Control flow statements¶
This chapter illustrates the corresponding IR for control flow statements, such as “if-else”, “while”, and “for” loop statements in C. It also explains how to translate these LLVM IR control flow statements into Cpu0 instructions in Section I.
In section Cpu0 Backend Optimization: Remove Useless JMP, a control flow optimization pass for the backend is introduced. It serves as a simple tutorial program to help readers understand how to add and implement a backend optimization pass.
Section Conditional Instruction includes handling for conditional instructions, since Clang generates specific IR instructions, select and select_cc, to support control flow optimizations in the backend.
Pipeline architecture¶
The following figures are from the book Computer Architecture: A Quantitative Approach, Fourth Edition.
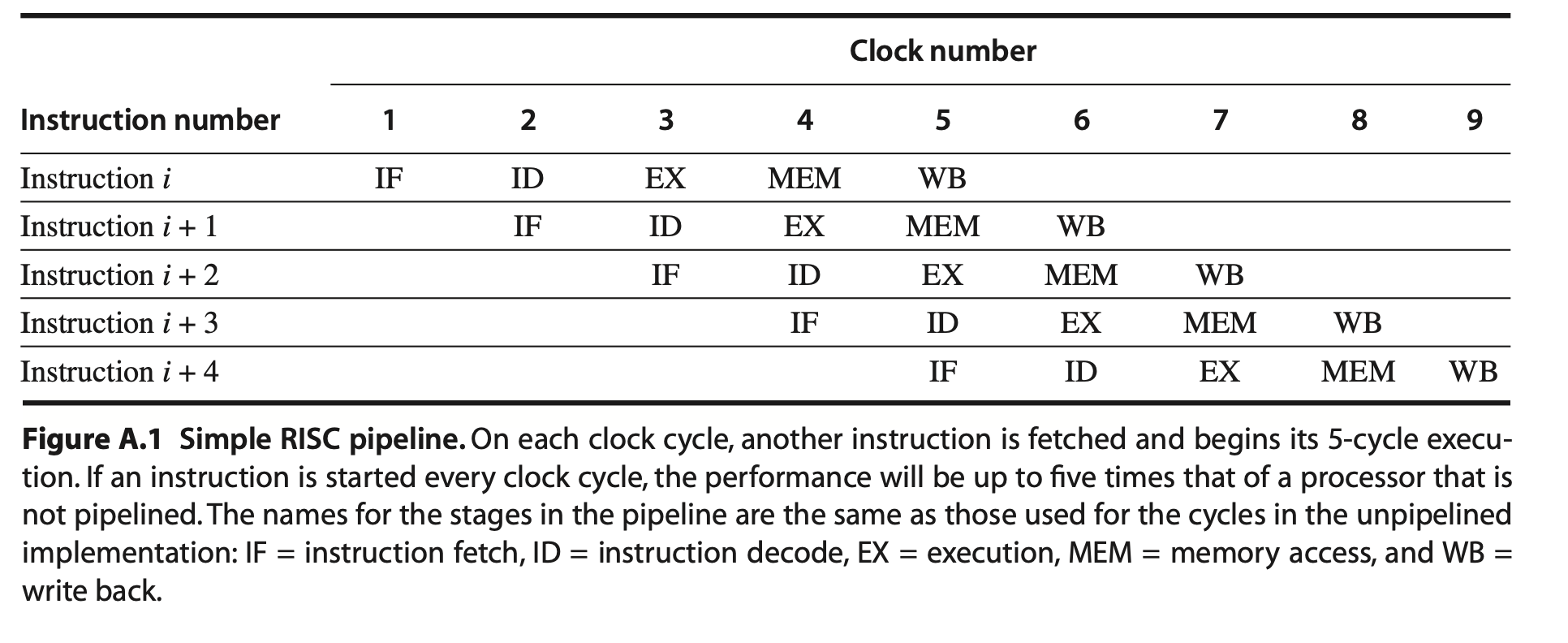
Fig. 35 5 stages of pipeline¶
IF: Instruction Fetch cycle
ID: Instruction Decode/Register Fetch cycle
EX: Execution/Effective Address cycle
MEM: Memory Access cycle
WB: Write-Back cycle
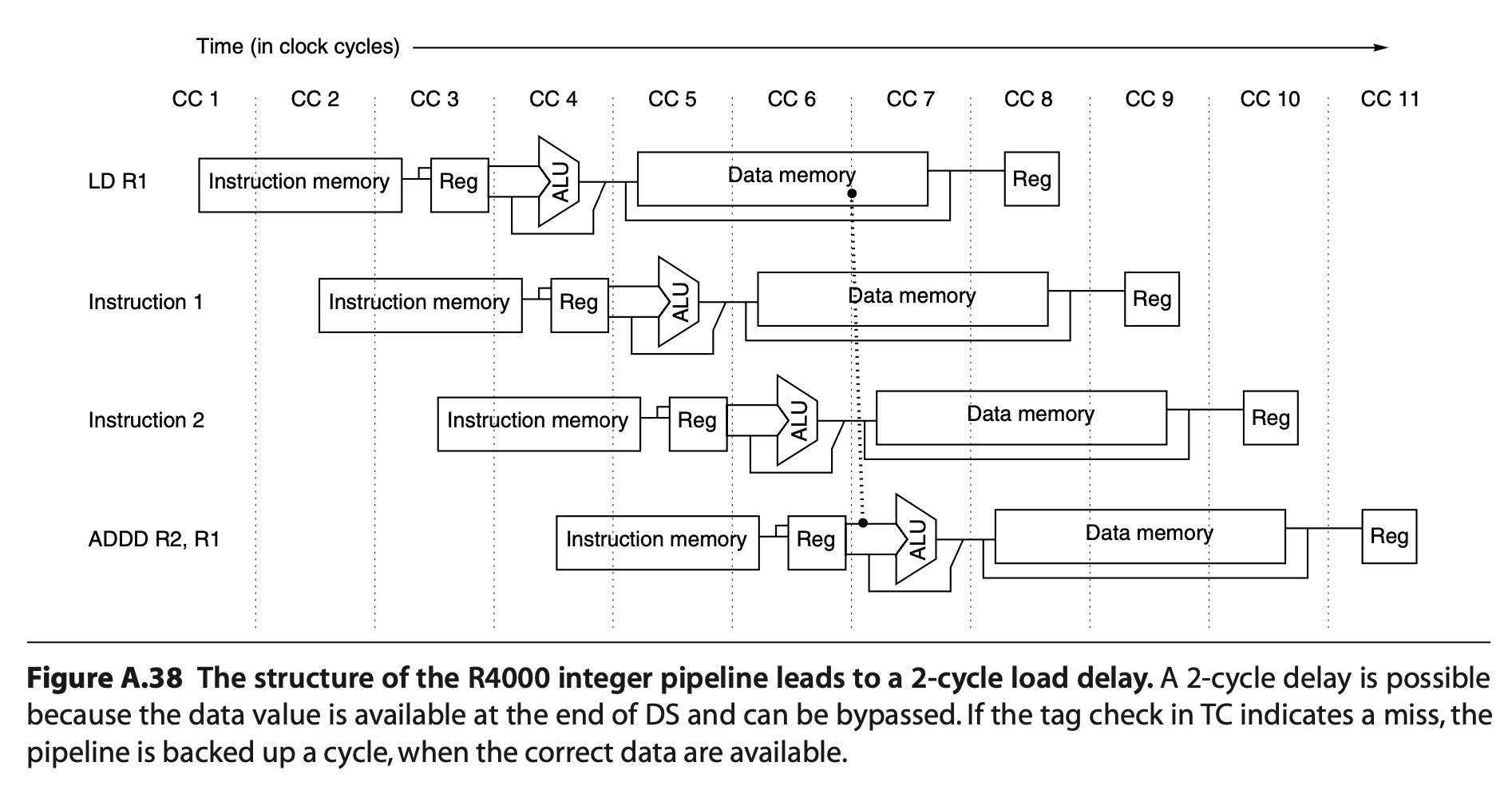
Fig. 36 Super pipeline¶
Multibanked caches (see Fig. 37) are used to increase cache bandwidth.
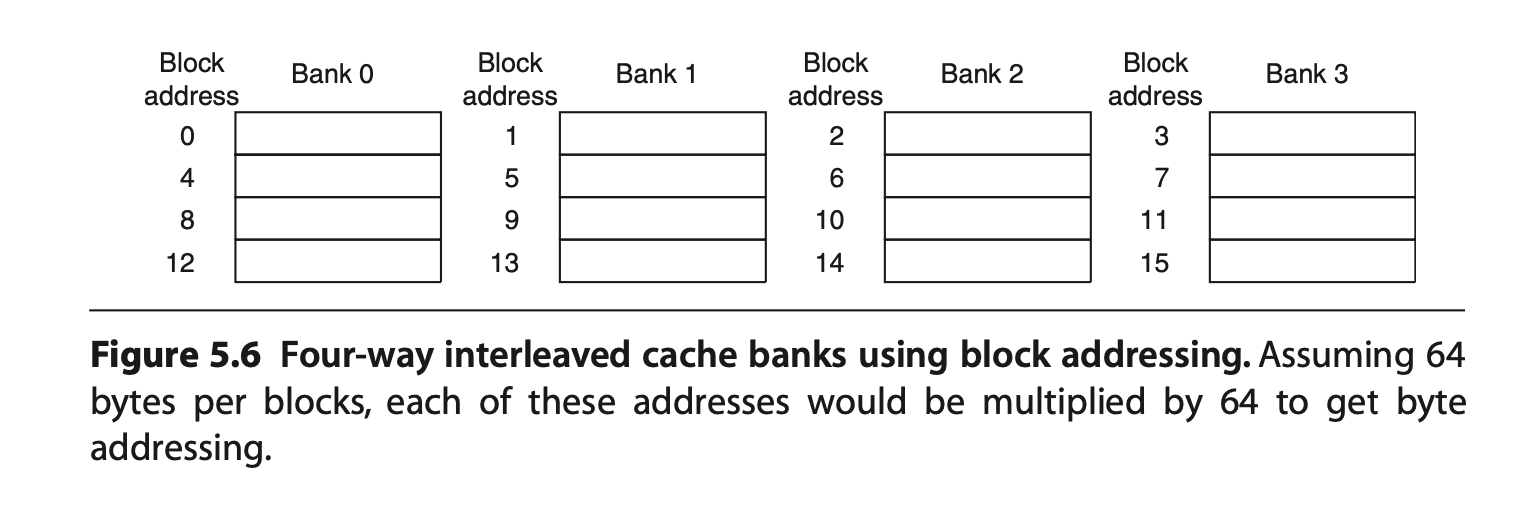
Fig. 37 Interleaved cache banks¶
The block size in L1 cache is usually between 16 and 256 bytes. Equipped with multibanked caches, a system can support super-pipelined (Fig. 36) and superscalar (multi-issue pipeline) architectures, allowing the fetch of (4 * block_size / instruction_size) instructions per cycle.
Control flow statement¶
Running ch8_1_1.cpp with Clang will produce the following result:
lbdex/input/ch8_1_1.cpp
int test_ifctrl()
{
unsigned int a = 0;
if (a == 0) {
a++; // a = 1
}
return a;
}
...
%0 = load i32* %a, align 4
%cmp = icmp eq i32 %0, 0
br i1 %cmp, label %if.then, label %if.end
; <label>:3: ; preds = %0
%1 = load i32* %a, align 4
%inc = add i32 %1, 1
store i32 %inc, i32* %a, align 4
br label %if.end
...
The “icmp ne” stands for integer compare NotEqual, “slt” stands for Set Less Than, and “sle” stands for Set Less or Equal.
Run version Chapter8_1/ with the llc -view-isel-dags or -debug option.
You will see that the if statement is translated into the form:
br (brcond (%1, setcc(%2, Constant<c>, setne)), BasicBlock_02), BasicBlock_01
If we ignore %1, it simplifies to:
br (brcond (setcc(%2, Constant<c>, setne)), BasicBlock_02), BasicBlock_01
For explanation, the corresponding IR DAG is listed as follows:
Optimized legalized selection DAG: BB#0 '_Z11test_ifctrlv:entry'
SelectionDAG has 12 nodes:
...
t5: i32,ch = load<Volatile LD4[%a]> t4, FrameIndex:i32<0>, undef:i32
t16: i32 = setcc t5, Constant:i32<0>, setne:ch
t11: ch = brcond t5:1, t16, BasicBlock:ch<if.end 0x10305a338>
t13: ch = br t11, BasicBlock:ch<if.then 0x10305a288>
We want to translate them into Cpu0 instruction DAGs as follows:
addiu %3, ZERO, Constant<c>
cmp %2, %3
jne BasicBlock_02
jmp BasicBlock_01
For the last IR br, we translate the unconditional branch (br BasicBlock_01) into jmp BasicBlock_01 using the following pattern definition:
lbdex/chapters/Chapter8_1/Cpu0InstrInfo.td
// Unconditional branch, such as JMP
let Predicates = [Ch8_1] in {
class UncondBranch<bits<8> op, string instr_asm>:
FJ<op, (outs), (ins jmptarget:$addr),
!strconcat(instr_asm, "\t$addr"), [(br bb:$addr)], IIBranch> {
let isBranch = 1;
let isTerminator = 1;
let isBarrier = 1;
let hasDelaySlot = 0;
}
}
...
def JMP : UncondBranch<0x26, "jmp">;
The pattern [(br bb:$imm24)] in class UncondBranch is translated into the
jmp machine instruction.
The translation for the pair of Cpu0 instructions, cmp and jne, has not been handled prior to this chapter.
To support this chained IR-to-machine-instruction translation, we define the following pattern:
lbdex/chapters/Chapter8_1/Cpu0InstrInfo.td
// brcond patterns
multiclass BrcondPatsCmp<RegisterClass RC, Instruction JEQOp, Instruction JNEOp,
Instruction JLTOp, Instruction JGTOp, Instruction JLEOp, Instruction JGEOp,
Instruction CMPOp> {
...
def : Pat<(brcond (i32 (setne RC:$lhs, RC:$rhs)), bb:$dst),
(JNEOp (CMPOp RC:$lhs, RC:$rhs), bb:$dst)>;
...
def : Pat<(brcond RC:$cond, bb:$dst),
(JNEOp (CMPOp RC:$cond, ZEROReg), bb:$dst)>;
...
}
Since the above BrcondPats pattern uses RC (Register Class) as an operand, the following ADDiu pattern defined in Chapter 2 will generate the instruction addiu before the cmp instruction for the first IR, setcc(%2, Constant<c>, setne), as shown above.
lbdex/chapters/Chapter2/Cpu0InstrInfo.td
// Small immediates
def : Pat<(i32 immSExt16:$in),
(ADDiu ZERO, imm:$in)>;
The definition of BrcondPats supports setne, seteq, setlt, and other register operand compares, as well as setult, setugt, and others for unsigned integer types.
In addition to seteq and setne, we define setueq and setune by referring to MIPS code, although we have not found how to generate setune IR from C language.
We have tried to define unsigned int types, but Clang still generates setne instead of setune.
The order of pattern search follows their order of appearance in the context.
The last pattern
(brcond RC:$cond, bb:$dst)
means branch to $dst if $cond != 0. Therefore, we set the corresponding translation to:
(JNEOp (CMPOp RC:$cond, ZEROReg), bb:$dst)
The CMP instruction sets the result to register SW, and then JNE checks the condition based on the SW status as shown in Fig. 38.
Since SW belongs to a different register class, the translation remains correct even if an instruction is inserted between CMP and JNE, as follows:
Fig. 38 JNE (CMP $r2, $r3),¶
cmp %2, %3
addiu $r1, $r2, 3 // $r1 register never be allocated to $SW because in
// class ArithLogicI, GPROut is the output register
// class and the GPROut is defined without $SW in
// Cpu0RegisterInforGPROutForOther.td
jne BasicBlock_02
The reserved registers are set by the following function code that we defined previously:
lbdex/chapters/Chapter3_1/Cpu0RegisterInfo.cpp
BitVector Cpu0RegisterInfo::
getReservedRegs(const MachineFunction &MF) const {
//@getReservedRegs body {
static const uint16_t ReservedCPURegs[] = {
Cpu0::ZERO, Cpu0::AT, Cpu0::SP, Cpu0::LR, /*Cpu0::SW, */Cpu0::PC
};
BitVector Reserved(getNumRegs());
for (unsigned I = 0; I < array_lengthof(ReservedCPURegs); ++I)
Reserved.set(ReservedCPURegs[I]);
return Reserved;
}
Although the following definition in Cpu0RegisterInfo.td has no real effect on reserved registers, it is better to comment the reserved registers in it for readability.
Setting SW in both register classes CPURegs and SR allows access to SW
by RISC instructions like andi, and also lets programmers use traditional
assembly instructions like cmp.
The copyPhysReg() function is called when both DestReg and SrcReg belong to different register classes.
lbdex/chapters/Chapter2/Cpu0RegisterInfo.td
//===----------------------------------------------------------------------===//
def CPURegs : RegisterClass<"Cpu0", [i32], 32, (add
// Reserved
ZERO, AT,
// Return Values and Arguments
V0, V1, A0, A1,
// Not preserved across procedure calls
T9, T0, T1,
// Callee save
S0, S1,
// Reserved
GP, FP,
SP, LR, SW)>;
def SR : RegisterClass<"Cpu0", [i32], 32, (add SW)>;
lbdex/chapters/Chapter2/Cpu0RegisterInfoGPROutForOther.td
//===----------------------------------------------------------------------===//
// Register Classes
//===----------------------------------------------------------------------===//
def GPROut : RegisterClass<"Cpu0", [i32], 32, (add (sub CPURegs, SW))>;
Chapter8_1/ includes support for control flow statements.
Run it along with the following llc option to generate the object file.
Dump its content using gobjdump or hexdump as shown below:
118-165-79-206:input Jonathan$ /Users/Jonathan/llvm/test/
build/bin/llc -march=cpu0 -mcpu=cpu032I -relocation-model=pic
-filetype=asm ch8_1_1.bc -o -
...
ld $4, 36($fp)
cmp $sw, $4, $3
jne $BB0_2
jmp $BB0_1
$BB0_1: # %if.then
ld $4, 36($fp)
addiu $4, $4, 1
st $4, 36($fp)
$BB0_2: # %if.end
ld $4, 32($fp)
...
118-165-79-206:input Jonathan$ /Users/Jonathan/llvm/test/
build/bin/llc -march=cpu0 -mcpu=cpu032I -relocation-model=pic
-filetype=obj ch8_1_1.bc -o ch8_1_1.cpu0.o
118-165-79-206:input Jonathan$ hexdump ch8_1_1.cpu0.o
// jmp offset is 0x10=16 bytes which is correct
0000080 ...................................... 10 43 00 00
0000090 31 00 00 10 36 00 00 00 ..........................
The immediate value of jne (opcode 0x31) is 16. The offset between jne and $BB0_2 is 20 bytes (5 words = 5 * 4 bytes). Suppose the address of jne is X, then the label $BB0_2 is located at X + 20.
Cpu0’s instruction set is designed as a RISC CPU with a 5-stage pipeline, similar to the MIPS architecture. Cpu0 executes branch instructions at the decode stage, just like MIPS.
After the jne instruction is fetched, the Program Counter (PC) is updated to X + 4, since Cpu0 updates the PC during the fetch stage. The address of $BB0_2 is equal to PC + 16, because the jne instruction executes at the decode stage.
This can be listed and explained again as follows:
// Fetch instruction stage for jne instruction. The fetch stage
// can be divided into 2 cycles. First cycle fetch the
// instruction. Second cycle adjust PC = PC+4.
jne $BB0_2 // Do jne compare in decode stage. PC = X+4 at this stage.
// When jne immediate value is 16, PC = PC+16. It will fetch
// X+20 which equal to label $BB0_2 instruction, ld $4, 32($sp).
nop
$BB0_1: # %if.then
ld $4, 36($fp)
addiu $4, $4, 1
st $4, 36($fp)
$BB0_2: # %if.end
ld $4, 32($fp)
If Cpu0 performs the “jne” instruction in the execution stage, then we should set PC = PC + 12, which equals the offset of ($BB0_2 - jne) minus 8, in this example.
In reality, conditional branches are critical to CPU performance. According to benchmark data, on average, one branch instruction occurs every seven instructions.
The cpu032I requires two instructions for a conditional branch: jne(cmp…). In contrast, cpu032II uses a single instruction (bne) as follows:
JonathantekiiMac:input Jonathan$ /Users/Jonathan/llvm/test/
build/bin/llc -march=cpu0 -mcpu=cpu032I -relocation-model=pic
-filetype=asm ch8_1_1.bc -o -
...
cmp $sw, $4, $3
jne $sw, $BB0_2
jmp $BB0_1
$BB0_1:
JonathantekiiMac:input Jonathan$ /Users/Jonathan/llvm/test/
build/bin/llc -march=cpu0 -mcpu=cpu032II -relocation-model=pic
-filetype=asm ch8_1_1.bc -o -
...
bne $4, $zero, $BB0_2
jmp $BB0_1
$BB0_1:
Besides the brcond explained in this section, the code above also includes the DAG opcode br_jt and label JumpTable, which appear during DAG translation for certain types of programs.
The file ch8_1_ctrl.cpp includes examples of control flow statements such as “nested if”, “for loop”, “while loop”, “continue”, “break”, and “goto”.
The file ch8_1_br_jt.cpp is used to test br_jt and JumpTable behavior.
The file ch8_1_blockaddr.cpp is for testing blockaddress and indirectbr instructions.
You can run these examples if you want to explore more control flow features.
List the control flow statements of C, corresponding LLVM IR, DAG nodes, and Cpu0 instructions in the following table.
C |
if, else, for, while, goto, switch, break |
IR |
(icmp + (eq, ne, sgt, sge, slt, sle)0 + br |
DAG |
(seteq, setne, setgt, setge, setlt, setle) + brcond, |
(setueq, setune, setugt, setuge, setult, setule) + brcond |
|
cpu032I |
CMP + (JEQ, JNE, JGT, JGE, JLT, JLE) |
cpu032II |
(SLT, SLTu, SLTi, SLTiu) + (BEG, BNE) |
Long branch support¶
As explained in the last section, cpu032II uses beq and bne instructions to improve performance. However, this change reduces the jump offset from 24 bits to 16 bits. If a program contains a branch that exceeds the 16-bit offset range, cpu032II will fail to generate valid code.
The MIPS backend has a solution to this limitation, and Cpu0 adopts a similar approach.
To support long branches, the following code was added in Chapter8_1.
lbdex/chapters/Chapter8_2/CMakeLists.txt
Cpu0LongBranch.cpp
lbdex/chapters/Chapter8_2/Cpu0.h
FunctionPass *createCpu0LongBranchPass(Cpu0TargetMachine &TM);
lbdex/chapters/Chapter8_2/MCTargetDesc/Cpu0MCCodeEmitter.cpp
unsigned Cpu0MCCodeEmitter::
getJumpTargetOpValue(const MCInst &MI, unsigned OpNo,
SmallVectorImpl<MCFixup> &Fixups,
const MCSubtargetInfo &STI) const {
if (Opcode == Cpu0::JMP || Opcode == Cpu0::BAL)
...
}
lbdex/chapters/Chapter8_2/Cpu0AsmPrinter.h
bool isLongBranchPseudo(int Opcode) const;
lbdex/chapters/Chapter8_2/Cpu0AsmPrinter.cpp
//- emitInstruction() must exists or will have run time error.
void Cpu0AsmPrinter::emitInstruction(const MachineInstr *MI) {
if (I->isPseudo() && !isLongBranchPseudo(I->getOpcode()))
...
}
bool Cpu0AsmPrinter::isLongBranchPseudo(int Opcode) const {
return (Opcode == Cpu0::LONG_BRANCH_LUi
|| Opcode == Cpu0::LONG_BRANCH_ADDiu);
}
lbdex/chapters/Chapter8_2/Cpu0InstrInfo.h
virtual unsigned getOppositeBranchOpc(unsigned Opc) const = 0;
lbdex/chapters/Chapter8_2/Cpu0InstrInfo.td
let Predicates = [Ch8_2] in {
// We need these two pseudo instructions to avoid offset calculation for long
// branches. See the comment in file Cpu0LongBranch.cpp for detailed
// explanation.
// Expands to: lui $dst, %hi($tgt - $baltgt)
def LONG_BRANCH_LUi : Cpu0Pseudo<(outs GPROut:$dst),
(ins jmptarget:$tgt, jmptarget:$baltgt), "", []>;
// Expands to: addiu $dst, $src, %lo($tgt - $baltgt)
def LONG_BRANCH_ADDiu : Cpu0Pseudo<(outs GPROut:$dst),
(ins GPROut:$src, jmptarget:$tgt, jmptarget:$baltgt), "", []>;
}
let isBranch = 1, isTerminator = 1, isBarrier = 1,
hasDelaySlot = 0, Defs = [LR] in
def BAL: FJ<0x3A, (outs), (ins jmptarget:$addr), "bal\t$addr", [], IIBranch>,
Requires<[HasSlt]>;
lbdex/chapters/Chapter8_2/Cpu0LongBranch.cpp
//===-- Cpu0LongBranch.cpp - Emit long branches ---------------------------===//
//
// The LLVM Compiler Infrastructure
//
// This file is distributed under the University of Illinois Open Source
// License. See LICENSE.TXT for details.
//
//===----------------------------------------------------------------------===//
//
// This pass expands a branch or jump instruction into a long branch if its
// offset is too large to fit into its immediate field.
//
// FIXME: Fix pc-region jump instructions which cross 256MB segment boundaries.
//===----------------------------------------------------------------------===//
// In 9.0.0 rename MipsLongBranch.cpp to MipsBranchExpansion.cpp
#include "Cpu0.h"
#if CH >= CH8_2
#include "MCTargetDesc/Cpu0BaseInfo.h"
#include "Cpu0MachineFunction.h"
#include "Cpu0TargetMachine.h"
#include "llvm/ADT/Statistic.h"
#include "llvm/CodeGen/MachineFunctionPass.h"
#include "llvm/CodeGen/MachineInstrBuilder.h"
#include "llvm/CodeGen/TargetInstrInfo.h"
#include "llvm/CodeGen/TargetRegisterInfo.h"
#include "llvm/IR/Function.h"
#include "llvm/Support/CommandLine.h"
#include "llvm/Support/MathExtras.h"
#include "llvm/Target/TargetMachine.h"
using namespace llvm;
#define DEBUG_TYPE "cpu0-long-branch"
STATISTIC(LongBranches, "Number of long branches.");
static cl::opt<bool> ForceLongBranch(
"force-cpu0-long-branch",
cl::init(false),
cl::desc("CPU0: Expand all branches to long format."),
cl::Hidden);
namespace {
typedef MachineBasicBlock::iterator Iter;
typedef MachineBasicBlock::reverse_iterator ReverseIter;
struct MBBInfo {
uint64_t Size, Address;
bool HasLongBranch;
MachineInstr *Br;
MBBInfo() : Size(0), HasLongBranch(false), Br(nullptr) {}
};
class Cpu0LongBranch : public MachineFunctionPass {
public:
static char ID;
Cpu0LongBranch(TargetMachine &tm)
: MachineFunctionPass(ID), TM(tm), IsPIC(TM.isPositionIndependent()),
ABI(static_cast<const Cpu0TargetMachine &>(TM).getABI()) {}
StringRef getPassName() const override {
return "Cpu0 Long Branch";
}
bool runOnMachineFunction(MachineFunction &F) override;
private:
void splitMBB(MachineBasicBlock *MBB);
void initMBBInfo();
int64_t computeOffset(const MachineInstr *Br);
void replaceBranch(MachineBasicBlock &MBB, Iter Br, const DebugLoc &DL,
MachineBasicBlock *MBBOpnd);
void expandToLongBranch(MBBInfo &Info);
const TargetMachine &TM;
MachineFunction *MF;
SmallVector<MBBInfo, 16> MBBInfos;
bool IsPIC;
Cpu0ABIInfo ABI;
unsigned LongBranchSeqSize;
};
char Cpu0LongBranch::ID = 0;
} // end of anonymous namespace
/// createCpu0LongBranchPass - Returns a pass that converts branches to long
/// branches.
FunctionPass *llvm::createCpu0LongBranchPass(Cpu0TargetMachine &tm) {
return new Cpu0LongBranch(tm);
}
/// Iterate over list of Br's operands and search for a MachineBasicBlock
/// operand.
static MachineBasicBlock *getTargetMBB(const MachineInstr &Br) {
for (unsigned I = 0, E = Br.getDesc().getNumOperands(); I < E; ++I) {
const MachineOperand &MO = Br.getOperand(I);
if (MO.isMBB())
return MO.getMBB();
}
llvm_unreachable("This instruction does not have an MBB operand.");
}
// Traverse the list of instructions backwards until a non-debug instruction is
// found or it reaches E.
static ReverseIter getNonDebugInstr(ReverseIter B, const ReverseIter &E) {
for (; B != E; ++B)
if (!B->isDebugValue())
return B;
return E;
}
// Split MBB if it has two direct jumps/branches.
void Cpu0LongBranch::splitMBB(MachineBasicBlock *MBB) {
ReverseIter End = MBB->rend();
ReverseIter LastBr = getNonDebugInstr(MBB->rbegin(), End);
// Return if MBB has no branch instructions.
if ((LastBr == End) ||
(!LastBr->isConditionalBranch() && !LastBr->isUnconditionalBranch()))
return;
ReverseIter FirstBr = getNonDebugInstr(std::next(LastBr), End);
// MBB has only one branch instruction if FirstBr is not a branch
// instruction.
if ((FirstBr == End) ||
(!FirstBr->isConditionalBranch() && !FirstBr->isUnconditionalBranch()))
return;
assert(!FirstBr->isIndirectBranch() && "Unexpected indirect branch found.");
// Create a new MBB. Move instructions in MBB to the newly created MBB.
MachineBasicBlock *NewMBB =
MF->CreateMachineBasicBlock(MBB->getBasicBlock());
// Insert NewMBB and fix control flow.
MachineBasicBlock *Tgt = getTargetMBB(*FirstBr);
NewMBB->transferSuccessors(MBB);
if (Tgt != getTargetMBB(*LastBr))
NewMBB->removeSuccessor(Tgt, true);
MBB->addSuccessor(NewMBB);
MBB->addSuccessor(Tgt);
MF->insert(std::next(MachineFunction::iterator(MBB)), NewMBB);
NewMBB->splice(NewMBB->end(), MBB, LastBr.getReverse(), MBB->end());
}
// Fill MBBInfos.
void Cpu0LongBranch::initMBBInfo() {
// Split the MBBs if they have two branches. Each basic block should have at
// most one branch after this loop is executed.
for (auto &MBB : *MF)
splitMBB(&MBB);
MF->RenumberBlocks();
MBBInfos.clear();
MBBInfos.resize(MF->size());
const Cpu0InstrInfo *TII =
static_cast<const Cpu0InstrInfo *>(MF->getSubtarget().getInstrInfo());
for (unsigned I = 0, E = MBBInfos.size(); I < E; ++I) {
MachineBasicBlock *MBB = MF->getBlockNumbered(I);
// Compute size of MBB.
for (MachineBasicBlock::instr_iterator MI = MBB->instr_begin();
MI != MBB->instr_end(); ++MI)
MBBInfos[I].Size += TII->GetInstSizeInBytes(*MI);
// Search for MBB's branch instruction.
ReverseIter End = MBB->rend();
ReverseIter Br = getNonDebugInstr(MBB->rbegin(), End);
if ((Br != End) && !Br->isIndirectBranch() &&
(Br->isConditionalBranch() || (Br->isUnconditionalBranch() && IsPIC)))
MBBInfos[I].Br = &(*Br.getReverse());
}
}
// Compute offset of branch in number of bytes.
int64_t Cpu0LongBranch::computeOffset(const MachineInstr *Br) {
int64_t Offset = 0;
int ThisMBB = Br->getParent()->getNumber();
int TargetMBB = getTargetMBB(*Br)->getNumber();
// Compute offset of a forward branch.
if (ThisMBB < TargetMBB) {
for (int N = ThisMBB + 1; N < TargetMBB; ++N)
Offset += MBBInfos[N].Size;
return Offset + 4;
}
// Compute offset of a backward branch.
for (int N = ThisMBB; N >= TargetMBB; --N)
Offset += MBBInfos[N].Size;
return -Offset + 4;
}
// Replace Br with a branch which has the opposite condition code and a
// MachineBasicBlock operand MBBOpnd.
void Cpu0LongBranch::replaceBranch(MachineBasicBlock &MBB, Iter Br,
const DebugLoc &DL,
MachineBasicBlock *MBBOpnd) {
const Cpu0InstrInfo *TII = static_cast<const Cpu0InstrInfo *>(
MBB.getParent()->getSubtarget().getInstrInfo());
unsigned NewOpc = TII->getOppositeBranchOpc(Br->getOpcode());
const MCInstrDesc &NewDesc = TII->get(NewOpc);
MachineInstrBuilder MIB = BuildMI(MBB, Br, DL, NewDesc);
for (unsigned I = 0, E = Br->getDesc().getNumOperands(); I < E; ++I) {
MachineOperand &MO = Br->getOperand(I);
if (!MO.isReg()) {
assert(MO.isMBB() && "MBB operand expected.");
break;
}
MIB.addReg(MO.getReg());
}
MIB.addMBB(MBBOpnd);
if (Br->hasDelaySlot()) {
// Bundle the instruction in the delay slot to the newly created branch
// and erase the original branch.
assert(Br->isBundledWithSucc());
MachineBasicBlock::instr_iterator II = Br.getInstrIterator();
MIBundleBuilder(&*MIB).append((++II)->removeFromBundle());
}
Br->eraseFromParent();
}
// Expand branch instructions to long branches.
// TODO: This function has to be fixed for beqz16 and bnez16, because it
// currently assumes that all branches have 16-bit offsets, and will produce
// wrong code if branches whose allowed offsets are [-128, -126, ..., 126]
// are present.
void Cpu0LongBranch::expandToLongBranch(MBBInfo &I) {
MachineBasicBlock::iterator Pos;
MachineBasicBlock *MBB = I.Br->getParent(), *TgtMBB = getTargetMBB(*I.Br);
DebugLoc DL = I.Br->getDebugLoc();
const BasicBlock *BB = MBB->getBasicBlock();
MachineFunction::iterator FallThroughMBB = ++MachineFunction::iterator(MBB);
MachineBasicBlock *LongBrMBB = MF->CreateMachineBasicBlock(BB);
const Cpu0Subtarget &Subtarget =
static_cast<const Cpu0Subtarget &>(MF->getSubtarget());
const Cpu0InstrInfo *TII =
static_cast<const Cpu0InstrInfo *>(Subtarget.getInstrInfo());
MF->insert(FallThroughMBB, LongBrMBB);
MBB->replaceSuccessor(TgtMBB, LongBrMBB);
if (IsPIC) {
MachineBasicBlock *BalTgtMBB = MF->CreateMachineBasicBlock(BB);
MF->insert(FallThroughMBB, BalTgtMBB);
LongBrMBB->addSuccessor(BalTgtMBB);
BalTgtMBB->addSuccessor(TgtMBB);
unsigned BalOp = Cpu0::BAL;
// $longbr:
// addiu $sp, $sp, -8
// st $lr, 0($sp)
// lui $at, %hi($tgt - $baltgt)
// addiu $lr, $lr, %lo($tgt - $baltgt)
// bal $baltgt
// nop
// $baltgt:
// addu $at, $lr, $at
// addiu $sp, $sp, 8
// ld $lr, 0($sp)
// jr $at
// nop
// $fallthrough:
//
Pos = LongBrMBB->begin();
BuildMI(*LongBrMBB, Pos, DL, TII->get(Cpu0::ADDiu), Cpu0::SP)
.addReg(Cpu0::SP).addImm(-8);
BuildMI(*LongBrMBB, Pos, DL, TII->get(Cpu0::ST)).addReg(Cpu0::LR)
.addReg(Cpu0::SP).addImm(0);
// LUi and ADDiu instructions create 32-bit offset of the target basic
// block from the target of BAL instruction. We cannot use immediate
// value for this offset because it cannot be determined accurately when
// the program has inline assembly statements. We therefore use the
// relocation expressions %hi($tgt-$baltgt) and %lo($tgt-$baltgt) which
// are resolved during the fixup, so the values will always be correct.
//
// Since we cannot create %hi($tgt-$baltgt) and %lo($tgt-$baltgt)
// expressions at this point (it is possible only at the MC layer),
// we replace LUi and ADDiu with pseudo instructions
// LONG_BRANCH_LUi and LONG_BRANCH_ADDiu, and add both basic
// blocks as operands to these instructions. When lowering these pseudo
// instructions to LUi and ADDiu in the MC layer, we will create
// %hi($tgt-$baltgt) and %lo($tgt-$baltgt) expressions and add them as
// operands to lowered instructions.
BuildMI(*LongBrMBB, Pos, DL, TII->get(Cpu0::LONG_BRANCH_LUi), Cpu0::AT)
.addMBB(TgtMBB).addMBB(BalTgtMBB);
BuildMI(*LongBrMBB, Pos, DL, TII->get(Cpu0::LONG_BRANCH_ADDiu), Cpu0::AT)
.addReg(Cpu0::AT).addMBB(TgtMBB).addMBB(BalTgtMBB);
MIBundleBuilder(*LongBrMBB, Pos)
.append(BuildMI(*MF, DL, TII->get(BalOp)).addMBB(BalTgtMBB));
Pos = BalTgtMBB->begin();
BuildMI(*BalTgtMBB, Pos, DL, TII->get(Cpu0::ADDu), Cpu0::AT)
.addReg(Cpu0::LR).addReg(Cpu0::AT);
BuildMI(*BalTgtMBB, Pos, DL, TII->get(Cpu0::LD), Cpu0::LR)
.addReg(Cpu0::SP).addImm(0);
BuildMI(*BalTgtMBB, Pos, DL, TII->get(Cpu0::ADDiu), Cpu0::SP)
.addReg(Cpu0::SP).addImm(8);
MIBundleBuilder(*BalTgtMBB, Pos)
.append(BuildMI(*MF, DL, TII->get(Cpu0::JR)).addReg(Cpu0::AT))
.append(BuildMI(*MF, DL, TII->get(Cpu0::NOP)));
assert(LongBrMBB->size() + BalTgtMBB->size() == LongBranchSeqSize);
} else {
// $longbr:
// jmp $tgt
// nop
// $fallthrough:
//
Pos = LongBrMBB->begin();
LongBrMBB->addSuccessor(TgtMBB);
MIBundleBuilder(*LongBrMBB, Pos)
.append(BuildMI(*MF, DL, TII->get(Cpu0::JMP)).addMBB(TgtMBB))
.append(BuildMI(*MF, DL, TII->get(Cpu0::NOP)));
assert(LongBrMBB->size() == LongBranchSeqSize);
}
if (I.Br->isUnconditionalBranch()) {
// Change branch destination.
assert(I.Br->getDesc().getNumOperands() == 1);
I.Br->RemoveOperand(0);
I.Br->addOperand(MachineOperand::CreateMBB(LongBrMBB));
} else
// Change branch destination and reverse condition.
replaceBranch(*MBB, I.Br, DL, &*FallThroughMBB);
}
static void emitGPDisp(MachineFunction &F, const Cpu0InstrInfo *TII) {
MachineBasicBlock &MBB = F.front();
MachineBasicBlock::iterator I = MBB.begin();
DebugLoc DL = MBB.findDebugLoc(MBB.begin());
BuildMI(MBB, I, DL, TII->get(Cpu0::LUi), Cpu0::V0)
.addExternalSymbol("_gp_disp", Cpu0II::MO_ABS_HI);
BuildMI(MBB, I, DL, TII->get(Cpu0::ADDiu), Cpu0::V0)
.addReg(Cpu0::V0).addExternalSymbol("_gp_disp", Cpu0II::MO_ABS_LO);
MBB.removeLiveIn(Cpu0::V0);
}
bool Cpu0LongBranch::runOnMachineFunction(MachineFunction &F) {
const Cpu0Subtarget &STI =
static_cast<const Cpu0Subtarget &>(F.getSubtarget());
const Cpu0InstrInfo *TII =
static_cast<const Cpu0InstrInfo *>(STI.getInstrInfo());
LongBranchSeqSize =
!IsPIC ? 2 : 10;
if (!STI.enableLongBranchPass())
return false;
if (IsPIC && static_cast<const Cpu0TargetMachine &>(TM).getABI().IsO32() &&
F.getInfo<Cpu0FunctionInfo>()->globalBaseRegSet())
emitGPDisp(F, TII);
MF = &F;
initMBBInfo();
SmallVectorImpl<MBBInfo>::iterator I, E = MBBInfos.end();
bool EverMadeChange = false, MadeChange = true;
while (MadeChange) {
MadeChange = false;
for (I = MBBInfos.begin(); I != E; ++I) {
// Skip if this MBB doesn't have a branch or the branch has already been
// converted to a long branch.
if (!I->Br || I->HasLongBranch)
continue;
int ShVal = 4;
int64_t Offset = computeOffset(I->Br) / ShVal;
// Check if offset fits into 16-bit immediate field of branches.
if (!ForceLongBranch && isInt<16>(Offset))
continue;
I->HasLongBranch = true;
I->Size += LongBranchSeqSize * 4;
++LongBranches;
EverMadeChange = MadeChange = true;
}
}
if (!EverMadeChange)
return true;
// Compute basic block addresses.
if (IsPIC) {
uint64_t Address = 0;
for (I = MBBInfos.begin(); I != E; Address += I->Size, ++I)
I->Address = Address;
}
// Do the expansion.
for (I = MBBInfos.begin(); I != E; ++I)
if (I->HasLongBranch)
expandToLongBranch(*I);
MF->RenumberBlocks();
return true;
}
#endif //#if CH >= CH8_2
lbdex/chapters/Chapter8_2/Cpu0MCInstLower.h
MCOperand createSub(MachineBasicBlock *BB1, MachineBasicBlock *BB2,
Cpu0MCExpr::Cpu0ExprKind Kind) const;
void lowerLongBranchLUi(const MachineInstr *MI, MCInst &OutMI) const;
void lowerLongBranchADDiu(const MachineInstr *MI, MCInst &OutMI,
int Opcode,
Cpu0MCExpr::Cpu0ExprKind Kind) const;
bool lowerLongBranch(const MachineInstr *MI, MCInst &OutMI) const;
lbdex/chapters/Chapter8_2/Cpu0MCInstLower.cpp
MCOperand Cpu0MCInstLower::createSub(MachineBasicBlock *BB1,
MachineBasicBlock *BB2,
Cpu0MCExpr::Cpu0ExprKind Kind) const {
const MCSymbolRefExpr *Sym1 = MCSymbolRefExpr::create(BB1->getSymbol(), *Ctx);
const MCSymbolRefExpr *Sym2 = MCSymbolRefExpr::create(BB2->getSymbol(), *Ctx);
const MCBinaryExpr *Sub = MCBinaryExpr::createSub(Sym1, Sym2, *Ctx);
return MCOperand::createExpr(Cpu0MCExpr::create(Kind, Sub, *Ctx));
}
void Cpu0MCInstLower::
lowerLongBranchLUi(const MachineInstr *MI, MCInst &OutMI) const {
OutMI.setOpcode(Cpu0::LUi);
// Lower register operand.
OutMI.addOperand(LowerOperand(MI->getOperand(0)));
// Create %hi($tgt-$baltgt).
OutMI.addOperand(createSub(MI->getOperand(1).getMBB(),
MI->getOperand(2).getMBB(),
Cpu0MCExpr::CEK_ABS_HI));
}
void Cpu0MCInstLower::
lowerLongBranchADDiu(const MachineInstr *MI, MCInst &OutMI, int Opcode,
Cpu0MCExpr::Cpu0ExprKind Kind) const {
OutMI.setOpcode(Opcode);
// Lower two register operands.
for (unsigned I = 0, E = 2; I != E; ++I) {
const MachineOperand &MO = MI->getOperand(I);
OutMI.addOperand(LowerOperand(MO));
}
// Create %lo($tgt-$baltgt) or %hi($tgt-$baltgt).
OutMI.addOperand(createSub(MI->getOperand(2).getMBB(),
MI->getOperand(3).getMBB(), Kind));
}
bool Cpu0MCInstLower::lowerLongBranch(const MachineInstr *MI,
MCInst &OutMI) const {
switch (MI->getOpcode()) {
default:
return false;
case Cpu0::LONG_BRANCH_LUi:
lowerLongBranchLUi(MI, OutMI);
return true;
case Cpu0::LONG_BRANCH_ADDiu:
lowerLongBranchADDiu(MI, OutMI, Cpu0::ADDiu,
Cpu0MCExpr::CEK_ABS_LO);
return true;
}
}
void Cpu0MCInstLower::Lower(const MachineInstr *MI, MCInst &OutMI) const {
if (lowerLongBranch(MI, OutMI))
return;
...
}
lbdex/chapters/Chapter8_2/Cpu0SEInstrInfo.h
unsigned getOppositeBranchOpc(unsigned Opc) const override;
lbdex/chapters/Chapter8_2/Cpu0SEInstrInfo.cpp
/// getOppositeBranchOpc - Return the inverse of the specified
/// opcode, e.g. turning BEQ to BNE.
unsigned Cpu0SEInstrInfo::getOppositeBranchOpc(unsigned Opc) const {
switch (Opc) {
default: llvm_unreachable("Illegal opcode!");
case Cpu0::BEQ: return Cpu0::BNE;
case Cpu0::BNE: return Cpu0::BEQ;
}
}
lbdex/chapters/Chapter8_2/Cpu0TargetMachine.cpp
void addPreEmitPass() override;
// Implemented by targets that want to run passes immediately before
// machine code is emitted. return true if -print-machineinstrs should
// print out the code after the passes.
void Cpu0PassConfig::addPreEmitPass() {
Cpu0TargetMachine &TM = getCpu0TargetMachine();
addPass(createCpu0LongBranchPass(TM));
return;
}
The code of Chapter8_2 will compile the following example as follows:
lbdex/input/ch8_2_longbranch.cpp
int test_longbranch()
{
volatile int a = 2;
volatile int b = 1;
int result = 0;
if (a < b)
result = 1;
return result;
}
118-165-78-10:input Jonathan$ ~/llvm/test/build/bin/llc
-march=cpu0 -mcpu=cpu032II -relocation-model=pic -filetype=asm
-force-cpu0-long-branch ch8_2_longbranch.bc -o -
...
.text
.section .mdebug.abiO32
.previous
.file "ch8_2_longbranch.bc"
.globl _Z15test_longbranchv
.align 2
.type _Z15test_longbranchv,@function
.ent _Z15test_longbranchv # @_Z15test_longbranchv
_Z15test_longbranchv:
.frame $fp,16,$lr
.mask 0x00001000,-4
.set noreorder
.set nomacro
# BB#0:
addiu $sp, $sp, -16
st $fp, 12($sp) # 4-byte Folded Spill
move $fp, $sp
addiu $2, $zero, 1
st $2, 8($fp)
addiu $3, $zero, 2
st $3, 4($fp)
addiu $3, $zero, 0
st $3, 0($fp)
ld $3, 8($fp)
ld $4, 4($fp)
slt $3, $3, $4
bne $3, $zero, .LBB0_3
nop
# BB#1:
addiu $sp, $sp, -8
st $lr, 0($sp)
lui $1, %hi(.LBB0_4-.LBB0_2)
addiu $1, $1, %lo(.LBB0_4-.LBB0_2)
bal .LBB0_2
.LBB0_2:
addu $1, $lr, $1
ld $lr, 0($sp)
addiu $sp, $sp, 8
jr $1
nop
.LBB0_3:
st $2, 0($fp)
.LBB0_4:
ld $2, 0($fp)
move $sp, $fp
ld $fp, 12($sp) # 4-byte Folded Reload
addiu $sp, $sp, 16
ret $lr
nop
.set macro
.set reorder
.end _Z15test_longbranchv
$func_end0:
.size _Z15test_longbranchv, ($func_end0)-_Z15test_longbranchv
Cpu0 Backend Optimization: Remove Useless JMP¶
LLVM uses functional passes in both code generation and optimization. Following the three-tier architecture of a compiler, LLVM performs most optimizations in the middle tier, working on the LLVM IR in SSA form.
Beyond middle-tier optimizations, there are opportunities for backend-specific optimizations that depend on target architecture features. For example, “fill delay slot” in the Mips backend is a backend optimization used in pipelined RISC machines. You can port this technique from Mips if your backend also supports pipeline RISC with delay slots.
In this section, we implement the “remove useless jmp” optimization in the Cpu0 backend. This algorithm is simple and effective, making it a perfect tutorial for learning how to add an optimization pass. Through this example, you can understand how to introduce an optimization pass and implement a more complex optimization algorithm tailored for your backend in a real-world project.
The Chapter8_2/ directory supports the “remove useless jmp” optimization algorithm and includes the added code as follows:
lbdex/chapters/Chapter8_2/CMakeLists.txt
Cpu0DelUselessJMP.cpp
lbdex/chapters/Chapter8_2/Cpu0.h
FunctionPass *createCpu0DelJmpPass(Cpu0TargetMachine &TM);
lbdex/chapters/Chapter8_2/Cpu0TargetMachine.cpp
// Implemented by targets that want to run passes immediately before
// machine code is emitted. return true if -print-machineinstrs should
// print out the code after the passes.
void Cpu0PassConfig::addPreEmitPass() {
Cpu0TargetMachine &TM = getCpu0TargetMachine();
addPass(createCpu0DelJmpPass(TM));
}
lbdex/chapters/Chapter8_2/Cpu0DelUselessJMP.cpp
//===-- Cpu0DelUselessJMP.cpp - Cpu0 DelJmp -------------------------------===//
//
// The LLVM Compiler Infrastructure
//
// This file is distributed under the University of Illinois Open Source
// License. See LICENSE.TXT for details.
//
//===----------------------------------------------------------------------===//
//
// Simple pass to fills delay slots with useful instructions.
//
//===----------------------------------------------------------------------===//
#include "Cpu0.h"
#if CH >= CH8_2
#include "Cpu0TargetMachine.h"
#include "llvm/CodeGen/MachineFunctionPass.h"
#include "llvm/CodeGen/TargetInstrInfo.h"
#include "llvm/Support/CommandLine.h"
#include "llvm/Target/TargetMachine.h"
#include "llvm/ADT/SmallSet.h"
#include "llvm/ADT/Statistic.h"
using namespace llvm;
#define DEBUG_TYPE "del-jmp"
STATISTIC(NumDelJmp, "Number of useless jmp deleted");
static cl::opt<bool> EnableDelJmp(
"enable-cpu0-del-useless-jmp",
cl::init(true),
cl::desc("Delete useless jmp instructions: jmp 0."),
cl::Hidden);
namespace {
struct DelJmp : public MachineFunctionPass {
static char ID;
DelJmp(TargetMachine &tm)
: MachineFunctionPass(ID) { }
StringRef getPassName() const override {
return "Cpu0 Del Useless jmp";
}
bool runOnMachineBasicBlock(MachineBasicBlock &MBB, MachineBasicBlock &MBBN);
bool runOnMachineFunction(MachineFunction &F) override {
bool Changed = false;
if (EnableDelJmp) {
MachineFunction::iterator FJ = F.begin();
if (FJ != F.end())
FJ++;
if (FJ == F.end())
return Changed;
for (MachineFunction::iterator FI = F.begin(), FE = F.end();
FJ != FE; ++FI, ++FJ)
// In STL style, F.end() is the dummy BasicBlock() like '\0' in
// C string.
// FJ is the next BasicBlock of FI; When FI range from F.begin() to
// the PreviousBasicBlock of F.end() call runOnMachineBasicBlock().
Changed |= runOnMachineBasicBlock(*FI, *FJ);
}
return Changed;
}
};
char DelJmp::ID = 0;
} // end of anonymous namespace
bool DelJmp::
runOnMachineBasicBlock(MachineBasicBlock &MBB, MachineBasicBlock &MBBN) {
bool Changed = false;
MachineBasicBlock::iterator I = MBB.end();
if (I != MBB.begin())
I--; // set I to the last instruction
else
return Changed;
if (I->getOpcode() == Cpu0::JMP && I->getOperand(0).getMBB() == &MBBN) {
// I is the instruction of "jmp #offset=0", as follows,
// jmp $BB0_3
// $BB0_3:
// ld $4, 28($sp)
++NumDelJmp;
MBB.erase(I); // delete the "JMP 0" instruction
Changed = true; // Notify LLVM kernel Changed
}
return Changed;
}
/// createCpu0DelJmpPass - Returns a pass that DelJmp in Cpu0 MachineFunctions
FunctionPass *llvm::createCpu0DelJmpPass(Cpu0TargetMachine &tm) {
return new DelJmp(tm);
}
#endif
As the above code shows, except for Cpu0DelUselessJMP.cpp, other files are changed to register the class DelJmp as a functional pass.
As the comment in the code explains, MBB is the current basic block, and MBBN is the next block. For each last instruction of every MBB, we check whether it is a JMP instruction and if its operand is the next basic block.
Using getMBB() in MachineOperand, you can get the address of the MBB. For more information about the member functions of MachineOperand, please check the file include/llvm/CodeGen/MachineOperand.h.
Now, let’s run Chapter8_2/ with ch8_2_deluselessjmp.cpp for further explanation.
lbdex/input/ch8_2_deluselessjmp.cpp
int test_DelUselessJMP()
{
int a = 1; int b = -2; int c = 3;
if (a == 0) {
a++;
}
if (b == 0) {
a = a + 3;
b++;
} else if (b < 0) {
a = a + b;
b--;
}
if (c > 0) {
a = a + c;
c++;
}
return a;
}
118-165-78-10:input Jonathan$ clang -target mips-unknown-linux-gnu
-c ch8_2_deluselessjmp.cpp -emit-llvm -o ch8_2_deluselessjmp.bc
118-165-78-10:input Jonathan$ /Users/Jonathan/llvm/test/build/
bin/llc -march=cpu0 -relocation-model=static -filetype=asm -stats
ch8_2_deluselessjmp.bc -o -
...
cmp $sw, $4, $3
jne $sw, $BB0_2
nop
# BB#1:
...
cmp $sw, $3, $2
jlt $sw, $BB0_8
nop
# BB#7:
...
===-------------------------------------------------------------------------===
... Statistics Collected ...
===-------------------------------------------------------------------------===
...
2 del-jmp - Number of useless jmp deleted
...
The terminal displays “Number of useless jmp deleted” when running with the
llc -stats option, because we set the
STATISTIC(NumDelJmp, "Number of useless jmp deleted") in the code. It
deletes 2 jmp instructions from block # BB#0 and $BB0_6.
You can verify this by using the llc -enable-cpu0-del-useless-jmp=false
option to compare with the non-optimized version.
If you run with ch8_1_1.cpp, you will find 10 jmp instructions are deleted from 120 lines of assembly code. This implies about 8% improvement in both speed and code size [1].
Fill Branch Delay Slot¶
Cpu0 instruction set is designed to be a classical RISC pipeline machine. Classical RISC machines have many ideal features [3] [4].
I modified the Cpu0 backend to support a 5-stage classical RISC pipeline with one delay slot, similar to some Mips models. (The original Cpu0 backend from its author used a 3-stage pipeline.)
With this change, the backend needs to insert a NOP instruction in the branch delay slot.
To keep this tutorial simple, the Cpu0 backend does not attempt to fill the
delay slot with useful instructions for optimization. Readers can refer to
MipsDelaySlotFiller.cpp for an example of how to do this kind of backend
optimization.
The following code was added in Chapter8_2 for NOP insertion in the branch delay slot.
lbdex/chapters/Chapter8_2/CMakeLists.txt
Cpu0DelaySlotFiller.cpp
lbdex/chapters/Chapter8_2/Cpu0.h
FunctionPass *createCpu0DelaySlotFillerPass(Cpu0TargetMachine &TM);
lbdex/chapters/Chapter8_2/Cpu0TargetMachine.cpp
// Implemented by targets that want to run passes immediately before
// machine code is emitted. return true if -print-machineinstrs should
// print out the code after the passes.
void Cpu0PassConfig::addPreEmitPass() {
Cpu0TargetMachine &TM = getCpu0TargetMachine();
addPass(createCpu0DelaySlotFillerPass(TM));
}
lbdex/chapters/Chapter8_2/Cpu0DelaySlotFiller.cpp
//===-- Cpu0DelaySlotFiller.cpp - Cpu0 Delay Slot Filler ------------------===//
//
// The LLVM Compiler Infrastructure
//
// This file is distributed under the University of Illinois Open Source
// License. See LICENSE.TXT for details.
//
//===----------------------------------------------------------------------===//
//
// Simple pass to fill delay slots with useful instructions.
//
//===----------------------------------------------------------------------===//
#include "Cpu0.h"
#if CH >= CH8_2
#include "Cpu0InstrInfo.h"
#include "Cpu0TargetMachine.h"
#include "llvm/ADT/BitVector.h"
#include "llvm/ADT/SmallPtrSet.h"
#include "llvm/ADT/Statistic.h"
#include "llvm/Analysis/AliasAnalysis.h"
#include "llvm/Analysis/ValueTracking.h"
#include "llvm/CodeGen/MachineBranchProbabilityInfo.h"
#include "llvm/CodeGen/MachineFunctionPass.h"
#include "llvm/CodeGen/MachineInstrBuilder.h"
#include "llvm/CodeGen/PseudoSourceValue.h"
#include "llvm/CodeGen/TargetInstrInfo.h"
#include "llvm/Support/CommandLine.h"
#include "llvm/Target/TargetMachine.h"
#include "llvm/CodeGen/TargetRegisterInfo.h"
using namespace llvm;
#define DEBUG_TYPE "delay-slot-filler"
STATISTIC(FilledSlots, "Number of delay slots filled");
namespace {
typedef MachineBasicBlock::iterator Iter;
typedef MachineBasicBlock::reverse_iterator ReverseIter;
class Filler : public MachineFunctionPass {
public:
Filler(TargetMachine &tm)
: MachineFunctionPass(ID) { }
StringRef getPassName() const override {
return "Cpu0 Delay Slot Filler";
}
bool runOnMachineFunction(MachineFunction &F) override {
bool Changed = false;
for (MachineFunction::iterator FI = F.begin(), FE = F.end();
FI != FE; ++FI)
Changed |= runOnMachineBasicBlock(*FI);
return Changed;
}
private:
bool runOnMachineBasicBlock(MachineBasicBlock &MBB);
static char ID;
};
char Filler::ID = 0;
} // end of anonymous namespace
static bool hasUnoccupiedSlot(const MachineInstr *MI) {
return MI->hasDelaySlot() && !MI->isBundledWithSucc();
}
/// runOnMachineBasicBlock - Fill in delay slots for the given basic block.
/// We assume there is only one delay slot per delayed instruction.
bool Filler::runOnMachineBasicBlock(MachineBasicBlock &MBB) {
bool Changed = false;
const Cpu0Subtarget &STI = MBB.getParent()->getSubtarget<Cpu0Subtarget>();
const Cpu0InstrInfo *TII = STI.getInstrInfo();
for (Iter I = MBB.begin(); I != MBB.end(); ++I) {
if (!hasUnoccupiedSlot(&*I))
continue;
++FilledSlots;
Changed = true;
// Bundle the NOP to the instruction with the delay slot.
BuildMI(MBB, std::next(I), I->getDebugLoc(), TII->get(Cpu0::NOP));
MIBundleBuilder(MBB, I, std::next(I, 2));
}
return Changed;
}
/// createCpu0DelaySlotFillerPass - Returns a pass that fills in delay
/// slots in Cpu0 MachineFunctions
FunctionPass *llvm::createCpu0DelaySlotFillerPass(Cpu0TargetMachine &tm) {
return new Filler(tm);
}
#endif
To ensure the basic block label remains unchanged, the statement
MIBundleBuilder() must be inserted after the BuildMI(..., NOP)
statement in Cpu0DelaySlotFiller.cpp.
MIBundleBuilder() bundles the branch instruction and the NOP into a single
instruction unit. The first part is the branch instruction, and the second part
is the NOP.
lbdex/chapters/Chapter3_2/Cpu0AsmPrinter.cpp
//- emitInstruction() must exists or will have run time error.
void Cpu0AsmPrinter::emitInstruction(const MachineInstr *MI) {
// Print out both ordinary instruction and boudle instruction
MachineBasicBlock::const_instr_iterator I = MI->getIterator();
MachineBasicBlock::const_instr_iterator E = MI->getParent()->instr_end();
do {
if (I->isPseudo() && !isLongBranchPseudo(I->getOpcode()))
llvm_unreachable("Pseudo opcode found in emitInstruction()");
MCInst TmpInst0;
// Call Cpu0MCInstLower::Lower(const MachineInstr *MI, MCInst &OutMI) to
// extracts MCInst from MachineInstr.
MCInstLowering.Lower(&*I, TmpInst0);
OutStreamer->emitInstruction(TmpInst0, getSubtargetInfo());
} while ((++I != E) && I->isInsideBundle()); // Delay slot check
}
In order to print the NOP, the Cpu0AsmPrinter.cpp of Chapter3_2 prints all
bundle instructions in a loop. Without the loop, only the first part of the
bundle instruction (branch instruction only) is printed.
In LLVM 3.1, the basic block label remains the same even if you do not bundle after it. But for some reason, this behavior changed in a later LLVM version, and now you need to perform the “bundle” to keep the block label unchanged in later LLVM phases.
Conditional Instruction¶
lbdex/input/ch8_2_select.cpp
// The following files will generate IR select even compile with clang -O0.
int test_movx_1()
{
volatile int a = 1;
int c = 0;
c = !a ? 1:3;
return c;
}
int test_movx_2()
{
volatile int a = 1;
int c = 0;
c = a ? 1:3;
return c;
}
Run Chapter8_1 with ch8_2_select.cpp will get the following result.
114-37-150-209:input Jonathan$ clang -O1 -target mips-unknown-linux-gnu
-c ch8_2_select.cpp -emit-llvm -o ch8_2_select.bc
114-37-150-209:input Jonathan$ ~/llvm/test/build/bin/
llvm-dis ch8_2_select.bc -o -
...
; Function Attrs: nounwind uwtable
define i32 @_Z11test_movx_1v() #0 {
%a = alloca i32, align 4
%c = alloca i32, align 4
store volatile i32 1, i32* %a, align 4
store i32 0, i32* %c, align 4
%1 = load volatile i32* %a, align 4
%2 = icmp ne i32 %1, 0
%3 = xor i1 %2, true
%4 = select i1 %3, i32 1, i32 3
store i32 %4, i32* %c, align 4
%5 = load i32* %c, align 4
ret i32 %5
}
; Function Attrs: nounwind uwtable
define i32 @_Z11test_movx_2v() #0 {
%a = alloca i32, align 4
%c = alloca i32, align 4
store volatile i32 1, i32* %a, align 4
store i32 0, i32* %c, align 4
%1 = load volatile i32* %a, align 4
%2 = icmp ne i32 %1, 0
%3 = select i1 %2, i32 1, i32 3
store i32 %3, i32* %c, align 4
%4 = load i32* %c, align 4
ret i32 %4
}
...
114-37-150-209:input Jonathan$ ~/llvm/test/build/bin/llc
-march=cpu0 -mcpu=cpu032I -relocation-model=static -filetype=asm
ch8_2_select.bc -o -
...
LLVM ERROR: Cannot select: 0x39f47c0: i32 = select_cc ...
As shown in the above LLVM IR from ch8_2_select.bc, Clang generates a select IR for small control blocks (e.g., an if-statement containing only one assignment). This select IR is the result of an optimization for CPUs that support conditional instructions.
From the error message above, it is clear that the IR select is transformed into select_cc during the DAG (Directed Acyclic Graph) optimization stage.
Chapter8_2 supports select with the following code added and changed.
lbdex/chapters/Chapter8_2/Cpu0InstrInfo.td
let Predicates = [Ch8_2] in {
include "Cpu0CondMov.td"
} // let Predicates = [Ch8_2]
lbdex/chapters/Chapter8_2/Cpu0CondMov.td
//===-- Cpu0CondMov.td - Describe Cpu0 Conditional Moves --*- tablegen -*--===//
//
// The LLVM Compiler Infrastructure
//
// This file is distributed under the University of Illinois Open Source
// License. See LICENSE.TXT for details.
//
//===----------------------------------------------------------------------===//
//
// This is the Conditional Moves implementation.
//
//===----------------------------------------------------------------------===//
// Conditional moves:
// These instructions are expanded in
// Cpu0ISelLowering::EmitInstrWithCustomInserter if target does not have
// conditional move instructions.
// cond:int, data:int
class CondMovIntInt<RegisterClass CRC, RegisterClass DRC, bits<8> op,
string instr_asm> :
FA<op, (outs DRC:$ra), (ins DRC:$rb, CRC:$rc, DRC:$F),
!strconcat(instr_asm, "\t$ra, $rb, $rc"), [], IIAlu> {
let shamt = 0;
let Constraints = "$F = $ra";
}
// select patterns
multiclass MovzPats0Slt<RegisterClass CRC, RegisterClass DRC,
Instruction MOVZInst, Instruction SLTOp,
Instruction SLTuOp, Instruction SLTiOp,
Instruction SLTiuOp> {
def : Pat<(select (i32 (setge CRC:$lhs, CRC:$rhs)), DRC:$T, DRC:$F),
(MOVZInst DRC:$T, (SLTOp CRC:$lhs, CRC:$rhs), DRC:$F)>;
def : Pat<(select (i32 (setuge CRC:$lhs, CRC:$rhs)), DRC:$T, DRC:$F),
(MOVZInst DRC:$T, (SLTuOp CRC:$lhs, CRC:$rhs), DRC:$F)>;
def : Pat<(select (i32 (setge CRC:$lhs, immSExt16:$rhs)), DRC:$T, DRC:$F),
(MOVZInst DRC:$T, (SLTiOp CRC:$lhs, immSExt16:$rhs), DRC:$F)>;
def : Pat<(select (i32 (setuge CRC:$lh, immSExt16:$rh)), DRC:$T, DRC:$F),
(MOVZInst DRC:$T, (SLTiuOp CRC:$lh, immSExt16:$rh), DRC:$F)>;
def : Pat<(select (i32 (setle CRC:$lhs, CRC:$rhs)), DRC:$T, DRC:$F),
(MOVZInst DRC:$T, (SLTOp CRC:$rhs, CRC:$lhs), DRC:$F)>;
def : Pat<(select (i32 (setule CRC:$lhs, CRC:$rhs)), DRC:$T, DRC:$F),
(MOVZInst DRC:$T, (SLTuOp CRC:$rhs, CRC:$lhs), DRC:$F)>;
}
multiclass MovzPats1<RegisterClass CRC, RegisterClass DRC,
Instruction MOVZInst, Instruction XOROp> {
def : Pat<(select (i32 (seteq CRC:$lhs, CRC:$rhs)), DRC:$T, DRC:$F),
(MOVZInst DRC:$T, (XOROp CRC:$lhs, CRC:$rhs), DRC:$F)>;
def : Pat<(select (i32 (seteq CRC:$lhs, 0)), DRC:$T, DRC:$F),
(MOVZInst DRC:$T, CRC:$lhs, DRC:$F)>;
}
multiclass MovnPats<RegisterClass CRC, RegisterClass DRC, Instruction MOVNInst,
Instruction XOROp> {
def : Pat<(select (i32 (setne CRC:$lhs, CRC:$rhs)), DRC:$T, DRC:$F),
(MOVNInst DRC:$T, (XOROp CRC:$lhs, CRC:$rhs), DRC:$F)>;
def : Pat<(select CRC:$cond, DRC:$T, DRC:$F),
(MOVNInst DRC:$T, CRC:$cond, DRC:$F)>;
def : Pat<(select (i32 (setne CRC:$lhs, 0)),DRC:$T, DRC:$F),
(MOVNInst DRC:$T, CRC:$lhs, DRC:$F)>;
}
// Instantiation of instructions.
def MOVZ_I_I : CondMovIntInt<CPURegs, CPURegs, 0x0a, "movz">;
def MOVN_I_I : CondMovIntInt<CPURegs, CPURegs, 0x0b, "movn">;
// Instantiation of conditional move patterns.
let Predicates = [HasSlt] in {
defm : MovzPats0Slt<CPURegs, CPURegs, MOVZ_I_I, SLT, SLTu, SLTi, SLTiu>;
}
defm : MovzPats1<CPURegs, CPURegs, MOVZ_I_I, XOR>;
defm : MovnPats<CPURegs, CPURegs, MOVN_I_I, XOR>;
lbdex/chapters/Chapter8_2/Cpu0ISelLowering.h
SDValue lowerSELECT(SDValue Op, SelectionDAG &DAG) const;
lbdex/chapters/Chapter8_2/Cpu0ISelLowering.cpp
Cpu0TargetLowering::Cpu0TargetLowering(const Cpu0TargetMachine &TM,
const Cpu0Subtarget &STI)
: TargetLowering(TM), Subtarget(STI), ABI(TM.getABI()) {
setOperationAction(ISD::SELECT, MVT::i32, Custom);
setOperationAction(ISD::SELECT_CC, MVT::i32, Expand);
setOperationAction(ISD::SELECT_CC, MVT::Other, Expand);
}
SDValue Cpu0TargetLowering::
LowerOperation(SDValue Op, SelectionDAG &DAG) const
{
switch (Op.getOpcode())
{
case ISD::SELECT: return lowerSELECT(Op, DAG);
}
...
}
SDValue Cpu0TargetLowering::
lowerSELECT(SDValue Op, SelectionDAG &DAG) const
{
return Op;
}
Setting ISD::SELECT_CC to “Expand” prevents LLVM from optimizing by merging setcc and select into a single IR instruction select_cc [2].
Next, the LowerOperation() function directly returns the opcode for ISD::SELECT. Finally, the pattern defined in Cpu0CondMov.td translates the select IR into conditional instructions, movz or movn.
Let’s run Chapter8_2 with ch8_2_select.cpp to get the following result.
Again, cpu032II uses slt instead of cmp, resulting in a slight reduction in instruction count.
114-37-150-209:input Jonathan$ ~/llvm/test/build/bin/llc
-march=cpu0 -mcpu=cpu032I -relocation-model=static -filetype=asm ch8_2_select.bc -o -
...
.type _Z11test_movx_1v,@function
...
addiu $2, $zero, 3
movz $2, $3, $4
...
.type _Z11test_movx_2v,@function
...
addiu $2, $zero, 3
movn $2, $3, $4
...
Clang uses the select IR in small basic blocks to reduce branch costs in pipeline machines, as branches can cause pipeline stalls. However, this optimization requires support for conditional instructions [3].
If your backend lacks conditional instruction support but still needs to compile with Clang optimization level -O1 or higher, you can modify Clang to force it to generate traditional branching blocks instead of the select IR.
RISC CPUs were originally designed to take advantage of pipelining, and over time, they have incorporated more instructions. For example, MIPS provides only movz and movn, while ARM supports a wider range of conditional instructions.
We created the Cpu0 instruction set as a simple RISC pipeline machine for educational use in compiler toolchain tutorials. Although Cpu0 includes a cmp instruction, which many programmers are familiar with (as used in ARM), the slt instruction is more efficient in a RISC pipeline.
If you are designing a backend for high-level languages like C/C++, it may be better to use slt instead of cmp, since assembly is rarely used directly, and professional assembly programmers can easily adapt to slt.
File ch8_2_select2.cpp will generate the select IR if compiled with
clang -O1.
lbdex/input/ch8_2_select2.cpp
// The following files will generate IR select when compile with clang -O1 but
// ~/llvm/debug/build/bin/clang -O0 won't generate IR select.
volatile int a = 1;
volatile int b = 2;
int test_movx_3()
{
int c = 0;
if (a < b)
return 1;
else
return 2;
}
int test_movx_4()
{
int c = 0;
if (a)
c = 1;
else
c = 3;
return c;
}
List the conditional statements of C, IR, DAG and Cpu0 instructions as the following table.
C |
if (a < b) c = 1; else c = 3; |
c = a ? 1:3; |
|
IR |
icmp + (eq, ne, sgt, sge, slt, sle) + br |
DAG |
((seteq, setne, setgt, setge, setlt, setle) + setcc) + select |
Cpu0 |
movz, movn |
The file ch8_2_select_global_pic.cpp, mentioned in the chapter “Global Variables”, can now be tested as follows:
lbdex/input/ch8_2_select_global_pic.cpp
volatile int a1 = 1;
volatile int b1 = 2;
int gI1 = 100;
int gJ1 = 50;
int test_select_global_pic()
{
if (a1 < b1)
return gI1;
else
return gJ1;
}
JonathantekiiMac:input Jonathan$ clang -O1 -target mips-unknown-linux-gnu
-c ch8_2_select_global_pic.cpp -emit-llvm -o ch8_2_select_global_pic.bc
JonathantekiiMac:input Jonathan$ ~/llvm/test/build/bin/
llvm-dis ch8_2_select_global_pic.bc -o -
...
@a1 = global i32 1, align 4
@b1 = global i32 2, align 4
@gI1 = global i32 100, align 4
@gJ1 = global i32 50, align 4
; Function Attrs: nounwind
define i32 @_Z18test_select_globalv() #0 {
%1 = load volatile i32* @a1, align 4, !tbaa !1
%2 = load volatile i32* @b1, align 4, !tbaa !1
%3 = icmp slt i32 %1, %2
%gI1.val = load i32* @gI1, align 4
%gJ1.val = load i32* @gJ1, align 4
%.0 = select i1 %3, i32 %gI1.val, i32 %gJ1.val
ret i32 %.0
}
...
JonathantekiiMac:input Jonathan$ ~/llvm/test/build/bin/
llc -march=cpu0 -mcpu=cpu032I -relocation-model=pic -filetype=asm ch8_2_select_global_pic.bc -o -
.section .mdebug.abi32
.previous
.file "ch8_2_select_global_pic.bc"
.text
.globl _Z18test_select_globalv
.align 2
.type _Z18test_select_globalv,@function
.ent _Z18test_select_globalv # @_Z18test_select_globalv
_Z18test_select_globalv:
.frame $sp,0,$lr
.mask 0x00000000,0
.set noreorder
.cpload $t9
.set nomacro
# BB#0:
lui $2, %got_hi(a1)
addu $2, $2, $gp
ld $2, %got_lo(a1)($2)
ld $2, 0($2)
lui $3, %got_hi(b1)
addu $3, $3, $gp
ld $3, %got_lo(b1)($3)
ld $3, 0($3)
cmp $sw, $2, $3
andi $2, $sw, 1
lui $3, %got_hi(gJ1)
addu $3, $3, $gp
ori $3, $3, %got_lo(gJ1)
lui $4, %got_hi(gI1)
addu $4, $4, $gp
ori $4, $4, %got_lo(gI1)
movn $3, $4, $2
ld $2, 0($3)
ld $2, 0($2)
ret $lr
.set macro
.set reorder
.end _Z18test_select_globalv
$tmp0:
.size _Z18test_select_globalv, ($tmp0)-_Z18test_select_globalv
.type a1,@object # @a1
.data
.globl a1
.align 2
a1:
.4byte 1 # 0x1
.size a1, 4
.type b1,@object # @b1
.globl b1
.align 2
b1:
.4byte 2 # 0x2
.size b1, 4
.type gI1,@object # @gI1
.globl gI1
.align 2
gI1:
.4byte 100 # 0x64
.size gI1, 4
.type gJ1,@object # @gJ1
.globl gJ1
.align 2
gJ1:
.4byte 50 # 0x32
.size gJ1, 4
Phi node¶
Since the phi node is widely used in SSA form [5], LLVM applies phi nodes in its IR for optimization purposes as well. Phi nodes are used for live variable analysis. An example in C can be found here [6].
As mentioned on the referenced wiki page, the compiler determines where to insert phi functions by computing dominance frontiers.
The following input demonstrates the benefits of using phi nodes:
lbdex/input/ch8_2_phinode.cpp
int test_phinode(int a , int b, int c)
{
int d = 2;
if (a == 0) {
a = a+1; // a = 1
}
else if (b != 0) {
a = a-1;
}
else if (c == 0) {
a = a+2;
}
d = a + b;
return d;
}
Compile it with a debug build of Clang using the -O3 optimization level as follows:
114-43-212-251:input Jonathan$ ~/llvm/debug/build/bin/clang
-O3 -target mips-unknown-linux-gnu -c ch8_2_phinode.cpp -emit-llvm -o
ch8_2_phinode.bc
114-43-212-251:input Jonathan$ ~/llvm/test/build/bin/llvm-dis
ch8_2_phinode.bc -o -
...
define i32 @_Z12test_phinodeiii(i32 signext %a, i32 signext %b, i32 signext %c) local_unnamed_addr #0 {
entry:
%cmp = icmp eq i32 %a, 0
br i1 %cmp, label %if.end7, label %if.else
if.else: ; preds = %entry
%cmp1 = icmp eq i32 %b, 0
br i1 %cmp1, label %if.else3, label %if.then2
if.then2: ; preds = %if.else
%dec = add nsw i32 %a, -1
br label %if.end7
if.else3: ; preds = %if.else
%cmp4 = icmp eq i32 %c, 0
%add = add nsw i32 %a, 2
%add.a = select i1 %cmp4, i32 %add, i32 %a
br label %if.end7
if.end7: ; preds = %entry, %if.else3, %if.then2
%a.addr.0 = phi i32 [ %dec, %if.then2 ], [ %add.a, %if.else3 ], [ 1, %entry ]
%add8 = add nsw i32 %a.addr.0, %b
ret i32 %add8
}
Because of SSA form, the LLVM IR must use different names for the destination variable a in different basic blocks (e.g., if-then, else). But how is the source variable a in the statement d = a + b; named?
In SSA form, the basic block containing a = a - 1; uses %dec as the destination variable, and the one containing a = a + 2; uses %add. Since the source value for a in d = a + b; comes from different basic blocks, a phi node is used to resolve this.
The phi structure merges values from different control flow paths to produce a single value for use in subsequent instructions.
When compiled with optimization level -O0, Clang does not apply phi nodes. Instead, it uses memory operations like store and load to handle variable values across different basic blocks.
114-43-212-251:input Jonathan$ ~/llvm/debug/build/bin/clang
-O0 -target mips-unknown-linux-gnu -c ch8_2_phinode.cpp -emit-llvm -o
ch8_2_phinode.bc
114-43-212-251:input Jonathan$ ~/llvm/test/build/bin/llvm-dis
ch8_2_phinode.bc -o -
...
define i32 @_Z12test_phinodeiii(i32 signext %a, i32 signext %b, i32 signext %c) #0 {
entry:
%a.addr = alloca i32, align 4
%b.addr = alloca i32, align 4
%c.addr = alloca i32, align 4
%d = alloca i32, align 4
store i32 %a, i32* %a.addr, align 4
store i32 %b, i32* %b.addr, align 4
store i32 %c, i32* %c.addr, align 4
store i32 2, i32* %d, align 4
%0 = load i32, i32* %a.addr, align 4
%cmp = icmp eq i32 %0, 0
br i1 %cmp, label %if.then, label %if.else
if.then: ; preds = %entry
%1 = load i32, i32* %a.addr, align 4
%inc = add nsw i32 %1, 1
store i32 %inc, i32* %a.addr, align 4
br label %if.end7
if.else: ; preds = %entry
%2 = load i32, i32* %b.addr, align 4
%cmp1 = icmp ne i32 %2, 0
br i1 %cmp1, label %if.then2, label %if.else3
if.then2: ; preds = %if.else
%3 = load i32, i32* %a.addr, align 4
%dec = add nsw i32 %3, -1
store i32 %dec, i32* %a.addr, align 4
br label %if.end6
if.else3: ; preds = %if.else
%4 = load i32, i32* %c.addr, align 4
%cmp4 = icmp eq i32 %4, 0
br i1 %cmp4, label %if.then5, label %if.end
if.then5: ; preds = %if.else3
%5 = load i32, i32* %a.addr, align 4
%add = add nsw i32 %5, 2
store i32 %add, i32* %a.addr, align 4
br label %if.end
if.end: ; preds = %if.then5, %if.else3
br label %if.end6
if.end6: ; preds = %if.end, %if.then2
br label %if.end7
if.end7: ; preds = %if.end6, %if.then
%6 = load i32, i32* %a.addr, align 4
%7 = load i32, i32* %b.addr, align 4
%add8 = add nsw i32 %6, %7
store i32 %add8, i32* %d, align 4
%8 = load i32, i32* %d, align 4
ret i32 %8
}
When compiled with clang -O3, the compiler generates phi functions.
The phi function assigns a virtual register value directly from multiple
basic blocks.
In contrast, compiling with clang -O0 does not generate phi nodes.
Instead, it assigns the virtual register value by loading from a stack slot,
which is written in each of the multiple basic blocks.
In this example, the pointer %a.addr points to the stack slot. The store instructions:
store i32 %inc, i32* %a.addr, align 4in label if.then:
store i32 %dec, i32* %a.addr, align 4in label if.then2:
store i32 %add, i32* %a.addr, align 4in label if.then5:
These instructions show that three store`s are needed in the `-O0`` version.
With optimization, the compiler may determine that the condition a == 0 is
always true. In such cases, the phi node version may produce better results,
since the -O0 version uses load and store with the pointer %a.addr,
which can hinder further optimization.
Compiler textbooks discuss how the Control Flow Graph (CFG) analysis uses dominance frontier calculations to determine where to insert phi nodes. After inserting phi nodes, the compiler performs global optimization on the CFG and eventually removes the phi nodes by replacing them with load and store instructions.
If you are interested in more technical details beyond what’s provided in the wiki reference, see [7] for phi node coverage, or refer to [8] for dominator tree analysis if you have the book.
Phi In Optimization¶
Optimization in SSA φ-Nodes and LLVM Passes
This section introduces the theoretical foundations of φ-nodes in SSA form, explains how φ-nodes enable compiler optimizations, and surveys LLVM passes that manipulate, simplify, or rely on φ-nodes. The material is suitable for compiler courses, backend engineering documentation, or LLVM-based curriculum modules.
Introduction
Static Single Assignment (SSA) form is one of the most influential intermediate representations in modern compilers. By enforcing that each variable is assigned exactly once, SSA enables precise data-flow reasoning and exposes opportunities for aggressive optimization.
At the center of SSA lies the φ-node, a pseudo-instruction that merges values coming from different control-flow paths. Although simple in concept, φ-nodes are essential for:
constant propagation
redundancy elimination
control-flow simplification
loop optimization
value numbering and equivalence reasoning
This chapter covers:
the theory behind φ-nodes and SSA construction
optimizations enabled by φ-nodes
LLVM passes that manipulate or depend on φ-nodes
practical considerations for implementing φ-aware transformations
Theoretical Foundations of φ-Nodes
2.1 SSA Form and the Need for φ-Nodes
SSA requires that each variable have a single static assignment. When control flow merges, multiple reaching definitions may exist. A φ-node resolves this ambiguity:
%x3 = phi i32 [ %x1, %P1 ], [ %x2, %P2 ]
This means:
if control arrives from predecessor
P1→ usex1if control arrives from predecessor
P2→ usex2
The φ-node is a compile-time abstraction, not a runtime instruction.
2.2 Dominance and Placement of φ-Nodes
The classical Cytron et al. algorithm inserts φ-nodes at dominance
frontiers. A φ-node for variable v is placed in block B if:
Bis in the dominance frontier of a block that assignsvBis reachable from multiple definitions ofv
This produces minimal SSA form.
2.3 Properties of φ-Nodes Relevant to Optimization
Key properties include:
Value identity: each φ defines a new SSA name.
Equivalence exposure: identical incoming values imply redundancy.
Unreachable path detection: dead predecessors simplify φ-nodes.
Loop structure representation: induction variables naturally use φ-nodes.
Optimizations Enabled by φ-Nodes
3.1 Constant Propagation and Folding
If all incoming values are constants, the φ-node collapses:
%x = phi i32 [ 3, %A ], [ 3, %B ]; → x = 3
This enables:
dead code elimination
branch simplification
further constant folding
3.2 Copy and Redundancy Elimination
If all incoming SSA names are identical:
%x = phi i32 [ %a, %A ], [ %a, %B ]; → x = a
This reduces renaming noise and simplifies data flow.
3.3 Dead φ-Node Elimination
A φ-node is dead if:
its result is unused, or
all incoming edges are dead
Dead φ-nodes often cascade, enabling further cleanup.
3.4 Control-Flow Simplification
When branches become constant, φ-nodes collapse:
%x = phi i32 [ %a, %A ], [ %b, %B ]; → x = a
This supports:
jump threading
block merging
CFG simplification
3.5 Loop Optimizations
φ-nodes identify:
induction variables
loop-carried dependencies
reduction patterns
This enables:
Loop-Invariant Code Motion (LICM)
strength reduction
induction variable simplification
loop unrolling and vectorization
LLVM Passes Related to φ-Nodes
LLVM contains many passes that either manipulate φ-nodes directly or depend on them for analysis.
4.1 Passes That Directly Modify or Simplify φ-Nodes
mem2reg (PromoteMemoryToRegisterPass)
Converts stack variables to SSA registers.
Inserts φ-nodes using dominance frontiers.
SROA (Scalar Replacement of Aggregates)
Breaks aggregates into scalars.
Introduces new φ-nodes for scalarized fields.
InstCombine
Simplifies φ-nodes.
Removes redundant φ-nodes.
Folds constant φ-nodes.
SimplifyCFG
Removes unreachable predecessors.
Updates φ-nodes accordingly.
Merges blocks and merges φ-nodes.
CorrelatedValuePropagation
Uses branch correlation to simplify φ-nodes.
4.2 Passes That Use φ-Nodes for Analysis
GVN (Global Value Numbering)
Uses φ-translation to compare values across blocks.
Detects equivalent expressions.
SCCP (Sparse Conditional Constant Propagation)
Tracks constant values through φ-nodes.
Eliminates dead branches and simplifies φ-nodes.
LICM (Loop-Invariant Code Motion)
Identifies loop invariants via φ-nodes.
Moves invariant code out of loops.
LoopSimplify
Normalizes loop structure.
Ensures canonical induction φ-nodes exist.
IndVarSimplify
Rewrites induction φ-nodes into canonical form.
Enables strength reduction and vectorization.
4.3 Passes That Remove or Rewrite φ-Nodes
DemotePHIToStack
Converts φ-nodes back to memory operations.
Used in lowering or debugging.
SSAUpdater (utility)
Rewrites SSA form during transformations.
Inserts or removes φ-nodes as needed.
Practical Considerations for φ-Aware Optimizations
5.1 Maintaining SSA Consistency
Transformations must ensure:
each φ-node has one incoming value per predecessor
predecessor order matches CFG edge order
removing edges updates φ-nodes
5.2 Avoiding Critical Edges
Some optimizations require splitting critical edges to maintain valid φ-node semantics.
5.3 Handling Cyclic φ-Nodes
Loops often produce mutually recursive φ-nodes. Optimizations must detect:
induction variables
loop-carried dependencies
reduction patterns
5.4 φ-Translation
Analyses such as GVN and PRE require translating values across control flow by following φ-node edges. This is essential for correctness.
Summary
φ-nodes are a structural backbone of SSA form. They:
represent merged values across control flow
enable precise data-flow reasoning
support loop analysis and transformation
are manipulated by many LLVM optimization passes
Understanding φ-nodes is essential for designing compiler optimizations, implementing SSA-based transformations, and working effectively with LLVM IR.
LLVM IR φ-Node Optimization Examples¶
This section presents LLVM IR examples before and after key φ-node optimizations. Each transformation illustrates how SSA form enables simplification, redundancy elimination, and loop optimization.
All code blocks use LLVM IR syntax.
Constant Propagation and Folding
1.1 Constant Folding of a φ with Identical Constants
Before:
define i32 @example_const_phi(i1 %cond) {
entry:
br i1 %cond, label %then, label %else
then:
br label %merge
else:
br label %merge
merge:
%x = phi i32 [ 3, %then ], [ 3, %else ]
ret i32 %x
}
After:
define i32 @example_const_phi(i1 %cond) {
entry:
br i1 %cond, label %then, label %else
then:
br label %merge
else:
br label %merge
merge:
ret i32 3
}
1.2 Constant Propagation into a φ
Before:
define i32 @example_sccp(i1 %cond) {
entry:
br i1 %cond, label %then, label %else
then:
br label %merge
else:
br label %merge
merge:
%x = phi i32 [ 42, %then ], [ 13, %else ]
%y = add i32 %x, 1
ret i32 %y
}
After SCCP (assuming %cond is always true):
define i32 @example_sccp(i1 %cond) {
entry:
br label %merge
merge:
ret i32 43
}
Redundant φ Elimination
2.1 φ with Identical SSA Names
Before:
define i32 @example_redundant_phi(i32 %a, i1 %cond) {
entry:
br i1 %cond, label %then, label %else
then:
%v_then = add i32 %a, 0
br label %merge
else:
%v_else = add i32 %a, 0
br label %merge
merge:
%v = phi i32 [ %v_then, %then ], [ %v_else, %else ]
ret i32 %v
}
After InstCombine:
define i32 @example_redundant_phi(i32 %a, i1 %cond) {
entry:
br label %merge
merge:
ret i32 %a
}
2.2 Collapsing Copy φ-Chains
Before:
define i32 @example_copy_phi(i32 %a, i32 %b, i1 %cond) {
entry:
br i1 %cond, label %then, label %else
then:
%x = phi i32 [ %a, %entry ]
br label %merge
else:
%x2 = phi i32 [ %b, %entry ]
br label %merge
merge:
%y = phi i32 [ %x, %then ], [ %x2, %else ]
ret i32 %y
}
After Simplification:
define i32 @example_copy_phi(i32 %a, i32 %b, i1 %cond) {
entry:
br i1 %cond, label %then, label %else
then:
br label %merge
else:
br label %merge
merge:
%y = phi i32 [ %a, %then ], [ %b, %else ]
ret i32 %y
}
Dead φ-Node Elimination
3.1 Unused φ
Before:
define i32 @example_dead_phi(i32 %a, i32 %b, i1 %cond) {
entry:
br i1 %cond, label %then, label %else
then:
br label %merge
else:
br label %merge
merge:
%x = phi i32 [ %a, %then ], [ %b, %else ]
ret i32 0
}
After DCE:
define i32 @example_dead_phi(i32 %a, i32 %b, i1 %cond) {
entry:
br i1 %cond, label %then, label %else
then:
br label %merge
else:
br label %merge
merge:
ret i32 0
}
3.2 Cascading Dead φs
Before:
define i32 @example_cascade_dead_phi(i32 %a, i32 %b, i1 %cond) {
entry:
br i1 %cond, label %then, label %else
then:
br label %merge
else:
br label %merge
merge:
%x = phi i32 [ %a, %then ], [ %b, %else ]
%y = add i32 %x, 0
ret i32 1
}
After DCE + InstCombine:
define i32 @example_cascade_dead_phi(i32 %a, i32 %b, i1 %cond) {
entry:
br i1 %cond, label %then, label %else
then:
br label %merge
else:
br label %merge
merge:
ret i32 1
}
Control-Flow Simplification and φ
4.1 Branch Known Constant → φ Collapse
Before:
define i32 @example_simplifycfg(i32 %a) {
entry:
%cmp = icmp eq i32 %a, 0
br i1 %cmp, label %zero, label %nonzero
zero:
br label %merge
nonzero:
br label %merge
merge:
%x = phi i32 [ 0, %zero ], [ 1, %nonzero ]
ret i32 %x
}
After SimplifyCFG:
define i32 @example_simplifycfg(i32 %a) {
entry:
br label %merge
merge:
ret i32 0
}
4.2 Block Merging
Before:
define i32 @example_block_merge(i32 %a, i1 %cond) {
entry:
br i1 %cond, label %then, label %else
then:
%x1 = add i32 %a, 1
br label %merge
else:
%x2 = add i32 %a, 1
br label %merge
merge:
%x = phi i32 [ %x1, %then ], [ %x2, %else ]
ret i32 %x
}
After SimplifyCFG + InstCombine:
define i32 @example_block_merge(i32 %a, i1 %cond) {
entry:
%x = add i32 %a, 1
ret i32 %x
}
Loop Optimizations Using φ-Nodes
5.1 Canonical Induction Variable
Before:
define i32 @sum(i32* %arr, i32 %n) {
entry:
br label %loop
loop:
%i = phi i32 [ 0, %entry ], [ %i.next, %loop ]
%sum = phi i32 [ 0, %entry ], [ %sum.next, %loop ]
%inbounds = icmp slt i32 %i, %n
br i1 %inbounds, label %body, label %exit
body:
%ptr = getelementptr inbounds i32, i32* %arr, i32 %i
%val = load i32, i32* %ptr
%sum.next = add i32 %sum, %val
%i.next = add i32 %i, 1
br label %loop
exit:
ret i32 %sum
}
After IndVarSimplify (conceptual):
define i32 @sum(i32* %arr, i32 %n) {
entry:
br label %loop
loop:
%iv = phi i64 [ 0, %entry ], [ %iv.next, %loop ]
%sum = phi i32 [ 0, %entry ], [ %sum.next, %loop ]
%iv.trunc = trunc i64 %iv to i32
%inbounds = icmp slt i32 %iv.trunc, %n
br i1 %inbounds, label %body, label %exit
body:
%ptr = getelementptr inbounds i32, i32* %arr, i64 %iv
%val = load i32, i32* %ptr
%sum.next = add i32 %sum, %val
%iv.next = add i64 %iv, 1
br label %loop
exit:
ret i32 %sum
}
5.2 Loop-Invariant Code Motion (LICM)
Before:
define void @example_licm(i32* %p, i32* %q, i32 %n) {
entry:
br label %loop
loop:
%i = phi i32 [ 0, %entry ], [ %i.next, %loop ]
%inb = icmp slt i32 %i, %n
br i1 %inb, label %body, label %exit
body:
%c = load i32, i32* %q
%ptr = getelementptr inbounds i32, i32* %p, i32 %i
store i32 %c, i32* %ptr
%i.next = add i32 %i, 1
br label %loop
exit:
ret void
}
After LICM:
define void @example_licm(i32* %p, i32* %q, i32 %n) {
entry:
%c = load i32, i32* %q
br label %loop
loop:
%i = phi i32 [ 0, %entry ], [ %i.next, %loop ]
%inb = icmp slt i32 %i, %n
br i1 %inb, label %body, label %exit
body:
%ptr = getelementptr inbounds i32, i32* %p, i32 %i
store i32 %c, i32* %ptr
%i.next = add i32 %i, 1
br label %loop
exit:
ret void
}
mem2reg: Introducing φ-Nodes
6.1 Before mem2reg
define i32 @example_mem2reg(i1 %cond) {
entry:
%x = alloca i32, align 4
store i32 0, i32* %x
br i1 %cond, label %then, label %else
then:
store i32 1, i32* %x
br label %merge
else:
store i32 2, i32* %x
br label %merge
merge:
%x.load = load i32, i32* %x
ret i32 %x.load
}
6.2 After mem2reg
define i32 @example_mem2reg(i1 %cond) {
entry:
br i1 %cond, label %then, label %else
then:
br label %merge
else:
br label %merge
merge:
%x.promoted = phi i32 [ 1, %then ], [ 2, %else ]
ret i32 %x.promoted
}
RISC CPU knowledge¶
As mentioned in the previous section, Cpu0 is a RISC (Reduced Instruction Set Computer) CPU with a 5-stage pipeline. RISC CPUs dominate the world today. Even the x86 architecture, traditionally classified as CISC (Complex Instruction Set Computer), internally translates its complex instructions into micro-instructions that are pipelined like RISC.
Understanding RISC concepts can be very helpful and rewarding for compiler design.
Below are two excellent and popular books we have read and recommend for reference. Although there are many books on computer architecture, these two stand out for their clarity and depth:
Computer Organization and Design: The Hardware/Software Interface (The Morgan Kaufmann Series in Computer Architecture and Design)
Computer Architecture: A Quantitative Approach (The Morgan Kaufmann Series in Computer Architecture and Design)
The book Computer Organization and Design (available in 4 editions at the time of writing) serves as an introductory text, while Computer Architecture: A Quantitative Approach (with 5 editions) explores more advanced and in-depth topics in CPU architecture.
Both books use the MIPS CPU as a reference example, since MIPS is more RISC-like than many other commercial CPUs.