 @_Z9factoriali(i32 %x) #0 {
%1 = icmp sgt i32 %x, 0
br i1 %1, label %tailrecurse.preheader, label %tailrecurse._crit_edge
tailrecurse.preheader: ; preds = %0
br label %tailrecurse
tailrecurse: ; preds = %tailrecurse,
%tailrecurse.preheader
%x.tr2 = phi i32 [ %2, %tailrecurse ], [ %x, %tailrecurse.preheader ]
%accumulator.tr1 = phi i32 [ %3, %tailrecurse ], [ 1, %tailrecurse.preheader ]
%2 = add nsw i32 %x.tr2, -1
%3 = mul nsw i32 %x.tr2, %accumulator.tr1
%4 = icmp sgt i32 %2, 0
br i1 %4, label %tailrecurse, label %tailrecurse._crit_edge.loopexit
tailrecurse._crit_edge.loopexit: ; preds = %tailrecurse
%.lcssa = phi i32 [ %3, %tailrecurse ]
br label %tailrecurse._crit_edge
tailrecurse._crit_edge: ; preds = %tailrecurse._crit
_edge.loopexit, %0
%accumulator.tr.lcssa = phi i32 [ 1, %0 ], [ %.lcssa, %tailrecurse._crit_edge
.loopexit ]
ret i32 %accumulator.tr.lcssa
}
; Function Attrs: nounwind readnone
define i32 @_Z13test_tailcalli(i32 %a) #0 {
%1 = icmp sgt i32 %a, 0
br i1 %1, label %tailrecurse.i.preheader, label %_Z9factoriali.exit
tailrecurse.i.preheader: ; preds = %0
br label %tailrecurse.i
tailrecurse.i: ; preds = %tailrecurse.i,
%tailrecurse.i.preheader
%x.tr2.i = phi i32 [ %2, %tailrecurse.i ], [ %a, %tailrecurse.i.preheader ]
%accumulator.tr1.i = phi i32 [ %3, %tailrecurse.i ], [ 1, %tailrecurse.i.
preheader ]
%2 = add nsw i32 %x.tr2.i, -1
%3 = mul nsw i32 %accumulator.tr1.i, %x.tr2.i
%4 = icmp sgt i32 %2, 0
br i1 %4, label %tailrecurse.i, label %_Z9factoriali.exit.loopexit
_Z9factoriali.exit.loopexit: ; preds = %tailrecurse.i
%.lcssa = phi i32 [ %3, %tailrecurse.i ]
br label %_Z9factoriali.exit
_Z9factoriali.exit: ; preds = %_Z9factoriali.
exit.loopexit, %0
%accumulator.tr.lcssa.i = phi i32 [ 1, %0 ], [ %.lcssa, %_Z9factoriali.
exit.loopexit ]
ret i32 %accumulator.tr.lcssa.i
}
...
JonathantekiiMac:input Jonathan$ ~/llvm/test/build/bin/
llc -march=cpu0 -mcpu=cpu032I -relocation-model=static -filetype=asm
ch9_2_tailcall.bc -o -
.text
.section .mdebug.abiS32
.previous
.file "ch9_2_tailcall.bc"
.globl _Z9factoriali
.align 2
.type _Z9factoriali,@function
.ent _Z9factoriali # @_Z9factoriali
_Z9factoriali:
.frame $sp,0,$lr
.mask 0x00000000,0
.set noreorder
.set nomacro
# BB#0:
addiu $2, $zero, 1
ld $3, 0($sp)
cmp $sw, $3, $2
jlt $sw, $BB0_2
nop
$BB0_1: # %tailrecurse
# =>This Inner Loop Header: Depth=1
mul $2, $3, $2
addiu $3, $3, -1
addiu $4, $zero, 0
cmp $sw, $3, $4
jgt $sw, $BB0_1
nop
$BB0_2: # %tailrecurse._crit_edge
ret $lr
nop
.set macro
.set reorder
.end _Z9factoriali
$tmp0:
.size _Z9factoriali, ($tmp0)-_Z9factoriali
.globl _Z13test_tailcalli
.align 2
.type _Z13test_tailcalli,@function
.ent _Z13test_tailcalli # @_Z13test_tailcalli
_Z13test_tailcalli:
.frame $sp,0,$lr
.mask 0x00000000,0
.set noreorder
.set nomacro
# BB#0:
addiu $2, $zero, 1
ld $3, 0($sp)
cmp $sw, $3, $2
jlt $sw, $BB1_2
nop
$BB1_1: # %tailrecurse.i
# =>This Inner Loop Header: Depth=1
mul $2, $2, $3
addiu $3, $3, -1
addiu $4, $zero, 0
cmp $sw, $3, $4
jgt $sw, $BB1_1
nop
$BB1_2: # %_Z9factoriali.exit
ret $lr
nop
.set macro
.set reorder
.end _Z13test_tailcalli
$tmp1:
.size _Z13test_tailcalli, ($tmp1)-_Z13test_tailcalli
According to the above LLVM IR, the clang -O3 option replaces recursion
with a loop by inlining the callee recursion function. This is a frontend
optimization achieved through cross-function analysis.
Cpu0 doesn’t support fastcc [7], but it can pass the fastcc keyword in the IR. MIPS supports fastcc by using as many registers as possible without strictly following the ABI specification.
Other Features Supported¶
This section supports features for the “$gp register caller saved register in PIC addressing mode,” “variable number of arguments,” and “dynamic stack allocation.”
Run Chapter9_2/ with ch9_3_vararg.cpp to get the following error:
lbdex/input/ch9_3_vararg.cpp
#include <stdarg.h>
int sum_i(int amount, ...)
{
int i = 0;
int val = 0;
int sum = 0;
va_list vl;
va_start(vl, amount);
for (i = 0; i < amount; i++)
{
val = va_arg(vl, int);
sum += val;
}
va_end(vl);
return sum;
}
long long sum_ll(long long amount, ...)
{
long long i = 0;
long long val = 0;
long long sum = 0;
va_list vl;
va_start(vl, amount);
for (i = 0; i < amount; i++)
{
val = va_arg(vl, long long);
sum += val;
}
va_end(vl);
return sum;
}
int test_va_arg()
{
int a = sum_i(6, 0, 1, 2, 3, 4, 5);
long long b = sum_ll(6LL, 0LL, 1LL, 2LL, 3LL, -4LL, -5LL);
return a+(int)b; // 12
}
118-165-78-230:input Jonathan$ clang -target mips-unknown-linux-gnu -c
ch9_3_vararg.cpp -emit-llvm -o ch9_3_vararg.bc
118-165-78-230:input Jonathan$ /Users/Jonathan/llvm/test/build/
bin/llc -march=cpu0 -relocation-model=pic -filetype=asm ch9_3_vararg.bc -o -
...
LLVM ERROR: Cannot select: 0x7f8b6902fd10: ch = vastart 0x7f8b6902fa10,
0x7f8b6902fb10, 0x7f8b6902fc10 [ORD=9] [ID=22]
0x7f8b6902fb10: i32 = FrameIndex<5> [ORD=7] [ID=9]
In function: _Z5sum_iiz
lbdex/input/ch9_3_alloc.cpp
// This file needed compile without option, -target mips-unknown-linux-gnu, so
// it is verified by build-run_backend2.sh or verified in lld linker support
// (build-slinker.sh).
//#include <alloca.h>
//#include <stdlib.h>
int sum(int x1, int x2, int x3, int x4, int x5, int x6)
{
int sum = x1 + x2 + x3 + x4 + x5 + x6;
return sum;
}
int weight_sum(int x1, int x2, int x3, int x4, int x5, int x6)
{
// int *b = (int*)alloca(sizeof(int) * 1 * x1);
int* b = (int*)__builtin_alloca(sizeof(int) * 1 * x1);
int *a = b;
*b = x3;
int weight = sum(3*x1, x2, x3, x4, 2*x5, x6);
return (weight + (*a));
}
int test_alloc()
{
int a = weight_sum(1, 2, 3, 4, 5, 6); // 31
return a;
}
Run Chapter9_2 with ch9_3_alloc.cpp to get the following error.
118-165-72-242:input Jonathan$ clang -target mips-unknown-linux-gnu -c
ch9_3_alloc.cpp -emit-llvm -o ch9_3_alloc.bc
118-165-72-242:input Jonathan$ /Users/Jonathan/llvm/test/build/
bin/llc -march=cpu0 -mcpu=cpu032I -cpu0-s32-calls=false
-relocation-model=pic -filetype=asm ch9_3_alloc.bc -o -
...
LLVM ERROR: Cannot select: 0x7ffd8b02ff10: i32,ch = dynamic_stackalloc
0x7ffd8b02f910:1, 0x7ffd8b02fe10, 0x7ffd8b02c010 [ORD=12] [ID=48]
0x7ffd8b02fe10: i32 = and 0x7ffd8b02fc10, 0x7ffd8b02fd10 [ORD=12] [ID=47]
0x7ffd8b02fc10: i32 = add 0x7ffd8b02fa10, 0x7ffd8b02fb10 [ORD=12] [ID=46]
0x7ffd8b02fa10: i32 = shl 0x7ffd8b02f910, 0x7ffd8b02f510 [ID=45]
0x7ffd8b02f910: i32,ch = load 0x7ffd8b02ee10, 0x7ffd8b02e310,
0x7ffd8b02b310<LD4[%1]> [ID=44]
0x7ffd8b02e310: i32 = FrameIndex<1> [ORD=3] [ID=10]
0x7ffd8b02b310: i32 = undef [ORD=1] [ID=2]
0x7ffd8b02f510: i32 = Constant<2> [ID=25]
0x7ffd8b02fb10: i32 = Constant<7> [ORD=12] [ID=16]
0x7ffd8b02fd10: i32 = Constant<-8> [ORD=12] [ID=17]
0x7ffd8b02c010: i32 = Constant<0> [ORD=12] [ID=8]
In function: _Z5sum_iiiiiii
Gloabal Variables Accessing In PIC Addressing Mode¶
In order to support Global Variables accessing in PIC mode, The $gp Register Caller Saved Register in PIC Addressing Mode have to be solved.
According to the original Cpu0 website information, it only supports “jsub” for 24-bit address range access. We added “jalr” to Cpu0 and expanded it to 32-bit addressing. We made this change for two reasons:
Cpu0 can be expanded to 32-bit address space by simply adding this instruction.
Cpu0 and this book are designed as a tutorial for better understanding.
We reserve “jalr” for PIC mode, which is used for dynamic linking functions, to demonstrate:
How the caller handles the caller-saved register $gp when calling a function.
How code in the shared library function uses $gp to access the global variable address.
Why using jalr for dynamic linking functions is easier to implement and faster. As we discussed in the section PIC Mode in Chapter Global Variables this solution is popular in real applications and deserves to be incorporated into the official Cpu0 design in compiler books.
In the chapter on “Global Variables,” we mentioned two link types: static link and dynamic link. The option -relocation-model=static is for static link functions, while -relocation-model=pic is for dynamic link functions. An example of a dynamic link function is calling functions from a shared library.
Shared libraries consist of many dynamic link functions that are typically loaded at runtime. Since shared libraries can be loaded at different memory addresses, the address of a global variable cannot be determined at link time. However, the distance between the global variable address and the start address of the shared library function can be calculated once it has been loaded.
Let’s run Chapter9_3/ with ch9_gprestore.cpp to get the following result. We will add comments in the result for explanation.
lbdex/input/ch9_gprestore.cpp
extern int sum_i(int x1);
int call_sum_i() {
int a = sum_i(1);
a += sum_i(2);
return a;
}
118-165-78-230:input Jonathan$ /Users/Jonathan/llvm/test/build/
bin/llc -march=cpu0 -mcpu=cpu032II-cpu0-s32-calls=true
-relocation-model=pic -filetype=asm ch9_gprestore.bc -o -
...
.cpload $t9
.set nomacro
# BB#0: # %entry
addiu $sp, $sp, -24
$tmp0:
.cfi_def_cfa_offset 24
st $lr, 12($sp) # 4-byte Folded Spill
st $fp, 16($sp) # 4-byte Folded Spill
$tmp1:
.cfi_offset 14, -4
$tmp2:
.cfi_offset 12, -8
.cprestore 8 // save $gp to 8($sp)
ld $t9, %call16(_Z5sum_ii)($gp)
addiu $4, $zero, 1
jalr $t9
nop
ld $gp, 8($sp) // restore $gp from 8($sp)
add $8, $zero, $2
ld $t9, %call16(_Z5sum_ii)($gp)
addiu $4, $zero, 2
jalr $t9
nop
ld $gp, 8($sp) // restore $gp from 8($sp)
addu $2, $2, $8
ld $8, 8($sp) # 4-byte Folded Reload
ld $lr, 12($sp) # 4-byte Folded Reload
addiu $sp, $sp, 16
ret $lr
nop
As mentioned in the code comment, “.cprestore 8” is a pseudo instruction for saving $gp to 8($sp), while the instruction “ld $gp, 8($sp)” restores the $gp. Refer to Table 8-1 of the “MIPSpro TM Assembly Language Programmer’s Guide” [2] for more details.
In other words, $gp is a caller-saved register, so the main() function needs to save and restore $gp before and after calling the shared library _Z5sum_ii() function.
In LLVM MIPS 3.5, the .cprestore instruction was removed in PIC mode, meaning $gp is no longer treated as a caller-saved register in PIC. However, it is still present in Cpu0, and this feature can be removed by not defining it in Cpu0Config.h.
The #ifdef ENABLE_GPRESTORE part of the code in Cpu0 can be removed, but it comes with the cost of reserving the $gp register as a specific register that cannot be allocated for program variables in PIC mode. As explained in earlier chapters on “Global Variables,” PIC is not a critical function, and its performance advantage can be considered negligible in dynamic linking. Therefore, we keep this feature in Cpu0.
Reserving $gp as a specific register in PIC mode will save a lot of code during programming. When reserving $gp, the .cprestore can be disabled using the option “-cpu0-reserve-gp”.
The .cpload instruction is still needed even when reserving $gp (since programmers may implement boot code functions with a mix of C and assembly). In this case, the programmer can set the $gp value through .cpload.
If enabling -cpu0-no-cpload, and undefining ENABLE_GPRESTORE or enabling -cpu0-reserve-gp, the .cpload and $gp save/restore instructions will not be issued, as shown in the following.
118-165-78-230:input Jonathan$ /Users/Jonathan/llvm/test/build/
bin/llc -march=cpu0 -mcpu=cpu032II-cpu0-s32-calls=true
-relocation-model=pic -filetype=asm ch9_gprestore.bc -cpu0-no-cpload
-cpu0-reserve-gp -o -
...
# BB#0:
addiu $sp, $sp, -24
$tmp0:
.cfi_def_cfa_offset 24
st $lr, 20($sp) # 4-byte Folded Spill
st $fp, 16($sp) # 4-byte Folded Spill
$tmp1:
.cfi_offset 14, -4
$tmp2:
.cfi_offset 12, -8
move $fp, $sp
$tmp3:
.cfi_def_cfa_register 12
ld $t9, %call16(_Z5sum_ii)($gp)
addiu $4, $zero, 1
jalr $t9
nop
st $2, 12($fp)
addiu $4, $zero, 2
ld $t9, %call16(_Z5sum_ii)($gp)
jalr $t9
nop
ld $3, 12($fp)
addu $2, $3, $2
st $2, 12($fp)
move $sp, $fp
ld $fp, 16($sp) # 4-byte Folded Reload
ld $lr, 20($sp) # 4-byte Folded Reload
addiu $sp, $sp, 24
ret $lr
nop
LLVM Mips 3.1 emits the directives .cpload and .cprestore, and Cpu0
inherits this behavior from that version. However, newer versions of LLVM Mips
replace .cpload with actual instructions and remove .cprestore entirely.
In these versions, the $gp register is treated as a reserved register in PIC
(position-independent code) mode.
According to the MIPS assembly documentation I referenced, $gp is considered
a “caller-saved register.” Cpu0 follows this convention and provides an option to
reserve the $gp register accordingly.
118-165-78-230:input Jonathan$ /Users/Jonathan/llvm/test/build/
bin/llc -march=mips -relocation-model=pic -filetype=asm ch9_gprestore.bc
-o -
...
# BB#0: # %entry
lui $2, %hi(_gp_disp)
ori $2, $2, %lo(_gp_disp)
addiu $sp, $sp, -32
$tmp0:
.cfi_def_cfa_offset 32
sw $ra, 28($sp) # 4-byte Folded Spill
sw $fp, 24($sp) # 4-byte Folded Spill
sw $16, 20($sp) # 4-byte Folded Spill
$tmp1:
.cfi_offset 31, -4
$tmp2:
.cfi_offset 30, -8
$tmp3:
.cfi_offset 16, -12
move $fp, $sp
$tmp4:
.cfi_def_cfa_register 30
addu $16, $2, $25
lw $25, %call16(_Z5sum_ii)($16)
addiu $4, $zero, 1
jalr $25
move $gp, $16
sw $2, 16($fp)
lw $25, %call16(_Z5sum_ii)($16)
jalr $25
addiu $4, $zero, 2
lw $1, 16($fp)
addu $2, $1, $2
sw $2, 16($fp)
move $sp, $fp
lw $16, 20($sp) # 4-byte Folded Reload
lw $fp, 24($sp) # 4-byte Folded Reload
lw $ra, 28($sp) # 4-byte Folded Reload
jr $ra
addiu $sp, $sp, 32
The following code, added in Chapter9_3/, emits .cprestore or the
corresponding machine instructions before the first PIC function call.
lbdex/chapters/Chapter9_3/Cpu0ISelLowering.cpp
/// LowerCall - functions arguments are copied from virtual regs to
/// (physical regs)/(stack frame), CALLSEQ_START and CALLSEQ_END are emitted.
SDValue
Cpu0TargetLowering::LowerCall(TargetLowering::CallLoweringInfo &CLI,
SmallVectorImpl<SDValue> &InVals) const {
#ifdef ENABLE_GPRESTORE
if (!Cpu0ReserveGP) {
// If this is the first call, create a stack frame object that points to
// a location to which .cprestore saves $gp.
if (IsPIC && Cpu0FI->globalBaseRegFixed() && !Cpu0FI->getGPFI())
Cpu0FI->setGPFI(MFI.CreateFixedObject(4, 0, true));
if (Cpu0FI->needGPSaveRestore())
MFI.setObjectOffset(Cpu0FI->getGPFI(), NextStackOffset);
}
#endif
...
}
lbdex/chapters/Chapter9_3/Cpu0MachineFunction.h
#ifdef ENABLE_GPRESTORE
bool needGPSaveRestore() const { return getGPFI(); }
#endif
lbdex/chapters/Chapter9_3/Cpu0SEFrameLowering.cpp
void Cpu0SEFrameLowering::emitPrologue(MachineFunction &MF,
MachineBasicBlock &MBB) const {
#ifdef ENABLE_GPRESTORE
// Restore GP from the saved stack location
if (Cpu0FI->needGPSaveRestore()) {
unsigned Offset = MFI.getObjectOffset(Cpu0FI->getGPFI());
BuildMI(MBB, MBBI, dl, TII.get(Cpu0::CPRESTORE)).addImm(Offset)
.addReg(Cpu0::GP);
}
#endif
}
lbdex/chapters/Chapter9_3/Cpu0RegisterInfo.cpp
//- If no eliminateFrameIndex(), it will hang on run.
// pure virtual method
// FrameIndex represent objects inside a abstract stack.
// We must replace FrameIndex with an stack/frame pointer
// direct reference.
void Cpu0RegisterInfo::
eliminateFrameIndex(MachineBasicBlock::iterator II, int SPAdj,
unsigned FIOperandNum, RegScavenger *RS) const {
#ifdef ENABLE_GPRESTORE //2
if (Cpu0FI->isOutArgFI(FrameIndex) || Cpu0FI->isGPFI(FrameIndex) ||
Cpu0FI->isDynAllocFI(FrameIndex))
Offset = spOffset;
else
#endif
...
}
lbdex/chapters/Chapter9_3/Cpu0InstrInfo.td
// When handling PIC code the assembler needs .cpload and .cprestore
// directives. If the real instructions corresponding these directives
// are used, we have the same behavior, but get also a bunch of warnings
// from the assembler.
let hasSideEffects = 0 in
def CPRESTORE : Cpu0Pseudo<(outs), (ins i32imm:$loc, CPURegs:$gp),
".cprestore\t$loc", []>;
lbdex/chapters/Chapter9_3/Cpu0AsmPrinter.cpp
#ifdef ENABLE_GPRESTORE
void Cpu0AsmPrinter::EmitInstrWithMacroNoAT(const MachineInstr *MI) {
MCInst TmpInst;
MCInstLowering.Lower(MI, TmpInst);
OutStreamer->emitRawText(StringRef("\t.set\tmacro"));
if (Cpu0FI->getEmitNOAT())
OutStreamer->emitRawText(StringRef("\t.set\tat"));
OutStreamer->emitInstruction(TmpInst, getSubtargetInfo());
if (Cpu0FI->getEmitNOAT())
OutStreamer->emitRawText(StringRef("\t.set\tnoat"));
OutStreamer->emitRawText(StringRef("\t.set\tnomacro"));
}
#endif
#ifdef ENABLE_GPRESTORE
void Cpu0AsmPrinter::emitPseudoCPRestore(MCStreamer &OutStreamer,
const MachineInstr *MI) {
SmallVector<MCInst, 4> MCInsts;
const MachineOperand &MO = MI->getOperand(0);
assert(MO.isImm() && "CPRESTORE's operand must be an immediate.");
int64_t Offset = MO.getImm();
if (OutStreamer.hasRawTextSupport()) {
// output assembly
if (!isInt<16>(Offset)) {
EmitInstrWithMacroNoAT(MI);
return;
}
MCInst TmpInst0;
MCInstLowering.Lower(MI, TmpInst0);
OutStreamer.emitInstruction(TmpInst0, getSubtargetInfo());
} else {
// output elf
MCInstLowering.LowerCPRESTORE(Offset, MCInsts);
for (SmallVector<MCInst, 4>::iterator I = MCInsts.begin();
I != MCInsts.end(); ++I)
OutStreamer.emitInstruction(*I, getSubtargetInfo());
return;
}
}
#endif
//- emitInstruction() must exists or will have run time error.
void Cpu0AsmPrinter::emitInstruction(const MachineInstr *MI) {
#ifdef ENABLE_GPRESTORE
if (I->getOpcode() == Cpu0::CPRESTORE) {
emitPseudoCPRestore(*OutStreamer, &*I);
continue;
}
#endif
...
}
lbdex/chapters/Chapter9_3/Cpu0MCInstLower.h
#ifdef ENABLE_GPRESTORE
void LowerCPRESTORE(int64_t Offset, SmallVector<MCInst, 4>& MCInsts);
#endif
lbdex/chapters/Chapter9_3/Cpu0MCInstLower.cpp
#ifdef ENABLE_GPRESTORE
// Lower ".cprestore offset" to "st $gp, offset($sp)".
void Cpu0MCInstLower::LowerCPRESTORE(int64_t Offset,
SmallVector<MCInst, 4>& MCInsts) {
assert(isInt<32>(Offset) && (Offset >= 0) &&
"Imm operand of .cprestore must be a non-negative 32-bit value.");
MCOperand SPReg = MCOperand::createReg(Cpu0::SP), BaseReg = SPReg;
MCOperand GPReg = MCOperand::createReg(Cpu0::GP);
MCOperand ZEROReg = MCOperand::createReg(Cpu0::ZERO);
if (!isInt<16>(Offset)) {
unsigned Hi = ((Offset + 0x8000) >> 16) & 0xffff;
Offset &= 0xffff;
MCOperand ATReg = MCOperand::createReg(Cpu0::AT);
BaseReg = ATReg;
// lui at,hi
// add at,at,sp
MCInsts.resize(2);
CreateMCInst(MCInsts[0], Cpu0::LUi, ATReg, ZEROReg, MCOperand::createImm(Hi));
CreateMCInst(MCInsts[1], Cpu0::ADD, ATReg, ATReg, SPReg);
}
MCInst St;
CreateMCInst(St, Cpu0::ST, GPReg, BaseReg, MCOperand::createImm(Offset));
MCInsts.push_back(St);
}
#endif
The added code in Cpu0AsmPrinter.cpp, as shown above, will call
LowerCPRESTORE() when the user runs the program with
llc -filetype=obj.
The added code in Cpu0MCInstLower.cpp, as shown above, handles the
machine instructions for .cprestore.
118-165-76-131:input Jonathan$ /Users/Jonathan/llvm/test/
build/bin/llc -march=cpu0 -relocation-model=pic -filetype=
obj ch9_1.bc -o ch9_1.cpu0.o
118-165-76-131:input Jonathan$ hexdump ch9_1.cpu0.o
...
// .cprestore machine instruction “ 01 ad 00 18”
00000d0 01 ad 00 18 09 20 00 00 01 2d 00 40 09 20 00 06
...
118-165-67-25:input Jonathan$ cat ch9_1.cpu0.s
...
.ent _Z5sum_iiiiiii # @_Z5sum_iiiiiii
_Z5sum_iiiiiii:
...
.cpload $t9 // assign $gp = $t9 by loader when loader load re-entry function
// (shared library) of _Z5sum_iiiiiii
.set nomacro
# BB#0:
...
.ent main # @main
...
.cprestore 24 // save $gp to 24($sp)
...
Running llc -static will emit the jsub instruction instead of
jalr, as shown below:
118-165-76-131:input Jonathan$ /Users/Jonathan/llvm/test/
build/bin/llc -march=cpu0 -relocation-model=static -filetype=
asm ch9_1.bc -o ch9_1.cpu0.s
118-165-76-131:input Jonathan$ cat ch9_1.cpu0.s
...
jsub _Z5sum_iiiiiii
...
Run ch9_1.bc with llc -filetype=obj, and you will find the Cx of
jsub Cx is 0, since Cx is calculated by the linker, as shown below.
Mips has the same 0 in its jal instruction.
// jsub _Z5sum_iiiiiii translate into 2B 00 00 00
00F0: 2B 00 00 00 01 2D 00 34 00 ED 00 3C 09 DD 00 40
The following code will emit ld $gp, ($gp save slot on stack) after jalr
by creating the file Cpu0EmitGPRestore.cpp, which runs as a function pass.
lbdex/chapters/Chapter9_3/CMakeLists.txt
Cpu0EmitGPRestore.cpp
lbdex/chapters/Chapter9_3/Cpu0TargetMachine.cpp
/// Cpu0 Code Generator Pass Configuration Options.
class Cpu0PassConfig : public TargetPassConfig {
#ifdef ENABLE_GPRESTORE
void addPreRegAlloc() override;
#endif
#ifdef ENABLE_GPRESTORE
void Cpu0PassConfig::addPreRegAlloc() {
if (!Cpu0ReserveGP) {
// $gp is a caller-saved register.
addPass(createCpu0EmitGPRestorePass(getCpu0TargetMachine()));
}
return;
}
#endif
lbdex/chapters/Chapter9_3/Cpu0.h
#ifdef ENABLE_GPRESTORE
FunctionPass *createCpu0EmitGPRestorePass(Cpu0TargetMachine &TM);
#endif
lbdex/chapters/Chapter9_3/Cpu0EmitGPRestore.cpp
//===-- Cpu0EmitGPRestore.cpp - Emit GP Restore Instruction ---------------===//
//
// The LLVM Compiler Infrastructure
//
// This file is distributed under the University of Illinois Open Source
// License. See LICENSE.TXT for details.
//
//===----------------------------------------------------------------------===//
//
// This pass emits instructions that restore $gp right
// after jalr instructions.
//
//===----------------------------------------------------------------------===//
#include "Cpu0.h"
#if CH >= CH9_3
#ifdef ENABLE_GPRESTORE
#include "Cpu0TargetMachine.h"
#include "Cpu0MachineFunction.h"
#include "llvm/ADT/Statistic.h"
#include "llvm/CodeGen/MachineFunctionPass.h"
#include "llvm/CodeGen/MachineInstrBuilder.h"
#include "llvm/CodeGen/TargetInstrInfo.h"
using namespace llvm;
#define DEBUG_TYPE "emit-gp-restore"
namespace {
struct Inserter : public MachineFunctionPass {
TargetMachine &TM;
static char ID;
Inserter(TargetMachine &tm)
: MachineFunctionPass(ID), TM(tm) { }
StringRef getPassName() const override {
return "Cpu0 Emit GP Restore";
}
bool runOnMachineFunction(MachineFunction &F) override;
};
char Inserter::ID = 0;
} // end of anonymous namespace
bool Inserter::runOnMachineFunction(MachineFunction &F) {
Cpu0FunctionInfo *Cpu0FI = F.getInfo<Cpu0FunctionInfo>();
const TargetSubtargetInfo *STI = TM.getSubtargetImpl(F.getFunction());
const TargetInstrInfo *TII = STI->getInstrInfo();
if ((TM.getRelocationModel() != Reloc::PIC_) ||
(!Cpu0FI->globalBaseRegFixed()))
return false;
bool Changed = false;
int FI = Cpu0FI->getGPFI();
for (MachineFunction::iterator MFI = F.begin(), MFE = F.end();
MFI != MFE; ++MFI) {
MachineBasicBlock& MBB = *MFI;
MachineBasicBlock::iterator I = MFI->begin();
/// isEHPad - Indicate that this basic block is entered via an
/// exception handler.
// If MBB is a landing pad, insert instruction that restores $gp after
// EH_LABEL.
if (MBB.isEHPad()) {
// Find EH_LABEL first.
for (; I->getOpcode() != TargetOpcode::EH_LABEL; ++I) ;
// Insert ld.
++I;
DebugLoc dl = I != MBB.end() ? I->getDebugLoc() : DebugLoc();
BuildMI(MBB, I, dl, TII->get(Cpu0::LD), Cpu0::GP).addFrameIndex(FI)
.addImm(0);
Changed = true;
}
while (I != MFI->end()) {
if (I->getOpcode() != Cpu0::JALR) {
++I;
continue;
}
DebugLoc dl = I->getDebugLoc();
// emit ld $gp, ($gp save slot on stack) after jalr
BuildMI(MBB, ++I, dl, TII->get(Cpu0::LD), Cpu0::GP).addFrameIndex(FI)
.addImm(0);
Changed = true;
}
}
return Changed;
}
/// createCpu0EmitGPRestorePass - Returns a pass that emits instructions that
/// restores $gp clobbered by jalr instructions.
FunctionPass *llvm::createCpu0EmitGPRestorePass(Cpu0TargetMachine &tm) {
return new Inserter(tm);
}
#endif
#endif
Variable number of arguments¶
Until now, we supported a fixed number of arguments in formal function definitions (Incoming Arguments). This subsection adds support for a variable number of arguments, as the C language allows this feature.
Run Chapter9_3/ with ch9_3_vararg.cpp and use the clang option
clang -target mips-unknown-linux-gnu to get the following result:
118-165-76-131:input Jonathan$ clang -target mips-unknown-linux-gnu -c
ch9_3_vararg.cpp -emit-llvm -o ch9_3_vararg.bc
118-165-76-131:input Jonathan$ /Users/Jonathan/llvm/test/
build/bin/llc -march=cpu0 -mcpu=cpu032I -cpu0-s32-calls=false
-relocation-model=pic -filetype=asm ch9_3_vararg.bc -o ch9_3_vararg.cpu0.s
118-165-76-131:input Jonathan$ cat ch9_3_vararg.cpu0.s
.section .mdebug.abi32
.previous
.file "ch9_3_vararg.bc"
.text
.globl _Z5sum_iiz
.align 2
.type _Z5sum_iiz,@function
.ent _Z5sum_iiz # @_Z5sum_iiz
_Z5sum_iiz:
.frame $fp,24,$lr
.mask 0x00001000,-4
.set noreorder
.set nomacro
# BB#0:
addiu $sp, $sp, -24
st $fp, 20($sp) # 4-byte Folded Spill
move $fp, $sp
ld $2, 24($fp) // amount
st $2, 16($fp) // amount
addiu $2, $zero, 0
st $2, 12($fp) // i
st $2, 8($fp) // val
st $2, 4($fp) // sum
addiu $3, $fp, 28
st $3, 0($fp) // arg_ptr = 2nd argument = &arg[1],
// since &arg[0] = 24($sp)
st $2, 12($fp)
$BB0_1: # =>This Inner Loop Header: Depth=1
ld $2, 16($fp)
ld $3, 12($fp)
cmp $sw, $3, $2 // compare(i, amount)
jge $BB0_4
nop
jmp $BB0_2
nop
$BB0_2: # in Loop: Header=BB0_1 Depth=1
// i < amount
ld $2, 0($fp)
addiu $3, $2, 4 // arg_ptr + 4
st $3, 0($fp)
ld $2, 0($2) // *arg_ptr
st $2, 8($fp)
ld $3, 4($fp) // sum
add $2, $3, $2 // sum += *arg_ptr
st $2, 4($fp)
# BB#3: # in Loop: Header=BB0_1 Depth=1
// i >= amount
ld $2, 12($fp)
addiu $2, $2, 1 // i++
st $2, 12($fp)
jmp $BB0_1
nop
$BB0_4:
ld $2, 4($fp)
move $sp, $fp
ld $fp, 20($sp) # 4-byte Folded Reload
addiu $sp, $sp, 24
ret $lr
.set macro
.set reorder
.end _Z5sum_iiz
$tmp1:
.size _Z5sum_iiz, ($tmp1)-_Z5sum_iiz
.globl _Z11test_varargv
.align 2
.type _Z11test_varargv,@function
.ent _Z11test_varargv # @_Z11test_varargv
_Z11test_varargv:
.frame $sp,88,$lr
.mask 0x00004000,-4
.set noreorder
.cpload $t9
.set nomacro
# BB#0:
addiu $sp, $sp, -48
st $lr, 44($sp) # 4-byte Folded Spill
st $fp, 40($sp) # 4-byte Folded Spill
move $fp, $sp
.cprestore 32
addiu $2, $zero, 5
st $2, 24($sp)
addiu $2, $zero, 4
st $2, 20($sp)
addiu $2, $zero, 3
st $2, 16($sp)
addiu $2, $zero, 2
st $2, 12($sp)
addiu $2, $zero, 1
st $2, 8($sp)
addiu $2, $zero, 0
st $2, 4($sp)
addiu $2, $zero, 6
st $2, 0($sp)
ld $t9, %call16(_Z5sum_iiz)($gp)
jalr $t9
nop
ld $gp, 28($fp)
st $2, 36($fp)
move $sp, $fp
ld $fp, 40($sp) # 4-byte Folded Reload
ld $lr, 44($sp) # 4-byte Folded Reload
addiu $sp, $sp, 48
ret $lr
nop
.set macro
.set reorder
.end _Z11test_varargv
$tmp1:
.size _Z11test_varargv, ($tmp1)-_Z11test_varargv
The analysis of output ch9_3_vararg.cpu0.s is shown in the comments above.
As described in the code in # BB#0, we get the first argument amount from
ld $2, 24($fp), since the stack size of the callee function _Z5sum_iiz() is
24. Then we set the argument pointer, arg_ptr, to 0($fp), which is
&arg[1].
Next, we check i < amount in block $BB0_1. If i < amount, we enter
$BB0_2. In $BB0_2, the code performs sum += *arg_ptr and
arg_ptr += 4. In # BB#3, the code increments i with i += 1.
To support variable numbers of arguments, the following code needs to be added in
Chapter9_3/.
The file ch9_3_template.cpp contains a C++ template example. It can also be
translated into Cpu0 backend code.
lbdex/chapters/Chapter9_3/Cpu0ISelLowering.h
class Cpu0TargetLowering : public TargetLowering {
/// Cpu0CC - This class provides methods used to analyze formal and call
/// arguments and inquire about calling convention information.
class Cpu0CC {
/// Return the function that analyzes variable argument list functions.
llvm::CCAssignFn *varArgFn() const;
...
. };
SDValue lowerVASTART(SDValue Op, SelectionDAG &DAG) const;
SDValue lowerFRAMEADDR(SDValue Op, SelectionDAG &DAG) const;
SDValue lowerRETURNADDR(SDValue Op, SelectionDAG &DAG) const;
SDValue lowerEH_RETURN(SDValue Op, SelectionDAG &DAG) const;
SDValue lowerADD(SDValue Op, SelectionDAG &DAG) const;
/// writeVarArgRegs - Write variable function arguments passed in registers
/// to the stack. Also create a stack frame object for the first variable
/// argument.
void writeVarArgRegs(std::vector<SDValue> &OutChains, const Cpu0CC &CC,
SDValue Chain, const SDLoc &DL, SelectionDAG &DAG) const;
...
. };
lbdex/chapters/Chapter9_3/Cpu0ISelLowering.cpp
Cpu0TargetLowering::Cpu0TargetLowering(const Cpu0TargetMachine &TM,
const Cpu0Subtarget &STI)
: TargetLowering(TM), Subtarget(STI), ABI(TM.getABI()) {
setOperationAction(ISD::VASTART, MVT::Other, Custom);
// Support va_arg(): variable numbers (not fixed numbers) of arguments
// (parameters) for function all
setOperationAction(ISD::VAARG, MVT::Other, Expand);
setOperationAction(ISD::VACOPY, MVT::Other, Expand);
setOperationAction(ISD::VAEND, MVT::Other, Expand);
//@llvm.stacksave
// Use the default for now
setOperationAction(ISD::STACKSAVE, MVT::Other, Expand);
setOperationAction(ISD::STACKRESTORE, MVT::Other, Expand);
...
}
SDValue Cpu0TargetLowering::
LowerOperation(SDValue Op, SelectionDAG &DAG) const
{
switch (Op.getOpcode())
{
case ISD::VASTART: return lowerVASTART(Op, DAG);
}
return SDValue();
}
SDValue Cpu0TargetLowering::lowerVASTART(SDValue Op, SelectionDAG &DAG) const {
MachineFunction &MF = DAG.getMachineFunction();
Cpu0FunctionInfo *FuncInfo = MF.getInfo<Cpu0FunctionInfo>();
SDLoc DL = SDLoc(Op);
SDValue FI = DAG.getFrameIndex(FuncInfo->getVarArgsFrameIndex(),
getPointerTy(MF.getDataLayout()));
// vastart just stores the address of the VarArgsFrameIndex slot into the
// memory location argument.
const Value *SV = cast<SrcValueSDNode>(Op.getOperand(2))->getValue();
return DAG.getStore(Op.getOperand(0), DL, FI, Op.getOperand(1),
MachinePointerInfo(SV));
}
/// LowerFormalArguments - transform physical registers into virtual registers
/// and generate load operations for arguments places on the stack.
SDValue
Cpu0TargetLowering::LowerFormalArguments(SDValue Chain,
CallingConv::ID CallConv,
bool IsVarArg,
const SmallVectorImpl<ISD::InputArg> &Ins,
const SDLoc &DL, SelectionDAG &DAG,
SmallVectorImpl<SDValue> &InVals)
const {
if (IsVarArg)
writeVarArgRegs(OutChains, Cpu0CCInfo, Chain, DL, DAG);
...
}
void Cpu0TargetLowering::Cpu0CC::
analyzeCallOperands(const SmallVectorImpl<ISD::OutputArg> &Args,
bool IsVarArg, bool IsSoftFloat, const SDNode *CallNode,
std::vector<ArgListEntry> &FuncArgs) {
llvm::CCAssignFn *VarFn = varArgFn();
for (unsigned I = 0; I != NumOpnds; ++I) {
if (IsVarArg && !Args[I].IsFixed)
R = VarFn(I, ArgVT, ArgVT, CCValAssign::Full, ArgFlags, CCInfo);
else
...
}
...
}
llvm::CCAssignFn *Cpu0TargetLowering::Cpu0CC::varArgFn() const {
if (IsO32)
return CC_Cpu0O32;
else // IsS32
return CC_Cpu0S32;
}
void Cpu0TargetLowering::writeVarArgRegs(std::vector<SDValue> &OutChains,
const Cpu0CC &CC, SDValue Chain,
const SDLoc &DL, SelectionDAG &DAG) const {
unsigned NumRegs = CC.numIntArgRegs();
const ArrayRef<MCPhysReg> ArgRegs = CC.intArgRegs();
const CCState &CCInfo = CC.getCCInfo();
unsigned Idx = CCInfo.getFirstUnallocated(ArgRegs);
unsigned RegSize = CC.regSize();
MVT RegTy = MVT::getIntegerVT(RegSize * 8);
const TargetRegisterClass *RC = getRegClassFor(RegTy);
MachineFunction &MF = DAG.getMachineFunction();
MachineFrameInfo &MFI = MF.getFrameInfo();
Cpu0FunctionInfo *Cpu0FI = MF.getInfo<Cpu0FunctionInfo>();
// Offset of the first variable argument from stack pointer.
int VaArgOffset;
if (NumRegs == Idx)
VaArgOffset = alignTo(CCInfo.getNextStackOffset(), RegSize);
else
VaArgOffset = (int)CC.reservedArgArea() - (int)(RegSize * (NumRegs - Idx));
// Record the frame index of the first variable argument
// which is a value necessary to VASTART.
int FI = MFI.CreateFixedObject(RegSize, VaArgOffset, true);
Cpu0FI->setVarArgsFrameIndex(FI);
// Copy the integer registers that have not been used for argument passing
// to the argument register save area. For O32, the save area is allocated
// in the caller's stack frame, while for N32/64, it is allocated in the
// callee's stack frame.
for (unsigned I = Idx; I < NumRegs; ++I, VaArgOffset += RegSize) {
unsigned Reg = addLiveIn(MF, ArgRegs[I], RC);
SDValue ArgValue = DAG.getCopyFromReg(Chain, DL, Reg, RegTy);
FI = MFI.CreateFixedObject(RegSize, VaArgOffset, true);
SDValue PtrOff = DAG.getFrameIndex(FI, getPointerTy(DAG.getDataLayout()));
SDValue Store = DAG.getStore(Chain, DL, ArgValue, PtrOff,
MachinePointerInfo());
cast<StoreSDNode>(Store.getNode())->getMemOperand()->setValue(
(Value *)nullptr);
OutChains.push_back(Store);
}
}
lbdex/input/ch9_3_template.cpp
#include <stdarg.h>
template<class T>
T sum(T amount, ...)
{
T i = 0;
T val = 0;
T sum = 0;
va_list vl;
va_start(vl, amount);
for (i = 0; i < amount; i++)
{
val = va_arg(vl, T);
sum += val;
}
va_end(vl);
return sum;
}
int test_template()
{
int a = (int)(sum<int>(6, 0, 1, 2, 3, 4, 5));
return a; // 15
}
long long test_template_ll()
{
long long a = (long long)(sum<long long>(6LL, 0LL, 1LL, 2LL, -3LL, 4LL, -5LL));
return a; // -1
}
MIPS QEMU reference [8] can be downloaded and run with GCC to verify the
result using the printf() function at this point.
We will verify the correctness of the code in the chapter “Verify backend on Verilog simulator” through the Cpu0 Verilog-language machine.
Dynamic stack allocation support¶
Even though the C language rarely uses dynamic stack allocation, some other languages rely on it frequently. The following C example demonstrates its use.
Chapter9_3 supports dynamic stack allocation with the following code added.
lbdex/chapters/Chapter9_2/Cpu0FrameLowering.cpp
// Eliminate ADJCALLSTACKDOWN, ADJCALLSTACKUP pseudo instructions
MachineBasicBlock::iterator Cpu0FrameLowering::
eliminateCallFramePseudoInstr(MachineFunction &MF, MachineBasicBlock &MBB,
MachineBasicBlock::iterator I) const {
#if CH >= CH9_3 // dynamic alloc
unsigned SP = Cpu0::SP;
if (!hasReservedCallFrame(MF)) {
int64_t Amount = I->getOperand(0).getImm();
if (I->getOpcode() == Cpu0::ADJCALLSTACKDOWN)
Amount = -Amount;
STI.getInstrInfo()->adjustStackPtr(SP, Amount, MBB, I);
}
#endif // dynamic alloc
return MBB.erase(I);
}
lbdex/chapters/Chapter9_3/Cpu0SEFrameLowering.cpp
void Cpu0SEFrameLowering::emitPrologue(MachineFunction &MF,
MachineBasicBlock &MBB) const {
unsigned FP = Cpu0::FP;
unsigned ZERO = Cpu0::ZERO;
unsigned ADDu = Cpu0::ADDu;
// if framepointer enabled, set it to point to the stack pointer.
if (hasFP(MF)) {
if (Cpu0FI->callsEhDwarf()) {
BuildMI(MBB, MBBI, dl, TII.get(ADDu), Cpu0::V0).addReg(FP).addReg(ZERO)
.setMIFlag(MachineInstr::FrameSetup);
}
//@ Insert instruction "move $fp, $sp" at this location.
BuildMI(MBB, MBBI, dl, TII.get(ADDu), FP).addReg(SP).addReg(ZERO)
.setMIFlag(MachineInstr::FrameSetup);
// emit ".cfi_def_cfa_register $fp"
unsigned CFIIndex = MF.addFrameInst(MCCFIInstruction::createDefCfaRegister(
nullptr, MRI->getDwarfRegNum(FP, true)));
BuildMI(MBB, MBBI, dl, TII.get(TargetOpcode::CFI_INSTRUCTION))
.addCFIIndex(CFIIndex);
}
}
void Cpu0SEFrameLowering::emitEpilogue(MachineFunction &MF,
MachineBasicBlock &MBB) const {
unsigned FP = Cpu0::FP;
unsigned ZERO = Cpu0::ZERO;
unsigned ADDu = Cpu0::ADDu;
// if framepointer enabled, restore the stack pointer.
if (hasFP(MF)) {
// Find the first instruction that restores a callee-saved register.
MachineBasicBlock::iterator I = MBBI;
for (unsigned i = 0; i < MFI.getCalleeSavedInfo().size(); ++i)
--I;
// Insert instruction "move $sp, $fp" at this location.
BuildMI(MBB, I, DL, TII.get(ADDu), SP).addReg(FP).addReg(ZERO);
}
}
unsigned FP = Cpu0::FP;
// Mark $fp as used if function has dedicated frame pointer.
if (hasFP(MF))
setAliasRegs(MF, SavedRegs, FP);
lbdex/chapters/Chapter9_3/Cpu0ISelLowering.cpp
Cpu0TargetLowering::Cpu0TargetLowering(const Cpu0TargetMachine &TM,
const Cpu0Subtarget &STI)
: TargetLowering(TM), Subtarget(STI), ABI(TM.getABI()) {
setOperationAction(ISD::DYNAMIC_STACKALLOC, MVT::i32, Expand);
setStackPointerRegisterToSaveRestore(Cpu0::SP);
}
lbdex/chapters/Chapter9_3/Cpu0RegisterInfo.cpp
BitVector Cpu0RegisterInfo::
getReservedRegs(const MachineFunction &MF) const {
// Reserve FP if this function should have a dedicated frame pointer register.
if (MF.getSubtarget().getFrameLowering()->hasFP(MF)) {
Reserved.set(Cpu0::FP);
}
}
//- If no eliminateFrameIndex(), it will hang on run.
// pure virtual method
// FrameIndex represent objects inside a abstract stack.
// We must replace FrameIndex with an stack/frame pointer
// direct reference.
void Cpu0RegisterInfo::
eliminateFrameIndex(MachineBasicBlock::iterator II, int SPAdj,
unsigned FIOperandNum, RegScavenger *RS) const {
if (Cpu0FI->isOutArgFI(FrameIndex) || Cpu0FI->isGPFI(FrameIndex) ||
Cpu0FI->isDynAllocFI(FrameIndex))
Offset = spOffset;
}
Run Chapter9_3 with ch9_3_alloc.cpp to get the following correct result.
118-165-72-242:input Jonathan$ clang -target mips-unknown-linux-gnu -c
ch9_3_alloc.cpp -emit-llvm -o ch9_3_alloc.bc
118-165-72-242:input Jonathan$ llvm-dis ch9_3_alloc.bc -o ch9_3_alloc.ll
118-165-72-242:input Jonathan$ cat ch9_3_alloc.ll
; ModuleID = 'ch9_3_alloc.bc'
target datalayout = "e-p:64:64:64-i1:8:8-i8:8:8-i16:16:16-i32:32:32-i64:64:64-
f32:32:32-f64:64:64-v64:64:64-v128:128:128-a0:0:64-s0:64:64-f80:128:128-n8:16:
32:64-S128"
target triple = "x86_64-apple-macosx10.8.0"
define i32 @_Z5sum_iiiiiii(i32 %x1, i32 %x2, i32 %x3, i32 %x4, i32 %x5, i32 %x6)
nounwind uwtable ssp {
...
%9 = alloca i8, i32 %8 // int* b = (int*)__builtin_alloca(sizeof(int) * 1 * x1);
%10 = bitcast i8* %9 to i32*
store i32* %10, i32** %b, align 4
...
}
...
118-165-72-242:input Jonathan$ /Users/Jonathan/llvm/test/build/
bin/llc -march=cpu0 -mcpu=cpu032I -cpu0-s32-calls=false
-relocation-model=pic -filetype=asm ch9_3_alloc.bc -o ch9_3_alloc.cpu0.s
118-165-72-242:input Jonathan$ cat ch9_3_alloc.cpu0.s
...
.globl _Z10weight_sumiiiiii
.align 2
.type _Z10weight_sumiiiiii,@function
.ent _Z10weight_sumiiiiii # @_Z10weight_sumiiiiii
_Z10weight_sumiiiiii:
.frame $fp,48,$lr
.mask 0x00005000,-4
.set noreorder
.cpload $t9
.set nomacro
# BB#0:
addiu $sp, $sp, -48
st $lr, 44($sp) # 4-byte Folded Spill
st $fp, 40($sp) # 4-byte Folded Spill
move $fp, $sp
.cprestore 24
ld $2, 68($fp)
ld $3, 64($fp)
ld $t9, 60($fp)
ld $7, 56($fp)
st $4, 36($fp)
st $5, 32($fp)
st $7, 28($fp)
st $t9, 24($fp)
st $3, 20($fp)
st $2, 16($fp)
shl $2, $2, 2 // $2 = sizeof(int) * 1 * x2;
addiu $2, $2, 7
addiu $3, $zero, -8
and $2, $2, $3
addiu $sp, $sp, 0
subu $2, $sp, $2
addu $sp, $zero, $2 // set sp to the bottom of alloca area
addiu $sp, $sp, 0
st $2, 12($fp)
st $2, 8($fp)
ld $2, 12($fp)
ld $3, 28($fp)
st $3, 0($2) // *b = x3
ld $5, 32($fp)
ld $2, 36($fp)
ld $3, 20($fp)
ld $4, 28($fp)
ld $t9, 24($fp)
ld $7, 16($fp)
addiu $sp, $sp, -24
st $7, 20($sp)
st $t9, 12($sp)
st $4, 8($sp)
shl $3, $3, 1
st $3, 16($sp)
addiu $3, $zero, 3
mul $4, $2, $3
ld $t9, %call16(_Z3sumiiiiii)($gp)
jalr $t9
nop
ld $gp, 24($fp)
addiu $sp, $sp, 24
st $2, 4($fp)
ld $3, 8($fp)
ld $3, 0($3)
addu $2, $2, $3
move $sp, $fp
ld $fp, 40($sp) # 4-byte Folded Reload
ld $lr, 44($sp) # 4-byte Folded Reload
addiu $sp, $sp, 48
ret $lr
nop
.set macro
.set reorder
.end _Z10weight_sumiiiiii
$func_end1:
.size _Z10weight_sumiiiiii, ($func_end1)-_Z10weight_sumiiiiii
...
As you can see, dynamic stack allocation requires frame pointer register fp
support. As shown in the assembly above, the sp is adjusted to sp - 48
when entering the function by the instruction addiu $sp, $sp, -48.
Next, fp is set to sp, which is positioned just above the area allocated
by alloca(), as illustrated in Fig. 46, when the instruction
move $fp, $sp is encountered.
After that, sp is moved to the space just below the alloca() allocation.
Note that the space pointed to by b,
*b = (int*)__builtin_alloca(sizeof(int) * 2 * x6), is allocated at run time,
because the size depends on the x1 variable and cannot be determined at link
time.
Fig. 47 illustrates how the stack pointer is restored to the
caller’s stack bottom. As described above, fp is set to the address just
above the alloca() area.
The first step restores sp from fp using the instruction move $sp, $fp.
Next, sp is adjusted back to the caller’s stack bottom using
addiu $sp, $sp, 40.
Fig. 46 Frame pointer changes when enter function¶
Fig. 47 Stack pointer changes when exit function¶
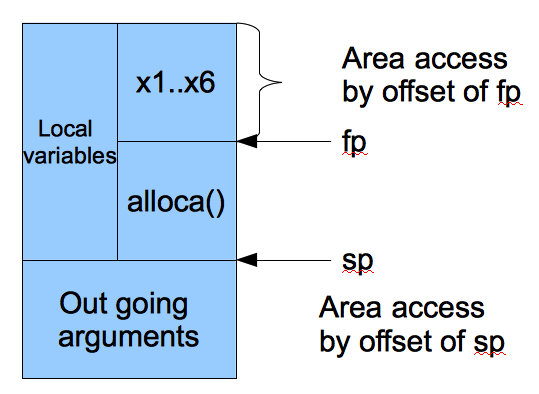
Fig. 48 fp and sp access areas¶
Using fp to keep the old stack pointer value is not the only solution.
In fact, we can store the size of the alloca() spaces at a specific memory
address and restore sp to its previous value by adding back the size of the
alloca() area.
Most ABIs, such as MIPS and ARM, access the area above alloca() using fp
and the area below alloca() using sp, as depicted in Fig. 48.
The reason for this design is performance in accessing local variables. Since
RISC CPUs commonly use immediate offsets for load and store instructions, using
both fp and sp to access the two separate areas of local variables
provides better performance compared to using only sp.
ld $2, 64($fp)
st $3, 4($sp)
Cpu0 uses fp and sp to access the areas above and below alloca(),
respectively. As shown in ch9_3_alloc.cpu0.s, it accesses local variables
(above the alloca() area) using fp offset, and accesses outgoing
arguments (below the alloca() area) using sp offset.
Additionally, the instruction move $sp, $fp is an alias for the actual
machine instruction addu $fp, $sp, $zero. The machine code emitted is the
latter, while the former is used for easier readability by users.
This alias is defined by the code added in Chapter3_2 and Chapter3_5, as shown below:
lbdex/chapters/Chapter3_2/InstPrinter/Cpu0InstPrinter.cpp
void Cpu0InstPrinter::printInst(const MCInst *MI, uint64_t Address,
StringRef Annot, const MCSubtargetInfo &STI,
raw_ostream &O) {
// Try to print any aliases first.
if (!printAliasInstr(MI, Address, O))
lbdex/chapters/Chapter3_5/Cpu0InstrInfo.td
class Cpu0InstAlias<string Asm, dag Result, bit Emit = 0b1> :
InstAlias<Asm, Result, Emit>;
let Predicates = [Ch3_5] in {
//===----------------------------------------------------------------------===//
// Instruction aliases
//===----------------------------------------------------------------------===//
def : Cpu0InstAlias<"move $dst, $src",
(ADDu GPROut:$dst, GPROut:$src,ZERO), 1>;
}
Finally, the MFI->hasVarSizedObjects() defined in hasReservedCallFrame()
of Cpu0SEFrameLowering.cpp is set to true when the IR contains
%9 = alloca i8, i32 %8, which corresponds to
(int*)__builtin_alloca(sizeof(int) * 1 * x1); in C code.
This triggers generation of the assembly instruction addiu $sp, $sp, -24
for ch9_3_alloc.cpp by invoking adjustStackPtr() inside
eliminateCallFramePseudoInstr() of Cpu0FrameLowering.cpp.
The file ch9_3_longlongshift.cpp demonstrates support for the type
long long shift operations, which can be tested now as shown below.
lbdex/input/ch9_3_longlongshift.cpp
#include "debug.h"
long long test_longlong_shift1()
{
long long a = 4;
long long b = 0x12;
long long c;
long long d;
c = (b >> a); // cc = 0x1
d = (b << a); // cc = 0x120
long long e = 0x7FFFFFFFFFFFFFFLL >> 63;
return (c+d+e); // 0x121 = 289
}
long long test_longlong_shift2()
{
long long a = 48;
long long b = 0x001666660000000a;
long long c;
c = (b >> a);
return c; // 22
}
114-37-150-209:input Jonathan$ clang -O0 -target mips-unknown-linux-gnu
-c ch9_3_longlongshift.cpp -emit-llvm -o ch9_3_longlongshift.bc
114-37-150-209:input Jonathan$ ~/llvm/test/build/bin/
llvm-dis ch9_3_longlongshift.bc -o -
...
; Function Attrs: nounwind
define i64 @_Z19test_longlong_shiftv() #0 {
%a = alloca i64, align 8
%b = alloca i64, align 8
%c = alloca i64, align 8
%d = alloca i64, align 8
store i64 4, i64* %a, align 8
store i64 18, i64* %b, align 8
%1 = load i64* %b, align 8
%2 = load i64* %a, align 8
%3 = ashr i64 %1, %2
store i64 %3, i64* %c, align 8
%4 = load i64* %b, align 8
%5 = load i64* %a, align 8
%6 = shl i64 %4, %5
store i64 %6, i64* %d, align 8
%7 = load i64* %c, align 8
%8 = load i64* %d, align 8
%9 = add nsw i64 %7, %8
ret i64 %9
}
...
114-37-150-209:input Jonathan$ ~/llvm/test/build/bin/llc
-march=cpu0 -mcpu=cpu032I -relocation-model=static -filetype=asm
ch9_3_longlongshift.bc -o -
.text
.section .mdebug.abi32
.previous
.file "ch9_3_longlongshift.bc"
.globl _Z20test_longlong_shift1v
.align 2
.type _Z20test_longlong_shift1v,@function
.ent _Z20test_longlong_shift1v # @_Z20test_longlong_shift1v
_Z20test_longlong_shift1v:
.frame $fp,56,$lr
.mask 0x00005000,-4
.set noreorder
.set nomacro
# BB#0:
addiu $sp, $sp, -56
st $lr, 52($sp) # 4-byte Folded Spill
st $fp, 48($sp) # 4-byte Folded Spill
move $fp, $sp
addiu $2, $zero, 4
st $2, 44($fp)
addiu $4, $zero, 0
st $4, 40($fp)
addiu $5, $zero, 18
st $5, 36($fp)
st $4, 32($fp)
ld $2, 44($fp)
st $2, 8($sp)
jsub __lshrdi3
nop
st $3, 28($fp)
st $2, 24($fp)
ld $2, 44($fp)
st $2, 8($sp)
ld $4, 32($fp)
ld $5, 36($fp)
jsub __ashldi3
nop
st $3, 20($fp)
st $2, 16($fp)
ld $4, 28($fp)
addu $4, $4, $3
cmp $sw, $4, $3
andi $3, $sw, 1
addu $2, $3, $2
ld $3, 24($fp)
addu $2, $3, $2
addu $3, $zero, $4
move $sp, $fp
ld $fp, 48($sp) # 4-byte Folded Reload
ld $lr, 52($sp) # 4-byte Folded Reload
addiu $sp, $sp, 56
ret $lr
nop
.set macro
.set reorder
.end _Z20test_longlong_shift1v
$tmp0:
.size _Z20test_longlong_shift1v, ($tmp0)-_Z20test_longlong_shift1v
.globl _Z20test_longlong_shift2v
.align 2
.type _Z20test_longlong_shift2v,@function
.ent _Z20test_longlong_shift2v # @_Z20test_longlong_shift2v
_Z20test_longlong_shift2v:
.frame $fp,48,$lr
.mask 0x00005000,-4
.set noreorder
.set nomacro
# BB#0:
addiu $sp, $sp, -48
st $lr, 44($sp) # 4-byte Folded Spill
st $fp, 40($sp) # 4-byte Folded Spill
move $fp, $sp
addiu $2, $zero, 48
st $2, 36($fp)
addiu $2, $zero, 0
st $2, 32($fp)
addiu $5, $zero, 10
st $5, 28($fp)
lui $2, 22
ori $4, $2, 26214
st $4, 24($fp)
ld $2, 36($fp)
st $2, 8($sp)
jsub __lshrdi3
nop
st $3, 20($fp)
st $2, 16($fp)
move $sp, $fp
ld $fp, 40($sp) # 4-byte Folded Reload
ld $lr, 44($sp) # 4-byte Folded Reload
addiu $sp, $sp, 48
ret $lr
nop
.set macro
.set reorder
.end _Z20test_longlong_shift2v
$tmp1:
.size _Z20test_longlong_shift2v, ($tmp1)-_Z20test_longlong_shift2v
Variable sized array support¶
LLVM supports variable sized arrays (VLA) as introduced in C99 [9] [10]. The following code is added to support this feature. These intrinsics are set to expand, meaning LLVM replaces them with other DAG nodes during code generation.
lbdex/chapters/Chapter9_3/Cpu0ISelLowering.cpp
SDValue Cpu0TargetLowering::
LowerOperation(SDValue Op, SelectionDAG &DAG) const
{
switch (Op.getOpcode())
{
// Use the default for now
setOperationAction(ISD::STACKSAVE, MVT::Other, Expand);
setOperationAction(ISD::STACKRESTORE, MVT::Other, Expand);
...
}
...
}
lbdex/input/ch9_3_stacksave.cpp
int test_stacksaverestore(unsigned x) {
// CHECK: call i8* @llvm.stacksave()
char s1[x];
s1[x] = 5;
return s1[x];
// CHECK: call void @llvm.stackrestore(i8*
}
JonathantekiiMac:input Jonathan$ clang -target mips-unknown-linux-gnu -c
ch9_3_stacksave.cpp -emit-llvm -o ch9_3_stacksave.bc
JonathantekiiMac:input Jonathan$ llvm-dis ch9_3_stacksave.bc -o -
define i32 @_Z21test_stacksaverestorej(i32 zeroext %x) #0 {
%1 = alloca i32, align 4
%2 = alloca i8*
%3 = alloca i32
store i32 %x, i32* %1, align 4
%4 = load i32, i32* %1, align 4
%5 = call i8* @llvm.stacksave()
store i8* %5, i8** %2
%6 = alloca i8, i32 %4, align 1
%7 = load i32, i32* %1, align 4
%8 = getelementptr inbounds i8, i8* %6, i32 %7
store i8 5, i8* %8, align 1
%9 = load i32, i32* %1, align 4
%10 = getelementptr inbounds i8, i8* %6, i32 %9
%11 = load i8, i8* %10, align 1
%12 = sext i8 %11 to i32
store i32 1, i32* %3
%13 = load i8*, i8** %2
call void @llvm.stackrestore(i8* %13)
ret i32 %12
}
JonathantekiiMac:input Jonathan$ ~/llvm/test/build/bin/llc
-march=cpu0 -mcpu=cpu032I -relocation-model=static -filetype=asm
ch9_3_stacksave.bc -o -
...
Add specific backend intrinsic function¶
LLVM intrinsic functions are designed to extend LLVM IRs for hardware acceleration in compiler design [16]. Many CPUs implement their own intrinsic functions for hardware-specific instructions that improve performance.
Some GPUs use the LLVM infrastructure as their OpenGL/OpenCL backend compiler and rely on many LLVM-extended intrinsic functions.
To demonstrate how to use backend proprietary intrinsic functions to support
specific instructions for performance improvement in domain-specific languages,
Cpu0 adds an intrinsic function @llvm.cpu0.gcd for its
greatest common divisor (GCD) instruction.
This instruction demonstrates how to implement a custom intrinsic in LLVM; however, it is not implemented in the Verilog Cpu0 hardware.
The code is as follows,
lbdex/llvm/modify/llvm/include/llvm/IR/Intrinsics.td
...
include "llvm/IR/IntrinsicsCpu0.td"
...
lbdex/llvm/modify/llvm/include/llvm/IR/IntrinsicsCpu0.td
//===- IntrinsicsCpu0.td - Defines Mips intrinsics ---------*- tablegen -*-===//
//
// The LLVM Compiler Infrastructure
//
// This file is distributed under the University of Illinois Open Source
// License. See LICENSE.TXT for details.
//
//===----------------------------------------------------------------------===//
//
// This file defines all of the CPU0-specific intrinsics.
//
//===----------------------------------------------------------------------===//
// __builtin_cpu0_gcd defined in
// https://github.com/Jonathan2251/lbt/blob/master/exlbt/clang/include/clang/Basic/BuiltinsCpu0.def
def int_cpu0_gcd : GCCBuiltin<"__builtin_cpu0_gcd">,
Intrinsic<[llvm_i32_ty], [llvm_i32_ty, llvm_i32_ty],
[Commutative, IntrNoMem]>;
lbdex/chapters/Chapter9_3/Cpu0InstrInfo.td
class IntrinArithLogicR<bits<8> op, string instr_asm, SDPatternOperator OpNode,
InstrItinClass itin, RegisterClass RC, bit isComm = 0>:
FA<op, (outs GPROut:$ra), (ins RC:$rb, RC:$rc),
!strconcat(instr_asm, "\t$ra, $rb, $rc"),
[(set GPROut:$ra, (OpNode RC:$rb, RC:$rc))], itin> {
let shamt = 0;
let isCommutable = isComm; // e.g. add rb rc = add rc rb
let isReMaterializable = 1;
}
def GCD : IntrinArithLogicR<0x60, "gcd", int_cpu0_gcd, IIAlu, CPURegs, 1>;
When running llc with cpu0_gcd.ll, it generates the gcd machine
instruction. Meanwhile, running cpu0_gcd_soft.ll results in a call to the
cpu0_gcd_soft function.
In other words, @llvm.cpu0.gcd is an intrinsic function mapped to the gcd
machine instruction, while @cpu0_gcd_soft is a regular function implemented
in software.
For undefined intrinsic functions in Cpu0, such as fmul float %0, %1, LLVM
will compile them into function calls like jsub fmul for Cpu0
[17].
The file test_memcpy.ll is an example of an IntrWriteMem instruction,
which prevents the operation from being optimized out.
Summary¶
Now, the Cpu0 backend can handle both integer function calls and control statements, similar to the example code in the LLVM frontend tutorial.
It can also translate some of the C++ object-oriented programming language into Cpu0 instructions without much additional backend effort, because the frontend handles most of the complexity for meeting C++ requirement.
LLVM is a well-structured system that follows compiler theory closely. Any backend of LLVM benefits from this structure.
The best part of the three-tier compiler architecture is that backends will automatically support more languages as the frontend expands its language support, as long as no new IRs are introduced.