Backend structure¶
From Fig. 11, llvm compiler transfer from llvm-ir to assembly or binary object with the following data structure as Fig. 16.

Fig. 16 LLVM data structure used in different stages¶
Cpu0 backend supports the following backend compiler, assembler and disassembler as Fig. 17, Fig. 18 and Fig. 19. However only the green part for printing assembly is implemented in this chapter. Others are implemented in later chapters Fig. 31, Fig. 55 and Fig. 50.
![digraph G {
rankdir=LR;
subgraph clusterDisa {
label = "Disassembler";
objdump [label="llvm-objdump", shape=record];
obj_dis [label="binary obj"];
asm_dis [label="assembly"];
obj_dis -> objdump;
objdump -> asm_dis [label="-d"];
}
subgraph clusterAsm {
label = "Assembler";
llc_asm [label="llc", shape=record];
asm_asm [label="assembly"];
obj_asm [label="binary obj"];
asm_asm -> llc_asm;
llc_asm -> obj_asm [label="-filetype=obj"];
}
subgraph clusterLlc {
label = "Backend compiler";
llc_llc [label="llc", shape=record];
asm_llc [label="assembly"];
obj_llc [label="binary obj"];
"llvm-ir" -> llc_llc;
llc_llc -> asm_llc [label="-filetype=asm"];
llc_llc -> obj_llc [label="-filetype=obj"];
}
}](_images/graphviz-a869858052b9b9e5de29795804e821090add87a3.png)
Fig. 17 Backend compiler, assembler and disassembler of Cpu0¶
![digraph G {
rankdir=LR;
"MCInst" -> "assembly" [label="printInst()"];
"MCInst" -> "binary object" [label="emitInstruction()"];
"assembly" -> "MCInst" [label="MatchAndEmitInstruction()"];
"binary object" -> "MCInst" [label="getInstruction()"];
}](_images/graphviz-1f74d88c9c587bf3b33dda6c4f158714db318cb6.png)
Fig. 18 Encode, assembler and disassembler¶
![digraph G {
rankdir=TB;
llc [label="llc", shape=record];
llvm_objdump [label="llvm-objdump", shape=record];
asm_file [label="asm file", shape=record];
bin_file [labe="binary file", shape=record];
llc -> EI_Asm [label="[input-file=llvm-ir]\nMachineInstr"];
EI_Asm -> "printInst()" [label="MCInst"];
EI_Asm -> EI_MC [label="MCInst"];
"printInst()" -> asm_file;
EI_MC -> bin_file;
llc -> "MatchAndEmitInstruction()" [label="[input-file=asm]\nOpcode,Operands"];
"MatchAndEmitInstruction()" -> EI_MC [label="MCInst"];
llvm_objdump -> "getInstruction()" [label="[input-file=binary]\nBytes"];
llvm_objdump -> "printInst()" [label="MCInst"];
subgraph clusterCpu0Asm {
label = "Cpu0AsmPrinter.cpp";
EI_Asm [label="emitInstruction()", style="filled,bold", fillcolor="lightgreen"];
}
subgraph clusterCpu0InstPrinter {
label = "Cpu0InstPrinter.cpp\nCpu0GenAsmWrite.inc(from Cpu0InstrInfo.td)";
"printInst()" [style="filled,bold", fillcolor="lightgreen"];
}
subgraph clusterCpu0MC {
label = "Cpu0MCCodeEmitter.cpp\nCpu0GenMCCodeEmitter.inc(from Cpu0InstrInfo.td)";
EI_MC [label="emitInstruction()"];
}
subgraph clusterCpu0AsmParser {
label = "Cpu0AsmParser.cpp\nCpu0GenAsmMatcher.inc(from Cpu0InstrInfo.td)";
"MatchAndEmitInstruction()";
}
subgraph clusterCpu0Dis {
label = "Cpu0Disassembler.cpp\nCpu0GenDisassemblerTables.inc(from Cpu0InstrInfo.td)";
"getInstruction()";
}
}](_images/graphviz-b359f207b814de3c237849742106c7b79e37f4ab.png)
Fig. 19 The structure for backend compiler, assembler and disassembler of Cpu0¶
Bytes: 4-byte (32-bits) for Cpu0.
Each MInst contains one single instruction.
The encoder extracts information from MachineInstr and places it into MCInst. It then calls printInst() to generate assembly instructions or emitInstruction() to output binary instruction.
The assembler calls MatchAndEmitInstruction() to convert assembly back into MCInst, then calls emitInstruction() to output binary instruction.
The disassembler calls getInstruction() to convert binary instructions back into MCInst, then calls printInst() to generate assembly instruction.
The emitInstruction() of Cpu0MCCodeEmitter.cpp: encode binary for an instruction reused for both llc (compiler) and llc (assembler).
The printInst() of Cpu0InstPrinter.cpp: print assembly code for an instruction reused for both llc (compiler) and llvm-objdump (disassembler).
This chapter first introduces the backend class inheritance tree and its class members. Then, following the backend structure, we add individual class implementations in each section. By the end of this chapter, we will have a backend capable of compiling LLVM intermediate code into Cpu0 assembly code.
Many lines of code are introduced in this chapter. Most of them are common across different backends, except for the backend name (e.g., Cpu0 or Mips). In fact, we copy almost all the code from Mips and replace the name with Cpu0. Beyond understanding DAG pattern matching in theoretical compilers and the LLVM code generation phase, please focus on the relationships between classes in this backend structure. Once you grasp the structure, you will be able to create your backend as quickly as we did, even though this chapter introduces around 5000 lines of code.
TargetMachine structure¶
lbdex/chapters/Chapter3_1/Cpu0TargetObjectFile.h
//===-- llvm/Target/Cpu0TargetObjectFile.h - Cpu0 Object Info ---*- C++ -*-===//
//
// The LLVM Compiler Infrastructure
//
// This file is distributed under the University of Illinois Open Source
// License. See LICENSE.TXT for details.
//
//===----------------------------------------------------------------------===//
#ifndef LLVM_LIB_TARGET_CPU0_CPU0TARGETOBJECTFILE_H
#define LLVM_LIB_TARGET_CPU0_CPU0TARGETOBJECTFILE_H
#include "Cpu0Config.h"
#include "Cpu0TargetMachine.h"
#include "llvm/CodeGen/TargetLoweringObjectFileImpl.h"
namespace llvm {
class Cpu0TargetMachine;
class Cpu0TargetObjectFile : public TargetLoweringObjectFileELF {
MCSection *SmallDataSection;
MCSection *SmallBSSSection;
const Cpu0TargetMachine *TM;
public:
void Initialize(MCContext &Ctx, const TargetMachine &TM) override;
};
} // end namespace llvm
#endif
lbdex/chapters/Chapter3_1/Cpu0TargetObjectFile.cpp
//===-- Cpu0TargetObjectFile.cpp - Cpu0 Object Files ----------------------===//
//
// The LLVM Compiler Infrastructure
//
// This file is distributed under the University of Illinois Open Source
// License. See LICENSE.TXT for details.
//
//===----------------------------------------------------------------------===//
#include "Cpu0TargetObjectFile.h"
#include "Cpu0Subtarget.h"
#include "Cpu0TargetMachine.h"
#include "llvm/BinaryFormat/ELF.h"
#include "llvm/IR/DataLayout.h"
#include "llvm/IR/DerivedTypes.h"
#include "llvm/IR/GlobalVariable.h"
#include "llvm/MC/MCContext.h"
#include "llvm/MC/MCSectionELF.h"
#include "llvm/Support/CommandLine.h"
#include "llvm/Target/TargetMachine.h"
using namespace llvm;
static cl::opt<unsigned>
SSThreshold("cpu0-ssection-threshold", cl::Hidden,
cl::desc("Small data and bss section threshold size (default=8)"),
cl::init(8));
void Cpu0TargetObjectFile::Initialize(MCContext &Ctx, const TargetMachine &TM){
TargetLoweringObjectFileELF::Initialize(Ctx, TM);
InitializeELF(TM.Options.UseInitArray);
SmallDataSection = getContext().getELFSection(
".sdata", ELF::SHT_PROGBITS, ELF::SHF_WRITE | ELF::SHF_ALLOC);
SmallBSSSection = getContext().getELFSection(".sbss", ELF::SHT_NOBITS,
ELF::SHF_WRITE | ELF::SHF_ALLOC);
this->TM = &static_cast<const Cpu0TargetMachine &>(TM);
}
lbdex/chapters/Chapter3_1/Cpu0TargetMachine.h
//===-- Cpu0TargetMachine.h - Define TargetMachine for Cpu0 -----*- C++ -*-===//
//
// The LLVM Compiler Infrastructure
//
// This file is distributed under the University of Illinois Open Source
// License. See LICENSE.TXT for details.
//
//===----------------------------------------------------------------------===//
//
// This file declares the Cpu0 specific subclass of TargetMachine.
//
//===----------------------------------------------------------------------===//
#ifndef LLVM_LIB_TARGET_CPU0_CPU0TARGETMACHINE_H
#define LLVM_LIB_TARGET_CPU0_CPU0TARGETMACHINE_H
#include "Cpu0Config.h"
#include "MCTargetDesc/Cpu0ABIInfo.h"
#include "Cpu0Subtarget.h"
#include "llvm/CodeGen/Passes.h"
#include "llvm/CodeGen/SelectionDAGISel.h"
#include "llvm/CodeGen/TargetFrameLowering.h"
#include "llvm/Support/CodeGen.h"
#include "llvm/Target/TargetMachine.h"
namespace llvm {
class formatted_raw_ostream;
class Cpu0RegisterInfo;
class Cpu0TargetMachine : public LLVMTargetMachine {
bool isLittle;
std::unique_ptr<TargetLoweringObjectFile> TLOF;
// Selected ABI
Cpu0ABIInfo ABI;
Cpu0Subtarget DefaultSubtarget;
mutable StringMap<std::unique_ptr<Cpu0Subtarget>> SubtargetMap;
public:
Cpu0TargetMachine(const Target &T, const Triple &TT, StringRef CPU,
StringRef FS, const TargetOptions &Options,
Optional<Reloc::Model> RM, Optional<CodeModel::Model> CM,
CodeGenOpt::Level OL, bool JIT, bool isLittle);
~Cpu0TargetMachine() override;
const Cpu0Subtarget *getSubtargetImpl() const {
return &DefaultSubtarget;
}
const Cpu0Subtarget *getSubtargetImpl(const Function &F) const override;
// Pass Pipeline Configuration
TargetPassConfig *createPassConfig(PassManagerBase &PM) override;
TargetLoweringObjectFile *getObjFileLowering() const override {
return TLOF.get();
}
bool isLittleEndian() const { return isLittle; }
const Cpu0ABIInfo &getABI() const { return ABI; }
};
/// Cpu0ebTargetMachine - Cpu032 big endian target machine.
///
class Cpu0ebTargetMachine : public Cpu0TargetMachine {
virtual void anchor();
public:
Cpu0ebTargetMachine(const Target &T, const Triple &TT, StringRef CPU,
StringRef FS, const TargetOptions &Options,
Optional<Reloc::Model> RM, Optional<CodeModel::Model> CM,
CodeGenOpt::Level OL, bool JIT);
};
/// Cpu0elTargetMachine - Cpu032 little endian target machine.
///
class Cpu0elTargetMachine : public Cpu0TargetMachine {
virtual void anchor();
public:
Cpu0elTargetMachine(const Target &T, const Triple &TT, StringRef CPU,
StringRef FS, const TargetOptions &Options,
Optional<Reloc::Model> RM, Optional<CodeModel::Model> CM,
CodeGenOpt::Level OL, bool JIT);
};
} // End llvm namespace
#endif
lbdex/chapters/Chapter3_1/Cpu0TargetMachine.cpp
//===-- Cpu0TargetMachine.cpp - Define TargetMachine for Cpu0 -------------===//
//
// The LLVM Compiler Infrastructure
//
// This file is distributed under the University of Illinois Open Source
// License. See LICENSE.TXT for details.
//
//===----------------------------------------------------------------------===//
//
// Implements the info about Cpu0 target spec.
//
//===----------------------------------------------------------------------===//
#include "Cpu0TargetMachine.h"
#include "Cpu0.h"
#include "Cpu0Subtarget.h"
#include "Cpu0TargetObjectFile.h"
#include "llvm/IR/Attributes.h"
#include "llvm/IR/Function.h"
#include "llvm/Support/CodeGen.h"
#include "llvm/CodeGen/Passes.h"
#include "llvm/CodeGen/TargetPassConfig.h"
#include "llvm/Support/TargetRegistry.h"
#include "llvm/Target/TargetOptions.h"
using namespace llvm;
#define DEBUG_TYPE "cpu0"
extern "C" void LLVMInitializeCpu0Target() {
// Register the target.
//- Big endian Target Machine
RegisterTargetMachine<Cpu0ebTargetMachine> X(TheCpu0Target);
//- Little endian Target Machine
RegisterTargetMachine<Cpu0elTargetMachine> Y(TheCpu0elTarget);
}
static std::string computeDataLayout(const Triple &TT, StringRef CPU,
const TargetOptions &Options,
bool isLittle) {
std::string Ret = "";
// There are both little and big endian cpu0.
if (isLittle)
Ret += "e";
else
Ret += "E";
Ret += "-m:m";
// Pointers are 32 bit on some ABIs.
Ret += "-p:32:32";
// 8 and 16 bit integers only need to have natural alignment, but try to
// align them to 32 bits. 64 bit integers have natural alignment.
Ret += "-i8:8:32-i16:16:32-i64:64";
// 32 bit registers are always available and the stack is at least 64 bit
// aligned.
Ret += "-n32-S64";
return Ret;
}
static Reloc::Model getEffectiveRelocModel(bool JIT,
Optional<Reloc::Model> RM) {
if (!RM.hasValue() || JIT)
return Reloc::Static;
return *RM;
}
// DataLayout --> Big-endian, 32-bit pointer/ABI/alignment
// The stack is always 8 byte aligned
// On function prologue, the stack is created by decrementing
// its pointer. Once decremented, all references are done with positive
// offset from the stack/frame pointer, using StackGrowsUp enables
// an easier handling.
// Using CodeModel::Large enables different CALL behavior.
Cpu0TargetMachine::Cpu0TargetMachine(const Target &T, const Triple &TT,
StringRef CPU, StringRef FS,
const TargetOptions &Options,
Optional<Reloc::Model> RM,
Optional<CodeModel::Model> CM,
CodeGenOpt::Level OL, bool JIT,
bool isLittle)
//- Default is big endian
: LLVMTargetMachine(T, computeDataLayout(TT, CPU, Options, isLittle), TT,
CPU, FS, Options, getEffectiveRelocModel(JIT, RM),
getEffectiveCodeModel(CM, CodeModel::Small), OL),
isLittle(isLittle), TLOF(std::make_unique<Cpu0TargetObjectFile>()),
ABI(Cpu0ABIInfo::computeTargetABI()),
DefaultSubtarget(TT, CPU, FS, isLittle, *this) {
// initAsmInfo will display features by llc -march=cpu0 -mcpu=help on 3.7 but
// not on 3.6
initAsmInfo();
}
Cpu0TargetMachine::~Cpu0TargetMachine() {}
void Cpu0ebTargetMachine::anchor() { }
Cpu0ebTargetMachine::Cpu0ebTargetMachine(const Target &T, const Triple &TT,
StringRef CPU, StringRef FS,
const TargetOptions &Options,
Optional<Reloc::Model> RM,
Optional<CodeModel::Model> CM,
CodeGenOpt::Level OL, bool JIT)
: Cpu0TargetMachine(T, TT, CPU, FS, Options, RM, CM, OL, JIT, false) {}
void Cpu0elTargetMachine::anchor() { }
Cpu0elTargetMachine::Cpu0elTargetMachine(const Target &T, const Triple &TT,
StringRef CPU, StringRef FS,
const TargetOptions &Options,
Optional<Reloc::Model> RM,
Optional<CodeModel::Model> CM,
CodeGenOpt::Level OL, bool JIT)
: Cpu0TargetMachine(T, TT, CPU, FS, Options, RM, CM, OL, JIT, true) {}
const Cpu0Subtarget *
Cpu0TargetMachine::getSubtargetImpl(const Function &F) const {
std::string CPU = TargetCPU;
std::string FS = TargetFS;
auto &I = SubtargetMap[CPU + FS];
if (!I) {
// This needs to be done before we create a new subtarget since any
// creation will depend on the TM and the code generation flags on the
// function that reside in TargetOptions.
resetTargetOptions(F);
I = std::make_unique<Cpu0Subtarget>(TargetTriple, CPU, FS, isLittle,
*this);
}
return I.get();
}
namespace {
//@Cpu0PassConfig {
/// Cpu0 Code Generator Pass Configuration Options.
class Cpu0PassConfig : public TargetPassConfig {
public:
Cpu0PassConfig(Cpu0TargetMachine &TM, PassManagerBase &PM)
: TargetPassConfig(TM, PM) {}
Cpu0TargetMachine &getCpu0TargetMachine() const {
return getTM<Cpu0TargetMachine>();
}
const Cpu0Subtarget &getCpu0Subtarget() const {
return *getCpu0TargetMachine().getSubtargetImpl();
}
};
} // namespace
TargetPassConfig *Cpu0TargetMachine::createPassConfig(PassManagerBase &PM) {
return new Cpu0PassConfig(*this, PM);
}
include/llvm/Target/TargetInstInfo.h
class TargetInstrInfo : public MCInstrInfo {
TargetInstrInfo(const TargetInstrInfo &) = delete;
void operator=(const TargetInstrInfo &) = delete;
public:
...
}
...
class TargetInstrInfoImpl : public TargetInstrInfo {
protected:
TargetInstrInfoImpl(int CallFrameSetupOpcode = -1,
int CallFrameDestroyOpcode = -1)
: TargetInstrInfo(CallFrameSetupOpcode, CallFrameDestroyOpcode) {}
public:
...
}
lbdex/chapters/Chapter3_1/Cpu0.td
include "Cpu0CallingConv.td"
lbdex/chapters/Chapter3_1/Cpu0CallingConv.td
//===-- Cpu0CallingConv.td - Calling Conventions for Cpu0 --*- tablegen -*-===//
//
// The LLVM Compiler Infrastructure
//
// This file is distributed under the University of Illinois Open Source
// License. See LICENSE.TXT for details.
//
//===----------------------------------------------------------------------===//
// This describes the calling conventions for Cpu0 architecture.
//===----------------------------------------------------------------------===//
/// CCIfSubtarget - Match if the current subtarget has a feature F.
class CCIfSubtarget<string F, CCAction A>:
CCIf<!strconcat("State.getTarget().getSubtarget<Cpu0Subtarget>().", F), A>;
def CSR_O32 : CalleeSavedRegs<(add LR, FP,
(sequence "S%u", 1, 0))>;
lbdex/chapters/Chapter3_1/Cpu0FrameLowering.h
//===-- Cpu0FrameLowering.h - Define frame lowering for Cpu0 ----*- C++ -*-===//
//
// The LLVM Compiler Infrastructure
//
// This file is distributed under the University of Illinois Open Source
// License. See LICENSE.TXT for details.
//
//===----------------------------------------------------------------------===//
//
//
//
//===----------------------------------------------------------------------===//
#ifndef LLVM_LIB_TARGET_CPU0_CPU0FRAMELOWERING_H
#define LLVM_LIB_TARGET_CPU0_CPU0FRAMELOWERING_H
#include "Cpu0Config.h"
#include "Cpu0.h"
#include "llvm/CodeGen/TargetFrameLowering.h"
namespace llvm {
class Cpu0Subtarget;
class Cpu0FrameLowering : public TargetFrameLowering {
protected:
const Cpu0Subtarget &STI;
public:
explicit Cpu0FrameLowering(const Cpu0Subtarget &sti, unsigned Alignment)
: TargetFrameLowering(StackGrowsDown, Align(Alignment), 0, Align(Alignment)),
STI(sti) {
}
static const Cpu0FrameLowering *create(const Cpu0Subtarget &ST);
bool hasFP(const MachineFunction &MF) const override;
};
/// Create Cpu0FrameLowering objects.
const Cpu0FrameLowering *createCpu0SEFrameLowering(const Cpu0Subtarget &ST);
} // End llvm namespace
#endif
lbdex/chapters/Chapter3_1/Cpu0FrameLowering.cpp
//===-- Cpu0FrameLowering.cpp - Cpu0 Frame Information --------------------===//
//
// The LLVM Compiler Infrastructure
//
// This file is distributed under the University of Illinois Open Source
// License. See LICENSE.TXT for details.
//
//===----------------------------------------------------------------------===//
//
// This file contains the Cpu0 implementation of TargetFrameLowering class.
//
//===----------------------------------------------------------------------===//
#include "Cpu0FrameLowering.h"
#include "Cpu0InstrInfo.h"
#include "Cpu0MachineFunction.h"
#include "Cpu0Subtarget.h"
#include "llvm/CodeGen/MachineFrameInfo.h"
#include "llvm/CodeGen/MachineFunction.h"
#include "llvm/CodeGen/MachineInstrBuilder.h"
#include "llvm/CodeGen/MachineModuleInfo.h"
#include "llvm/CodeGen/MachineRegisterInfo.h"
#include "llvm/IR/DataLayout.h"
#include "llvm/IR/Function.h"
#include "llvm/Support/CommandLine.h"
#include "llvm/Target/TargetOptions.h"
using namespace llvm;
//- emitPrologue() and emitEpilogue must exist for main().
//===----------------------------------------------------------------------===//
//
// Stack Frame Processing methods
// +----------------------------+
//
// The stack is allocated decrementing the stack pointer on
// the first instruction of a function prologue. Once decremented,
// all stack references are done thought a positive offset
// from the stack/frame pointer, so the stack is considering
// to grow up! Otherwise terrible hacks would have to be made
// to get this stack ABI compliant :)
//
// The stack frame required by the ABI (after call):
// Offset
//
// 0 ----------
// 4 Args to pass
// . saved $GP (used in PIC)
// . Alloca allocations
// . Local Area
// . CPU "Callee Saved" Registers
// . saved FP
// . saved RA
// . FPU "Callee Saved" Registers
// StackSize -----------
//
// Offset - offset from sp after stack allocation on function prologue
//
// The sp is the stack pointer subtracted/added from the stack size
// at the Prologue/Epilogue
//
// References to the previous stack (to obtain arguments) are done
// with offsets that exceeds the stack size: (stacksize+(4*(num_arg-1))
//
// Examples:
// - reference to the actual stack frame
// for any local area var there is smt like : FI >= 0, StackOffset: 4
// st REGX, 4(SP)
//
// - reference to previous stack frame
// suppose there's a load to the 5th arguments : FI < 0, StackOffset: 16.
// The emitted instruction will be something like:
// ld REGX, 16+StackSize(SP)
//
// Since the total stack size is unknown on LowerFormalArguments, all
// stack references (ObjectOffset) created to reference the function
// arguments, are negative numbers. This way, on eliminateFrameIndex it's
// possible to detect those references and the offsets are adjusted to
// their real location.
//
//===----------------------------------------------------------------------===//
const Cpu0FrameLowering *Cpu0FrameLowering::create(const Cpu0Subtarget &ST) {
return llvm::createCpu0SEFrameLowering(ST);
}
// hasFP - Return true if the specified function should have a dedicated frame
// pointer register. This is true if the function has variable sized allocas,
// if it needs dynamic stack realignment, if frame pointer elimination is
// disabled, or if the frame address is taken.
bool Cpu0FrameLowering::hasFP(const MachineFunction &MF) const {
const MachineFrameInfo &MFI = MF.getFrameInfo();
const TargetRegisterInfo *TRI = STI.getRegisterInfo();
return MF.getTarget().Options.DisableFramePointerElim(MF) ||
MFI.hasVarSizedObjects() || MFI.isFrameAddressTaken() ||
TRI->needsStackRealignment(MF);
}
lbdex/chapters/Chapter3_1/Cpu0SEFrameLowering.h
//===-- Cpu0SEFrameLowering.h - Cpu032/64 frame lowering --------*- C++ -*-===//
//
// The LLVM Compiler Infrastructure
//
// This file is distributed under the University of Illinois Open Source
// License. See LICENSE.TXT for details.
//
//===----------------------------------------------------------------------===//
//
//
//
//===----------------------------------------------------------------------===//
#ifndef LLVM_LIB_TARGET_CPU0_CPU0SEFRAMELOWERING_H
#define LLVM_LIB_TARGET_CPU0_CPU0SEFRAMELOWERING_H
#include "Cpu0Config.h"
#include "Cpu0FrameLowering.h"
namespace llvm {
class Cpu0SEFrameLowering : public Cpu0FrameLowering {
public:
explicit Cpu0SEFrameLowering(const Cpu0Subtarget &STI);
/// emitProlog/emitEpilog - These methods insert prolog and epilog code into
/// the function.
void emitPrologue(MachineFunction &MF, MachineBasicBlock &MBB) const override;
void emitEpilogue(MachineFunction &MF, MachineBasicBlock &MBB) const override;
};
} // End llvm namespace
#endif
lbdex/chapters/Chapter3_1/Cpu0SEFrameLowering.cpp
//===-- Cpu0SEFrameLowering.cpp - Cpu0 Frame Information ------------------===//
//
// The LLVM Compiler Infrastructure
//
// This file is distributed under the University of Illinois Open Source
// License. See LICENSE.TXT for details.
//
//===----------------------------------------------------------------------===//
//
// This file contains the Cpu0 implementation of TargetFrameLowering class.
//
//===----------------------------------------------------------------------===//
#include "Cpu0SEFrameLowering.h"
#include "Cpu0MachineFunction.h"
#include "Cpu0SEInstrInfo.h"
#include "Cpu0Subtarget.h"
#include "llvm/CodeGen/MachineFrameInfo.h"
#include "llvm/CodeGen/MachineFunction.h"
#include "llvm/CodeGen/MachineInstrBuilder.h"
#include "llvm/CodeGen/MachineModuleInfo.h"
#include "llvm/CodeGen/MachineRegisterInfo.h"
#include "llvm/CodeGen/RegisterScavenging.h"
#include "llvm/IR/DataLayout.h"
#include "llvm/IR/Function.h"
#include "llvm/Support/CommandLine.h"
#include "llvm/Target/TargetOptions.h"
using namespace llvm;
Cpu0SEFrameLowering::Cpu0SEFrameLowering(const Cpu0Subtarget &STI)
: Cpu0FrameLowering(STI, STI.stackAlignment()) {}
//@emitPrologue {
void Cpu0SEFrameLowering::emitPrologue(MachineFunction &MF,
MachineBasicBlock &MBB) const {
}
//}
//@emitEpilogue {
void Cpu0SEFrameLowering::emitEpilogue(MachineFunction &MF,
MachineBasicBlock &MBB) const {
}
//}
const Cpu0FrameLowering *
llvm::createCpu0SEFrameLowering(const Cpu0Subtarget &ST) {
return new Cpu0SEFrameLowering(ST);
}
lbdex/chapters/Chapter3_1/Cpu0InstrInfo.h
//===-- Cpu0InstrInfo.h - Cpu0 Instruction Information ----------*- C++ -*-===//
//
// The LLVM Compiler Infrastructure
//
// This file is distributed under the University of Illinois Open Source
// License. See LICENSE.TXT for details.
//
//===----------------------------------------------------------------------===//
//
// This file contains the Cpu0 implementation of the TargetInstrInfo class.
//
//===----------------------------------------------------------------------===//
#ifndef LLVM_LIB_TARGET_CPU0_CPU0INSTRINFO_H
#define LLVM_LIB_TARGET_CPU0_CPU0INSTRINFO_H
#include "Cpu0Config.h"
#include "Cpu0.h"
#include "Cpu0RegisterInfo.h"
#include "llvm/CodeGen/MachineInstrBuilder.h"
#include "llvm/CodeGen/TargetInstrInfo.h"
#define GET_INSTRINFO_HEADER
#include "Cpu0GenInstrInfo.inc"
namespace llvm {
class Cpu0InstrInfo : public Cpu0GenInstrInfo {
virtual void anchor();
protected:
const Cpu0Subtarget &Subtarget;
public:
explicit Cpu0InstrInfo(const Cpu0Subtarget &STI);
static const Cpu0InstrInfo *create(Cpu0Subtarget &STI);
/// getRegisterInfo - TargetInstrInfo is a superset of MRegister info. As
/// such, whenever a client has an instance of instruction info, it should
/// always be able to get register info as well (through this method).
///
virtual const Cpu0RegisterInfo &getRegisterInfo() const = 0;
/// Return the number of bytes of code the specified instruction may be.
unsigned GetInstSizeInBytes(const MachineInstr &MI) const;
protected:
};
const Cpu0InstrInfo *createCpu0SEInstrInfo(const Cpu0Subtarget &STI);
}
#endif
lbdex/chapters/Chapter3_1/Cpu0InstrInfo.cpp
//===-- Cpu0InstrInfo.cpp - Cpu0 Instruction Information ------------------===//
//
// The LLVM Compiler Infrastructure
//
// This file is distributed under the University of Illinois Open Source
// License. See LICENSE.TXT for details.
//
//===----------------------------------------------------------------------===//
//
// This file contains the Cpu0 implementation of the TargetInstrInfo class.
//
//===----------------------------------------------------------------------===//
#include "Cpu0InstrInfo.h"
#include "Cpu0TargetMachine.h"
#include "Cpu0MachineFunction.h"
#include "llvm/ADT/STLExtras.h"
#include "llvm/CodeGen/MachineInstrBuilder.h"
#include "llvm/Support/ErrorHandling.h"
#include "llvm/Support/TargetRegistry.h"
using namespace llvm;
#define GET_INSTRINFO_CTOR_DTOR
#include "Cpu0GenInstrInfo.inc"
// Pin the vtable to this file.
void Cpu0InstrInfo::anchor() {}
//@Cpu0InstrInfo {
Cpu0InstrInfo::Cpu0InstrInfo(const Cpu0Subtarget &STI)
:
Subtarget(STI) {}
const Cpu0InstrInfo *Cpu0InstrInfo::create(Cpu0Subtarget &STI) {
return llvm::createCpu0SEInstrInfo(STI);
}
//@GetInstSizeInBytes {
/// Return the number of bytes of code the specified instruction may be.
unsigned Cpu0InstrInfo::GetInstSizeInBytes(const MachineInstr &MI) const {
//@GetInstSizeInBytes - body
switch (MI.getOpcode()) {
default:
return MI.getDesc().getSize();
}
}
lbdex/chapters/Chapter3_1/Cpu0InstrInfo.td
//===----------------------------------------------------------------------===//
// Cpu0 Instruction Predicate Definitions.
//===----------------------------------------------------------------------===//
def Ch3_1 : Predicate<"Subtarget->hasChapter3_1()">,
AssemblerPredicate<(all_of FeatureChapter3_1)>;
def Ch3_2 : Predicate<"Subtarget->hasChapter3_2()">,
AssemblerPredicate<(all_of FeatureChapter3_2)>;
def Ch3_3 : Predicate<"Subtarget->hasChapter3_3()">,
AssemblerPredicate<(all_of FeatureChapter3_3)>;
def Ch3_4 : Predicate<"Subtarget->hasChapter3_4()">,
AssemblerPredicate<(all_of FeatureChapter3_4)>;
def Ch3_5 : Predicate<"Subtarget->hasChapter3_5()">,
AssemblerPredicate<(all_of FeatureChapter3_5)>;
def Ch4_1 : Predicate<"Subtarget->hasChapter4_1()">,
AssemblerPredicate<(all_of FeatureChapter4_1)>;
def Ch4_2 : Predicate<"Subtarget->hasChapter4_2()">,
AssemblerPredicate<(all_of FeatureChapter4_2)>;
def Ch5_1 : Predicate<"Subtarget->hasChapter5_1()">,
AssemblerPredicate<(all_of FeatureChapter5_1)>;
def Ch6_1 : Predicate<"Subtarget->hasChapter6_1()">,
AssemblerPredicate<(all_of FeatureChapter6_1)>;
def Ch7_1 : Predicate<"Subtarget->hasChapter7_1()">,
AssemblerPredicate<(all_of FeatureChapter7_1)>;
def Ch8_1 : Predicate<"Subtarget->hasChapter8_1()">,
AssemblerPredicate<(all_of FeatureChapter8_1)>;
def Ch8_2 : Predicate<"Subtarget->hasChapter8_2()">,
AssemblerPredicate<(all_of FeatureChapter8_2)>;
def Ch9_1 : Predicate<"Subtarget->hasChapter9_1()">,
AssemblerPredicate<(all_of FeatureChapter9_1)>;
def Ch9_2 : Predicate<"Subtarget->hasChapter9_2()">,
AssemblerPredicate<(all_of FeatureChapter9_2)>;
def Ch9_3 : Predicate<"Subtarget->hasChapter9_3()">,
AssemblerPredicate<(all_of FeatureChapter9_3)>;
def Ch10_1 : Predicate<"Subtarget->hasChapter10_1()">,
AssemblerPredicate<(all_of FeatureChapter10_1)>;
def Ch11_1 : Predicate<"Subtarget->hasChapter11_1()">,
AssemblerPredicate<(all_of FeatureChapter11_1)>;
def Ch11_2 : Predicate<"Subtarget->hasChapter11_2()">,
AssemblerPredicate<(all_of FeatureChapter11_2)>;
def Ch12_1 : Predicate<"Subtarget->hasChapter12_1()">,
AssemblerPredicate<(all_of FeatureChapter12_1)>;
def Ch_all : Predicate<"Subtarget->hasChapterAll()">,
AssemblerPredicate<(all_of FeatureChapterAll)>;
def EnableOverflow : Predicate<"Subtarget->enableOverflow()">;
def DisableOverflow : Predicate<"Subtarget->disableOverflow()">;
def HasCmp : Predicate<"Subtarget->hasCmp()">;
def HasSlt : Predicate<"Subtarget->hasSlt()">;
lbdex/chapters/Chapter3_1/Cpu0ISelLowering.h
//===-- Cpu0ISelLowering.h - Cpu0 DAG Lowering Interface --------*- C++ -*-===//
//
// The LLVM Compiler Infrastructure
//
// This file is distributed under the University of Illinois Open Source
// License. See LICENSE.TXT for details.
//
//===----------------------------------------------------------------------===//
//
// This file defines the interfaces that Cpu0 uses to lower LLVM code into a
// selection DAG.
//
//===----------------------------------------------------------------------===//
#ifndef LLVM_LIB_TARGET_CPU0_CPU0ISELLOWERING_H
#define LLVM_LIB_TARGET_CPU0_CPU0ISELLOWERING_H
#include "Cpu0Config.h"
#include "MCTargetDesc/Cpu0ABIInfo.h"
#include "Cpu0.h"
#include "llvm/CodeGen/CallingConvLower.h"
#include "llvm/CodeGen/SelectionDAG.h"
#include "llvm/IR/Function.h"
#include "llvm/CodeGen/TargetLowering.h"
#include <deque>
namespace llvm {
namespace Cpu0ISD {
enum NodeType {
// Start the numbering from where ISD NodeType finishes.
FIRST_NUMBER = ISD::BUILTIN_OP_END,
// Jump and link (call)
JmpLink,
// Tail call
TailCall,
// Get the Higher 16 bits from a 32-bit immediate
// No relation with Cpu0 Hi register
Hi,
// Get the Lower 16 bits from a 32-bit immediate
// No relation with Cpu0 Lo register
Lo,
// Handle gp_rel (small data/bss sections) relocation.
GPRel,
// Thread Pointer
ThreadPointer,
// Return
Ret,
EH_RETURN,
// DivRem(u)
DivRem,
DivRemU,
Wrapper,
DynAlloc,
Sync
};
}
//===--------------------------------------------------------------------===//
// TargetLowering Implementation
//===--------------------------------------------------------------------===//
class Cpu0FunctionInfo;
class Cpu0Subtarget;
//@class Cpu0TargetLowering
class Cpu0TargetLowering : public TargetLowering {
public:
explicit Cpu0TargetLowering(const Cpu0TargetMachine &TM,
const Cpu0Subtarget &STI);
static const Cpu0TargetLowering *create(const Cpu0TargetMachine &TM,
const Cpu0Subtarget &STI);
/// getTargetNodeName - This method returns the name of a target specific
// DAG node.
const char *getTargetNodeName(unsigned Opcode) const override;
protected:
/// ByValArgInfo - Byval argument information.
struct ByValArgInfo {
unsigned FirstIdx; // Index of the first register used.
unsigned NumRegs; // Number of registers used for this argument.
unsigned Address; // Offset of the stack area used to pass this argument.
ByValArgInfo() : FirstIdx(0), NumRegs(0), Address(0) {}
};
protected:
// Subtarget Info
const Cpu0Subtarget &Subtarget;
// Cache the ABI from the TargetMachine, we use it everywhere.
const Cpu0ABIInfo &ABI;
private:
// Lower Operand specifics
SDValue lowerGlobalAddress(SDValue Op, SelectionDAG &DAG) const;
//- must be exist even without function all
SDValue
LowerFormalArguments(SDValue Chain,
CallingConv::ID CallConv, bool IsVarArg,
const SmallVectorImpl<ISD::InputArg> &Ins,
const SDLoc &dl, SelectionDAG &DAG,
SmallVectorImpl<SDValue> &InVals) const override;
SDValue LowerReturn(SDValue Chain,
CallingConv::ID CallConv, bool IsVarArg,
const SmallVectorImpl<ISD::OutputArg> &Outs,
const SmallVectorImpl<SDValue> &OutVals,
const SDLoc &dl, SelectionDAG &DAG) const override;
};
const Cpu0TargetLowering *
createCpu0SETargetLowering(const Cpu0TargetMachine &TM, const Cpu0Subtarget &STI);
}
#endif // Cpu0ISELLOWERING_H
lbdex/chapters/Chapter3_1/Cpu0ISelLowering.cpp
//===-- Cpu0ISelLowering.cpp - Cpu0 DAG Lowering Implementation -----------===//
//
// The LLVM Compiler Infrastructure
//
// This file is distributed under the University of Illinois Open Source
// License. See LICENSE.TXT for details.
//
//===----------------------------------------------------------------------===//
//
// This file defines the interfaces that Cpu0 uses to lower LLVM code into a
// selection DAG.
//
//===----------------------------------------------------------------------===//
#include "Cpu0ISelLowering.h"
#include "Cpu0MachineFunction.h"
#include "Cpu0TargetMachine.h"
#include "Cpu0TargetObjectFile.h"
#include "Cpu0Subtarget.h"
#include "llvm/ADT/Statistic.h"
#include "llvm/CodeGen/CallingConvLower.h"
#include "llvm/CodeGen/MachineFrameInfo.h"
#include "llvm/CodeGen/MachineFunction.h"
#include "llvm/CodeGen/MachineInstrBuilder.h"
#include "llvm/CodeGen/MachineRegisterInfo.h"
#include "llvm/CodeGen/SelectionDAG.h"
#include "llvm/CodeGen/ValueTypes.h"
#include "llvm/IR/CallingConv.h"
#include "llvm/IR/DerivedTypes.h"
#include "llvm/IR/GlobalVariable.h"
#include "llvm/Support/CommandLine.h"
#include "llvm/Support/Debug.h"
#include "llvm/Support/ErrorHandling.h"
#include "llvm/Support/raw_ostream.h"
using namespace llvm;
#define DEBUG_TYPE "cpu0-lower"
//@3_1 1 {
const char *Cpu0TargetLowering::getTargetNodeName(unsigned Opcode) const {
switch (Opcode) {
case Cpu0ISD::JmpLink: return "Cpu0ISD::JmpLink";
case Cpu0ISD::TailCall: return "Cpu0ISD::TailCall";
case Cpu0ISD::Hi: return "Cpu0ISD::Hi";
case Cpu0ISD::Lo: return "Cpu0ISD::Lo";
case Cpu0ISD::GPRel: return "Cpu0ISD::GPRel";
case Cpu0ISD::Ret: return "Cpu0ISD::Ret";
case Cpu0ISD::EH_RETURN: return "Cpu0ISD::EH_RETURN";
case Cpu0ISD::DivRem: return "Cpu0ISD::DivRem";
case Cpu0ISD::DivRemU: return "Cpu0ISD::DivRemU";
case Cpu0ISD::Wrapper: return "Cpu0ISD::Wrapper";
default: return NULL;
}
}
//@3_1 1 }
//@Cpu0TargetLowering {
Cpu0TargetLowering::Cpu0TargetLowering(const Cpu0TargetMachine &TM,
const Cpu0Subtarget &STI)
: TargetLowering(TM), Subtarget(STI), ABI(TM.getABI()) {
}
const Cpu0TargetLowering *Cpu0TargetLowering::create(const Cpu0TargetMachine &TM,
const Cpu0Subtarget &STI) {
return llvm::createCpu0SETargetLowering(TM, STI);
}
//===----------------------------------------------------------------------===//
// Lower helper functions
//===----------------------------------------------------------------------===//
//===----------------------------------------------------------------------===//
// Misc Lower Operation implementation
//===----------------------------------------------------------------------===//
#include "Cpu0GenCallingConv.inc"
//===----------------------------------------------------------------------===//
//@ Formal Arguments Calling Convention Implementation
//===----------------------------------------------------------------------===//
//@LowerFormalArguments {
/// LowerFormalArguments - transform physical registers into virtual registers
/// and generate load operations for arguments places on the stack.
SDValue
Cpu0TargetLowering::LowerFormalArguments(SDValue Chain,
CallingConv::ID CallConv,
bool IsVarArg,
const SmallVectorImpl<ISD::InputArg> &Ins,
const SDLoc &DL, SelectionDAG &DAG,
SmallVectorImpl<SDValue> &InVals)
const {
return Chain;
}
// @LowerFormalArguments }
//===----------------------------------------------------------------------===//
//@ Return Value Calling Convention Implementation
//===----------------------------------------------------------------------===//
SDValue
Cpu0TargetLowering::LowerReturn(SDValue Chain,
CallingConv::ID CallConv, bool IsVarArg,
const SmallVectorImpl<ISD::OutputArg> &Outs,
const SmallVectorImpl<SDValue> &OutVals,
const SDLoc &DL, SelectionDAG &DAG) const {
return DAG.getNode(Cpu0ISD::Ret, DL, MVT::Other,
Chain, DAG.getRegister(Cpu0::LR, MVT::i32));
}
lbdex/chapters/Chapter3_1/Cpu0SEISelLowering.h
//===-- Cpu0ISEISelLowering.h - Cpu0ISE DAG Lowering Interface ----*- C++ -*-===//
//
// The LLVM Compiler Infrastructure
//
// This file is distributed under the University of Illinois Open Source
// License. See LICENSE.TXT for details.
//
//===----------------------------------------------------------------------===//
//
// Subclass of Cpu0ITargetLowering specialized for cpu032/64.
//
//===----------------------------------------------------------------------===//
#ifndef LLVM_LIB_TARGET_CPU0_CPU0SEISELLOWERING_H
#define LLVM_LIB_TARGET_CPU0_CPU0SEISELLOWERING_H
#include "Cpu0Config.h"
#include "Cpu0ISelLowering.h"
#include "Cpu0RegisterInfo.h"
namespace llvm {
class Cpu0SETargetLowering : public Cpu0TargetLowering {
public:
explicit Cpu0SETargetLowering(const Cpu0TargetMachine &TM,
const Cpu0Subtarget &STI);
SDValue LowerOperation(SDValue Op, SelectionDAG &DAG) const override;
private:
};
}
#endif // Cpu0ISEISELLOWERING_H
lbdex/chapters/Chapter3_1/Cpu0SEISelLowering.cpp
//===-- Cpu0SEISelLowering.cpp - Cpu0SE DAG Lowering Interface --*- C++ -*-===//
//
// The LLVM Compiler Infrastructure
//
// This file is distributed under the University of Illinois Open Source
// License. See LICENSE.TXT for details.
//
//===----------------------------------------------------------------------===//
//
// Subclass of Cpu0TargetLowering specialized for cpu032.
//
//===----------------------------------------------------------------------===//
#include "Cpu0MachineFunction.h"
#include "Cpu0SEISelLowering.h"
#include "Cpu0RegisterInfo.h"
#include "Cpu0TargetMachine.h"
#include "llvm/CodeGen/MachineInstrBuilder.h"
#include "llvm/CodeGen/MachineRegisterInfo.h"
#include "llvm/CodeGen/TargetInstrInfo.h"
#include "llvm/IR/Intrinsics.h"
#include "llvm/Support/CommandLine.h"
#include "llvm/Support/Debug.h"
#include "llvm/Support/raw_ostream.h"
using namespace llvm;
#define DEBUG_TYPE "cpu0-isel"
static cl::opt<bool>
EnableCpu0TailCalls("enable-cpu0-tail-calls", cl::Hidden,
cl::desc("CPU0: Enable tail calls."), cl::init(false));
//@Cpu0SETargetLowering {
Cpu0SETargetLowering::Cpu0SETargetLowering(const Cpu0TargetMachine &TM,
const Cpu0Subtarget &STI)
: Cpu0TargetLowering(TM, STI) {
//@Cpu0SETargetLowering body {
// Set up the register classes
addRegisterClass(MVT::i32, &Cpu0::CPURegsRegClass);
// must, computeRegisterProperties - Once all of the register classes are
// added, this allows us to compute derived properties we expose.
computeRegisterProperties(Subtarget.getRegisterInfo());
}
SDValue Cpu0SETargetLowering::LowerOperation(SDValue Op,
SelectionDAG &DAG) const {
return Cpu0TargetLowering::LowerOperation(Op, DAG);
}
const Cpu0TargetLowering *
llvm::createCpu0SETargetLowering(const Cpu0TargetMachine &TM,
const Cpu0Subtarget &STI) {
return new Cpu0SETargetLowering(TM, STI);
}
lbdex/chapters/Chapter3_1/Cpu0MachineFunction.h
//===-- Cpu0MachineFunctionInfo.h - Private data used for Cpu0 ----*- C++ -*-=//
//
// The LLVM Compiler Infrastructure
//
// This file is distributed under the University of Illinois Open Source
// License. See LICENSE.TXT for details.
//
//===----------------------------------------------------------------------===//
//
// This file declares the Cpu0 specific subclass of MachineFunctionInfo.
//
//===----------------------------------------------------------------------===//
#ifndef LLVM_LIB_TARGET_CPU0_CPU0MACHINEFUNCTION_H
#define LLVM_LIB_TARGET_CPU0_CPU0MACHINEFUNCTION_H
#include "Cpu0Config.h"
#include "llvm/CodeGen/MachineFrameInfo.h"
#include "llvm/CodeGen/MachineFunction.h"
#include "llvm/CodeGen/MachineMemOperand.h"
#include "llvm/CodeGen/PseudoSourceValue.h"
#include "llvm/Target/TargetMachine.h"
#include <map>
namespace llvm {
//@1 {
/// Cpu0FunctionInfo - This class is derived from MachineFunction private
/// Cpu0 target-specific information for each MachineFunction.
class Cpu0FunctionInfo : public MachineFunctionInfo {
public:
Cpu0FunctionInfo(MachineFunction& MF)
: MF(MF),
VarArgsFrameIndex(0),
MaxCallFrameSize(0)
{}
~Cpu0FunctionInfo();
int getVarArgsFrameIndex() const { return VarArgsFrameIndex; }
void setVarArgsFrameIndex(int Index) { VarArgsFrameIndex = Index; }
private:
virtual void anchor();
MachineFunction& MF;
/// VarArgsFrameIndex - FrameIndex for start of varargs area.
int VarArgsFrameIndex;
unsigned MaxCallFrameSize;
};
//@1 }
} // end of namespace llvm
#endif // CPU0_MACHINE_FUNCTION_INFO_H
lbdex/chapters/Chapter3_1/Cpu0MachineFunction.cpp
//===-- Cpu0MachineFunctionInfo.cpp - Private data used for Cpu0 ----------===//
//
// The LLVM Compiler Infrastructure
//
// This file is distributed under the University of Illinois Open Source
// License. See LICENSE.TXT for details.
//
//===----------------------------------------------------------------------===//
#include "Cpu0MachineFunction.h"
#include "Cpu0InstrInfo.h"
#include "Cpu0Subtarget.h"
#include "llvm/IR/Function.h"
#include "llvm/CodeGen/MachineInstrBuilder.h"
#include "llvm/CodeGen/MachineRegisterInfo.h"
using namespace llvm;
bool FixGlobalBaseReg;
Cpu0FunctionInfo::~Cpu0FunctionInfo() {}
void Cpu0FunctionInfo::anchor() { }
lbdex/chapters/Chapter3_1/MCTargetDesc/Cpu0ABIInfo.h
//===---- Cpu0ABIInfo.h - Information about CPU0 ABI's --------------------===//
//
// The LLVM Compiler Infrastructure
//
// This file is distributed under the University of Illinois Open Source
// License. See LICENSE.TXT for details.
//
//===----------------------------------------------------------------------===//
#ifndef LLVM_LIB_TARGET_CPU0_MCTARGETDESC_CPU0ABIINFO_H
#define LLVM_LIB_TARGET_CPU0_MCTARGETDESC_CPU0ABIINFO_H
#include "Cpu0Config.h"
#include "llvm/ADT/ArrayRef.h"
#include "llvm/ADT/Triple.h"
#include "llvm/IR/CallingConv.h"
#include "llvm/MC/MCRegisterInfo.h"
namespace llvm {
class MCTargetOptions;
class StringRef;
class TargetRegisterClass;
class Cpu0ABIInfo {
public:
enum class ABI { Unknown, O32, S32 };
protected:
ABI ThisABI;
public:
Cpu0ABIInfo(ABI ThisABI) : ThisABI(ThisABI) {}
static Cpu0ABIInfo Unknown() { return Cpu0ABIInfo(ABI::Unknown); }
static Cpu0ABIInfo O32() { return Cpu0ABIInfo(ABI::O32); }
static Cpu0ABIInfo S32() { return Cpu0ABIInfo(ABI::S32); }
static Cpu0ABIInfo computeTargetABI();
bool IsKnown() const { return ThisABI != ABI::Unknown; }
bool IsO32() const { return ThisABI == ABI::O32; }
bool IsS32() const { return ThisABI == ABI::S32; }
ABI GetEnumValue() const { return ThisABI; }
/// The registers to use for byval arguments.
const ArrayRef<MCPhysReg> GetByValArgRegs() const;
/// The registers to use for the variable argument list.
const ArrayRef<MCPhysReg> GetVarArgRegs() const;
/// Obtain the size of the area allocated by the callee for arguments.
/// CallingConv::FastCall affects the value for O32.
unsigned GetCalleeAllocdArgSizeInBytes(CallingConv::ID CC) const;
/// Ordering of ABI's
/// Cpu0GenSubtargetInfo.inc will use this to resolve conflicts when given
/// multiple ABI options.
bool operator<(const Cpu0ABIInfo Other) const {
return ThisABI < Other.GetEnumValue();
}
unsigned GetStackPtr() const;
unsigned GetFramePtr() const;
unsigned GetNullPtr() const;
unsigned GetEhDataReg(unsigned I) const;
int EhDataRegSize() const;
};
}
#endif
lbdex/chapters/Chapter3_1/MCTargetDesc/Cpu0ABIInfo.cpp
//===---- Cpu0ABIInfo.cpp - Information about CPU0 ABI's ------------------===//
//
// The LLVM Compiler Infrastructure
//
// This file is distributed under the University of Illinois Open Source
// License. See LICENSE.TXT for details.
//
//===----------------------------------------------------------------------===//
#include "Cpu0Config.h"
#include "Cpu0ABIInfo.h"
#include "Cpu0RegisterInfo.h"
#include "llvm/ADT/StringRef.h"
#include "llvm/ADT/StringSwitch.h"
#include "llvm/MC/MCTargetOptions.h"
#include "llvm/Support/CommandLine.h"
using namespace llvm;
static cl::opt<bool>
EnableCpu0S32Calls("cpu0-s32-calls", cl::Hidden,
cl::desc("CPU0 S32 call: use stack only to pass arguments.\
"), cl::init(false));
namespace {
static const MCPhysReg O32IntRegs[4] = {Cpu0::A0, Cpu0::A1};
static const MCPhysReg S32IntRegs = {};
}
const ArrayRef<MCPhysReg> Cpu0ABIInfo::GetByValArgRegs() const {
if (IsO32())
return makeArrayRef(O32IntRegs);
if (IsS32())
return makeArrayRef(S32IntRegs);
llvm_unreachable("Unhandled ABI");
}
const ArrayRef<MCPhysReg> Cpu0ABIInfo::GetVarArgRegs() const {
if (IsO32())
return makeArrayRef(O32IntRegs);
if (IsS32())
return makeArrayRef(S32IntRegs);
llvm_unreachable("Unhandled ABI");
}
unsigned Cpu0ABIInfo::GetCalleeAllocdArgSizeInBytes(CallingConv::ID CC) const {
if (IsO32())
return CC != 0;
if (IsS32())
return 0;
llvm_unreachable("Unhandled ABI");
}
Cpu0ABIInfo Cpu0ABIInfo::computeTargetABI() {
Cpu0ABIInfo abi(ABI::Unknown);
if (EnableCpu0S32Calls)
abi = ABI::S32;
else
abi = ABI::O32;
// Assert exactly one ABI was chosen.
assert(abi.ThisABI != ABI::Unknown);
return abi;
}
unsigned Cpu0ABIInfo::GetStackPtr() const {
return Cpu0::SP;
}
unsigned Cpu0ABIInfo::GetFramePtr() const {
return Cpu0::FP;
}
unsigned Cpu0ABIInfo::GetNullPtr() const {
return Cpu0::ZERO;
}
unsigned Cpu0ABIInfo::GetEhDataReg(unsigned I) const {
static const unsigned EhDataReg[] = {
Cpu0::A0, Cpu0::A1
};
return EhDataReg[I];
}
int Cpu0ABIInfo::EhDataRegSize() const {
if (ThisABI == ABI::S32)
return 0;
else
return 2;
}
lbdex/chapters/Chapter3_1/Cpu0Subtarget.h
#include "Cpu0FrameLowering.h"
#include "Cpu0ISelLowering.h"
#include "Cpu0InstrInfo.h"
#include "llvm/CodeGen/SelectionDAGTargetInfo.h"
#include "llvm/CodeGen/TargetSubtargetInfo.h"
#include "llvm/IR/DataLayout.h"
#include "llvm/MC/MCInstrItineraries.h"
#include <string>
#define GET_SUBTARGETINFO_HEADER
#include "Cpu0GenSubtargetInfo.inc"
namespace llvm {
class StringRef;
class Cpu0TargetMachine;
class Cpu0Subtarget : public Cpu0GenSubtargetInfo {
virtual void anchor();
public:
bool HasChapterDummy;
bool HasChapterAll;
bool hasChapter3_1() const {
#if CH >= CH3_1
return true;
#else
return false;
#endif
}
bool hasChapter3_2() const {
#if CH >= CH3_2
return true;
#else
return false;
#endif
}
bool hasChapter3_3() const {
#if CH >= CH3_3
return true;
#else
return false;
#endif
}
bool hasChapter3_4() const {
#if CH >= CH3_4
return true;
#else
return false;
#endif
}
bool hasChapter3_5() const {
#if CH >= CH3_5
return true;
#else
return false;
#endif
}
bool hasChapter4_1() const {
#if CH >= CH4_1
return true;
#else
return false;
#endif
}
bool hasChapter4_2() const {
#if CH >= CH4_2
return true;
#else
return false;
#endif
}
bool hasChapter5_1() const {
#if CH >= CH5_1
return true;
#else
return false;
#endif
}
bool hasChapter6_1() const {
#if CH >= CH6_1
return true;
#else
return false;
#endif
}
bool hasChapter7_1() const {
#if CH >= CH7_1
return true;
#else
return false;
#endif
}
bool hasChapter8_1() const {
#if CH >= CH8_1
return true;
#else
return false;
#endif
}
bool hasChapter8_2() const {
#if CH >= CH8_2
return true;
#else
return false;
#endif
}
bool hasChapter9_1() const {
#if CH >= CH9_1
return true;
#else
return false;
#endif
}
bool hasChapter9_2() const {
#if CH >= CH9_2
return true;
#else
return false;
#endif
}
bool hasChapter9_3() const {
#if CH >= CH9_3
return true;
#else
return false;
#endif
}
bool hasChapter10_1() const {
#if CH >= CH10_1
return true;
#else
return false;
#endif
}
bool hasChapter11_1() const {
#if CH >= CH11_1
return true;
#else
return false;
#endif
}
bool hasChapter11_2() const {
#if CH >= CH11_2
return true;
#else
return false;
#endif
}
bool hasChapter12_1() const {
#if CH >= CH12_1
return true;
#else
return false;
#endif
}
protected:
enum Cpu0ArchEnum {
Cpu032I,
Cpu032II
};
// Cpu0 architecture version
Cpu0ArchEnum Cpu0ArchVersion;
// IsLittle - The target is Little Endian
bool IsLittle;
bool EnableOverflow;
// HasCmp - cmp instructions.
bool HasCmp;
// HasSlt - slt instructions.
bool HasSlt;
InstrItineraryData InstrItins;
const Cpu0TargetMachine &TM;
Triple TargetTriple;
const SelectionDAGTargetInfo TSInfo;
std::unique_ptr<const Cpu0InstrInfo> InstrInfo;
std::unique_ptr<const Cpu0FrameLowering> FrameLowering;
std::unique_ptr<const Cpu0TargetLowering> TLInfo;
public:
bool isPositionIndependent() const;
const Cpu0ABIInfo &getABI() const;
/// This constructor initializes the data members to match that
/// of the specified triple.
Cpu0Subtarget(const Triple &TT, StringRef CPU, StringRef FS,
bool little, const Cpu0TargetMachine &_TM);
//- Vitual function, must have
/// ParseSubtargetFeatures - Parses features string setting specified
/// subtarget options. Definition of function is auto generated by tblgen.
void ParseSubtargetFeatures(StringRef CPU, StringRef TuneCPU, StringRef FS);
bool isLittle() const { return IsLittle; }
bool hasCpu032I() const { return Cpu0ArchVersion >= Cpu032I; }
bool isCpu032I() const { return Cpu0ArchVersion == Cpu032I; }
bool hasCpu032II() const { return Cpu0ArchVersion >= Cpu032II; }
bool isCpu032II() const { return Cpu0ArchVersion == Cpu032II; }
/// Features related to the presence of specific instructions.
bool enableOverflow() const { return EnableOverflow; }
bool disableOverflow() const { return !EnableOverflow; }
bool hasCmp() const { return HasCmp; }
bool hasSlt() const { return HasSlt; }
bool abiUsesSoftFloat() const;
bool enableLongBranchPass() const {
return hasCpu032II();
}
unsigned stackAlignment() const { return 8; }
Cpu0Subtarget &initializeSubtargetDependencies(StringRef CPU, StringRef FS,
const TargetMachine &TM);
const SelectionDAGTargetInfo *getSelectionDAGInfo() const override {
return &TSInfo;
}
const Cpu0InstrInfo *getInstrInfo() const override { return InstrInfo.get(); }
const TargetFrameLowering *getFrameLowering() const override {
return FrameLowering.get();
}
const Cpu0RegisterInfo *getRegisterInfo() const override {
return &InstrInfo->getRegisterInfo();
}
const Cpu0TargetLowering *getTargetLowering() const override {
return TLInfo.get();
}
const InstrItineraryData *getInstrItineraryData() const override {
return &InstrItins;
}
};
} // End llvm namespace
#endif
lbdex/chapters/Chapter3_1/Cpu0Subtarget.cpp
//===-- Cpu0Subtarget.cpp - Cpu0 Subtarget Information --------------------===//
//
// The LLVM Compiler Infrastructure
//
// This file is distributed under the University of Illinois Open Source
// License. See LICENSE.TXT for details.
//
//===----------------------------------------------------------------------===//
//
// This file implements the Cpu0 specific subclass of TargetSubtargetInfo.
//
//===----------------------------------------------------------------------===//
#include "Cpu0Subtarget.h"
#include "Cpu0MachineFunction.h"
#include "Cpu0.h"
#include "Cpu0RegisterInfo.h"
#include "Cpu0TargetMachine.h"
#include "llvm/IR/Attributes.h"
#include "llvm/IR/Function.h"
#include "llvm/Support/CommandLine.h"
#include "llvm/Support/ErrorHandling.h"
#include "llvm/Support/TargetRegistry.h"
using namespace llvm;
#define DEBUG_TYPE "cpu0-subtarget"
#define GET_SUBTARGETINFO_TARGET_DESC
#define GET_SUBTARGETINFO_CTOR
#include "Cpu0GenSubtargetInfo.inc"
extern bool FixGlobalBaseReg;
void Cpu0Subtarget::anchor() { }
//@1 {
Cpu0Subtarget::Cpu0Subtarget(const Triple &TT, StringRef CPU,
StringRef FS, bool little,
const Cpu0TargetMachine &_TM) :
//@1 }
// Cpu0GenSubtargetInfo will display features by llc -march=cpu0 -mcpu=help
Cpu0GenSubtargetInfo(TT, CPU, /*TuneCPU*/ CPU, FS),
IsLittle(little), TM(_TM), TargetTriple(TT), TSInfo(),
InstrInfo(
Cpu0InstrInfo::create(initializeSubtargetDependencies(CPU, FS, TM))),
FrameLowering(Cpu0FrameLowering::create(*this)),
TLInfo(Cpu0TargetLowering::create(TM, *this)) {
}
bool Cpu0Subtarget::isPositionIndependent() const {
return TM.isPositionIndependent();
}
Cpu0Subtarget &
Cpu0Subtarget::initializeSubtargetDependencies(StringRef CPU, StringRef FS,
const TargetMachine &TM) {
if (TargetTriple.getArch() == Triple::cpu0 || TargetTriple.getArch() == Triple::cpu0el) {
if (CPU.empty() || CPU == "generic") {
CPU = "cpu032II";
}
else if (CPU == "help") {
CPU = "";
return *this;
}
else if (CPU != "cpu032I" && CPU != "cpu032II") {
CPU = "cpu032II";
}
}
else {
errs() << "!!!Error, TargetTriple.getArch() = " << TargetTriple.getArch()
<< "CPU = " << CPU << "\n";
exit(0);
}
if (CPU == "cpu032I")
Cpu0ArchVersion = Cpu032I;
else if (CPU == "cpu032II")
Cpu0ArchVersion = Cpu032II;
if (isCpu032I()) {
HasCmp = true;
HasSlt = false;
}
else if (isCpu032II()) {
HasCmp = false;
HasSlt = true;
}
else {
errs() << "-mcpu must be empty(default:cpu032II), cpu032I or cpu032II" << "\n";
}
// Parse features string.
ParseSubtargetFeatures(CPU, /*TuneCPU*/ CPU, FS);
// Initialize scheduling itinerary for the specified CPU.
InstrItins = getInstrItineraryForCPU(CPU);
return *this;
}
bool Cpu0Subtarget::abiUsesSoftFloat() const {
// return TM->Options.UseSoftFloat;
return true;
}
const Cpu0ABIInfo &Cpu0Subtarget::getABI() const { return TM.getABI(); }
lbdex/chapters/Chapter3_1/Cpu0RegisterInfo.h
//===-- Cpu0RegisterInfo.h - Cpu0 Register Information Impl -----*- C++ -*-===//
//
// The LLVM Compiler Infrastructure
//
// This file is distributed under the University of Illinois Open Source
// License. See LICENSE.TXT for details.
//
//===----------------------------------------------------------------------===//
//
// This file contains the Cpu0 implementation of the TargetRegisterInfo class.
//
//===----------------------------------------------------------------------===//
#ifndef LLVM_LIB_TARGET_CPU0_CPU0REGISTERINFO_H
#define LLVM_LIB_TARGET_CPU0_CPU0REGISTERINFO_H
#include "Cpu0Config.h"
#include "Cpu0.h"
#include "llvm/CodeGen/TargetRegisterInfo.h"
#define GET_REGINFO_HEADER
#include "Cpu0GenRegisterInfo.inc"
namespace llvm {
class Cpu0Subtarget;
class TargetInstrInfo;
class Type;
class Cpu0RegisterInfo : public Cpu0GenRegisterInfo {
protected:
const Cpu0Subtarget &Subtarget;
public:
Cpu0RegisterInfo(const Cpu0Subtarget &Subtarget);
const MCPhysReg *getCalleeSavedRegs(const MachineFunction *MF) const override;
const uint32_t *getCallPreservedMask(const MachineFunction &MF,
CallingConv::ID) const override;
BitVector getReservedRegs(const MachineFunction &MF) const override;
bool requiresRegisterScavenging(const MachineFunction &MF) const override;
bool trackLivenessAfterRegAlloc(const MachineFunction &MF) const override;
/// Stack Frame Processing Methods
void eliminateFrameIndex(MachineBasicBlock::iterator II,
int SPAdj, unsigned FIOperandNum,
RegScavenger *RS = nullptr) const override;
/// Debug information queries.
Register getFrameRegister(const MachineFunction &MF) const override;
/// \brief Return GPR register class.
virtual const TargetRegisterClass *intRegClass(unsigned Size) const = 0;
};
} // end namespace llvm
#endif
lbdex/chapters/Chapter3_1/Cpu0RegisterInfo.cpp
//===-- Cpu0RegisterInfo.cpp - CPU0 Register Information -== --------------===//
//
// The LLVM Compiler Infrastructure
//
// This file is distributed under the University of Illinois Open Source
// License. See LICENSE.TXT for details.
//
//===----------------------------------------------------------------------===//
//
// This file contains the CPU0 implementation of the TargetRegisterInfo class.
//
//===----------------------------------------------------------------------===//
#define DEBUG_TYPE "cpu0-reg-info"
#include "Cpu0RegisterInfo.h"
#include "Cpu0.h"
#include "Cpu0Subtarget.h"
#include "Cpu0MachineFunction.h"
#include "llvm/IR/Function.h"
#include "llvm/IR/Type.h"
#include "llvm/Support/CommandLine.h"
#include "llvm/Support/Debug.h"
#include "llvm/Support/ErrorHandling.h"
#include "llvm/Support/raw_ostream.h"
#define GET_REGINFO_TARGET_DESC
#include "Cpu0GenRegisterInfo.inc"
using namespace llvm;
Cpu0RegisterInfo::Cpu0RegisterInfo(const Cpu0Subtarget &ST)
: Cpu0GenRegisterInfo(Cpu0::LR), Subtarget(ST) {}
//===----------------------------------------------------------------------===//
// Callee Saved Registers methods
//===----------------------------------------------------------------------===//
/// Cpu0 Callee Saved Registers
// In Cpu0CallConv.td,
// def CSR_O32 : CalleeSavedRegs<(add LR, FP,
// (sequence "S%u", 2, 0))>;
// llc create CSR_O32_SaveList and CSR_O32_RegMask from above defined.
const MCPhysReg *
Cpu0RegisterInfo::getCalleeSavedRegs(const MachineFunction *MF) const {
return CSR_O32_SaveList;
}
const uint32_t *
Cpu0RegisterInfo::getCallPreservedMask(const MachineFunction &MF,
CallingConv::ID) const {
return CSR_O32_RegMask;
}
// pure virtual method
//@getReservedRegs {
BitVector Cpu0RegisterInfo::
getReservedRegs(const MachineFunction &MF) const {
//@getReservedRegs body {
static const uint16_t ReservedCPURegs[] = {
Cpu0::ZERO, Cpu0::AT, Cpu0::SP, Cpu0::LR, /*Cpu0::SW, */Cpu0::PC
};
BitVector Reserved(getNumRegs());
for (unsigned I = 0; I < array_lengthof(ReservedCPURegs); ++I)
Reserved.set(ReservedCPURegs[I]);
return Reserved;
}
//@eliminateFrameIndex {
//- If no eliminateFrameIndex(), it will hang on run.
// pure virtual method
// FrameIndex represent objects inside a abstract stack.
// We must replace FrameIndex with an stack/frame pointer
// direct reference.
void Cpu0RegisterInfo::
eliminateFrameIndex(MachineBasicBlock::iterator II, int SPAdj,
unsigned FIOperandNum, RegScavenger *RS) const {
}
//}
bool
Cpu0RegisterInfo::requiresRegisterScavenging(const MachineFunction &MF) const {
return true;
}
bool
Cpu0RegisterInfo::trackLivenessAfterRegAlloc(const MachineFunction &MF) const {
return true;
}
// pure virtual method
Register Cpu0RegisterInfo::
getFrameRegister(const MachineFunction &MF) const {
const TargetFrameLowering *TFI = MF.getSubtarget().getFrameLowering();
return TFI->hasFP(MF) ? (Cpu0::FP) :
(Cpu0::SP);
}
lbdex/chapters/Chapter3_1/Cpu0SERegisterInfo.h
//===-- Cpu0SERegisterInfo.h - Cpu032 Register Information ------*- C++ -*-===//
//
// The LLVM Compiler Infrastructure
//
// This file is distributed under the University of Illinois Open Source
// License. See LICENSE.TXT for details.
//
//===----------------------------------------------------------------------===//
//
// This file contains the Cpu032/64 implementation of the TargetRegisterInfo
// class.
//
//===----------------------------------------------------------------------===//
#ifndef LLVM_LIB_TARGET_CPU0_CPU0SEREGISTERINFO_H
#define LLVM_LIB_TARGET_CPU0_CPU0SEREGISTERINFO_H
#include "Cpu0Config.h"
#include "Cpu0RegisterInfo.h"
namespace llvm {
class Cpu0SEInstrInfo;
class Cpu0SERegisterInfo : public Cpu0RegisterInfo {
public:
Cpu0SERegisterInfo(const Cpu0Subtarget &Subtarget);
const TargetRegisterClass *intRegClass(unsigned Size) const override;
};
} // end namespace llvm
#endif
lbdex/chapters/Chapter3_1/Cpu0SERegisterInfo.cpp
//===-- Cpu0SERegisterInfo.cpp - CPU0 Register Information ------== -------===//
//
// The LLVM Compiler Infrastructure
//
// This file is distributed under the University of Illinois Open Source
// License. See LICENSE.TXT for details.
//
//===----------------------------------------------------------------------===//
//
// This file contains the CPU0 implementation of the TargetRegisterInfo
// class.
//
//===----------------------------------------------------------------------===//
#include "Cpu0SERegisterInfo.h"
using namespace llvm;
#define DEBUG_TYPE "cpu0-reg-info"
Cpu0SERegisterInfo::Cpu0SERegisterInfo(const Cpu0Subtarget &ST)
: Cpu0RegisterInfo(ST) {}
const TargetRegisterClass *
Cpu0SERegisterInfo::intRegClass(unsigned Size) const {
return &Cpu0::CPURegsRegClass;
}
build/lib/Target/Cpu0/Cpu0GenInstInfo.inc
//- Cpu0GenInstInfo.inc which generate from Cpu0InstrInfo.td
#ifdef GET_INSTRINFO_HEADER
#undef GET_INSTRINFO_HEADER
namespace llvm {
struct Cpu0GenInstrInfo : public TargetInstrInfoImpl {
explicit Cpu0GenInstrInfo(int SO = -1, int DO = -1);
};
} // End llvm namespace
#endif // GET_INSTRINFO_HEADER
#define GET_INSTRINFO_HEADER
#include "Cpu0GenInstrInfo.inc"
//- Cpu0InstInfo.h
class Cpu0InstrInfo : public Cpu0GenInstrInfo {
Cpu0TargetMachine &TM;
public:
explicit Cpu0InstrInfo(Cpu0TargetMachine &TM);
};

Fig. 20 Cpu0 backend class access link¶
Chapter3_1 adds most of the Cpu0 backend classes. The code in Chapter3_1 can be summarized in Fig. 20.
The Cpu0Subtarget class provides interfaces such as getInstrInfo(), getFrameLowering(), etc., to access other Cpu0 classes. Most classes (like Cpu0InstrInfo, Cpu0RegisterInfo, etc.) contain a Subtarget reference member, allowing them to access other classes through the Cpu0Subtarget interface.
If a backend module does not have a Subtarget reference, these classes can still access the Subtarget class through Cpu0TargetMachine (typically referred to as TM) using:
static_cast<Cpu0TargetMachine &>(TM).getSubtargetImpl()
Once the Subtarget class is obtained, the backend code can access other classes through it.
For classes named Cpu0SExx, they represent the standard 32-bit class. This naming convention follows the LLVM 3.5 Mips backend style. The Mips backend uses Mips16, MipsSE, and Mips64 file/class names to define classes for 16-bit, 32-bit, and 64-bit architectures, respectively.
Since Cpu0Subtarget creates Cpu0InstrInfo, Cpu0RegisterInfo, etc., in its constructor, it can provide class references through the interfaces shown in Fig. 20.
Fig. 21 below illustrates the Cpu0 TableGen inheritance relationship.
In the previous chapter, we mentioned that backend classes can include TableGen-generated classes and inherit from them. All TableGen-generated classes for the Cpu0 backend are located in:
build/lib/Target/Cpu0/*.inc
Through C++ inheritance, TableGen provides backend developers with a flexible way to utilize its generated code. Developers also have the opportunity to override functions if needed.

Fig. 21 Cpu0 classes inherited from TableGen-generated files¶
Since LLVM has a deep inheritance tree, it is not fully explored here. Benefiting from the inheritance tree structure, minimal code needs to be implemented in instruction, frame/stack, and DAG selection classes, as much of the functionality is already provided by their parent classes.
The llvm-tblgen tool generates Cpu0GenInstrInfo.inc based on the information in Cpu0InstrInfo.td.
Cpu0InstrInfo.h extracts the necessary code from Cpu0GenInstrInfo.inc by defining:
#define GET_INSTRINFO_HEADER
With TableGen, the backend code size is further reduced through the pattern matching theory of compiler development. This is explained in the “DAG” and “Instruction Selection” sections of the previous chapter.
The following is a code fragment from Cpu0GenInstrInfo.inc. Code between #ifdef GET_INSTRINFO_HEADER and #endif // GET_INSTRINFO_HEADER is extracted into Cpu0InstrInfo.h.
build/lib/Target/Cpu0/Cpu0GenInstInfo.inc
//- Cpu0GenInstInfo.inc which generate from Cpu0InstrInfo.td
#ifdef GET_INSTRINFO_HEADER
#undef GET_INSTRINFO_HEADER
namespace llvm {
struct Cpu0GenInstrInfo : public TargetInstrInfoImpl {
explicit Cpu0GenInstrInfo(int SO = -1, int DO = -1);
};
} // End llvm namespace
#endif // GET_INSTRINFO_HEADER
Reference web sites are here [1] [2].
Chapter3_1/CMakeLists.txt is modified with these new added *.cpp as follows,
lbdex/chapters/Chapter3_1/CMakeLists.txt
tablegen(LLVM Cpu0GenDAGISel.inc -gen-dag-isel)
tablegen(LLVM Cpu0GenCallingConv.inc -gen-callingconv)
Cpu0FrameLowering.cpp
Please take a look for Chapter3_1 code. After that, building Chapter3_1 by “#define CH CH3_1” in Cpu0Config.h as follows, and do building with cmake and make again.
~/llvm/test/llvm/lib/Target/Cpu0SetChapter.h
#define CH CH3_1
118-165-78-230:input Jonathan$ /Users/Jonathan/llvm/test/build/
bin/llc -march=cpu0 -relocation-model=pic -filetype=asm ch3.bc -o
ch3.cpu0.s
... Assertion failed: (MRI && "Unable to create reg info"), function initAsmInfo
...
With Chapter3_1 implementation, the Chapter2 error message “Could not allocate target machine!” has gone. The new error say that we have not Target AsmPrinter and asm register info. We will add it in next section.
With the implementation of Chapter3_1, the Chapter2 error message “Could not allocate target machine!” has been resolved. The new error indicates that we lack Target AsmPrinter and ASM register info. We will add these in the next section.
Chapter3_1 creates FeatureCpu032I and FeatureCpu032II for CPUs cpu032I and cpu032II, respectively. Additionally, it defines two more features: FeatureCmp and FeatureSlt.
To demonstrate instruction set design choices, this book introduces two CPUs. Readers will understand why MIPS CPUs use the SLT instruction instead of CMP after reading the later chapter, “Control Flow Statement”.
With the added support for cpu032I and cpu032II in Cpu0.td and Cpu0InstrInfo.td from Chapter3_1, running the command:
llc -march=cpu0 -mcpu=help
will display messages as follows:
JonathantekiiMac:input Jonathan$ /Users/Jonathan/llvm/test/
build/bin/llc -march=cpu0 -mcpu=help
Available CPUs for this target:
cpu032I - Select the cpu032I processor.
cpu032II - Select the cpu032II processor.
Available features for this target:
ch10_1 - Enable Chapter instructions..
ch11_1 - Enable Chapter instructions..
ch11_2 - Enable Chapter instructions..
ch14_1 - Enable Chapter instructions..
ch3_1 - Enable Chapter instructions..
ch3_2 - Enable Chapter instructions..
ch3_3 - Enable Chapter instructions..
ch3_4 - Enable Chapter instructions..
ch3_5 - Enable Chapter instructions..
ch4_1 - Enable Chapter instructions..
ch4_2 - Enable Chapter instructions..
ch5_1 - Enable Chapter instructions..
ch6_1 - Enable Chapter instructions..
ch7_1 - Enable Chapter instructions..
ch8_1 - Enable Chapter instructions..
ch8_2 - Enable Chapter instructions..
ch9_1 - Enable Chapter instructions..
ch9_2 - Enable Chapter instructions..
ch9_3 - Enable Chapter instructions..
chall - Enable Chapter instructions..
cmp - Enable 'cmp' instructions..
cpu032I - Cpu032I ISA Support.
cpu032II - Cpu032II ISA Support (slt).
o32 - Enable o32 ABI.
s32 - Enable s32 ABI.
slt - Enable 'slt' instructions..
Use +feature to enable a feature, or -feature to disable it.
For example, llc -mcpu=mycpu -mattr=+feature1,-feature2
...
When the user inputs -mcpu=cpu032I, the variable IsCpu032I from
Cpu0InstrInfo.td will be true since the function isCpu032I() defined
in Cpu0Subtarget.h returns true. This happens because Cpu0ArchVersion
is set to cpu032I in initializeSubtargetDependencies(), which is called
in the constructor. The variable CPU in the constructor is “cpu032I” when
the user inputs -mcpu=cpu032I.
Please note that the variable Cpu0ArchVersion must be initialized in
Cpu0Subtarget.cpp. Otherwise, Cpu0ArchVersion may hold an undefined value,
causing issues with isCpu032I() and isCpu032II(), which support
llc -mcpu=cpu032I and llc -mcpu=cpu032II, respectively.
The values of the variables HasCmp and HasSlt depend on Cpu0ArchVersion. The instructions slt, beq, etc., are supported only if HasSlt is true. Furthermore, HasSlt is true only when Cpu0ArchVersion is Cpu032II.
Similarly, Ch4_1, Ch4_2, etc., control the enabling or disabling of instruction definitions. Through Subtarget->hasChapter4_1(), which exists in both Cpu0.td and Cpu0Subtarget.h, predicates such as Ch4_1, defined in Cpu0InstrInfo.td, can be enabled or disabled.
For example, the shift-rotate instructions can be enabled by defining CH to be greater than or equal to CH4_1, as shown below:
lbdex/Cpu0/Cpu0InstrInfo.td
let Predicates = [Ch4_1] in {
class shift_rotate_reg<bits<8> op, bits<4> isRotate, string instr_asm,
SDNode OpNode, RegisterClass RC>:
FA<op, (outs GPROut:$ra), (ins RC:$rb, RC:$rc),
!strconcat(instr_asm, "\t$ra, $rb, $rc"),
[(set GPROut:$ra, (OpNode RC:$rb, RC:$rc))], IIAlu> {
let shamt = 0;
}
}
~/llvm/test/llvm/lib/Target/Cpu0SetChapter.h
#define CH CH4_1
On the contrary, it can be disabled by define it to less than CH4_1, for instance CH3_5, as follows,
~/llvm/test/llvm/lib/Target/Cpu0SetChapter.h
#define CH CH3_5
Add AsmPrinter¶
![digraph G {
rankdir=LR;
MCInst [style="filled,bold", fillcolor=lightgreen];
assembly [style="filled,bold", fillcolor=lightgreen];
"llvm-ir" -> DAG -> MachineInstr -> MCInst -> assembly;
}](_images/graphviz-a7c0e62c0fcbaec635c45fce36154e8cf8888d31.png)
Fig. 22 When “llc -filetype=asm”, Cpu0AsmPrinter extract MCInst from MachineInstr for asm encoding¶
As Fig. 22, because MachineInstr is a big class for opitmization and convertion in many passes. LLVM creates MCInst for encoding purpose in assembly and binary object.
Chapter3_2/ contains the Cpu0AsmPrinter definition.
lbdex/chapters/Chapter2/Cpu0.td
def Cpu0InstrInfo : InstrInfo;
// Will generate Cpu0GenAsmWrite.inc included by Cpu0InstPrinter.cpp, contents
// as follows,
// void Cpu0InstPrinter::printInstruction(const MCInst *MI, raw_ostream &O) {...}
// const char *Cpu0InstPrinter::getRegisterName(unsigned RegNo) {...}
def Cpu0 : Target {
// def Cpu0InstrInfo : InstrInfo as before.
let InstructionSet = Cpu0InstrInfo;
}
As mentioned in the comments of Chapter2/Cpu0.td, it will generate Cpu0GenAsmWriter.inc, which is included by Cpu0InstPrinter.cpp as follows:
lbdex/chapters/Chapter3_2/InstPrinter/Cpu0InstPrinter.h
//=== Cpu0InstPrinter.h - Convert Cpu0 MCInst to assembly syntax -*- C++ -*-==//
//
// The LLVM Compiler Infrastructure
//
// This file is distributed under the University of Illinois Open Source
// License. See LICENSE.TXT for details.
//
//===----------------------------------------------------------------------===//
//
// This class prints a Cpu0 MCInst to a .s file.
//
//===----------------------------------------------------------------------===//
#ifndef LLVM_LIB_TARGET_CPU0_INSTPRINTER_CPU0INSTPRINTER_H
#define LLVM_LIB_TARGET_CPU0_INSTPRINTER_CPU0INSTPRINTER_H
#include "Cpu0Config.h"
#include "llvm/MC/MCInstPrinter.h"
namespace llvm {
// These enumeration declarations were orignally in Cpu0InstrInfo.h but
// had to be moved here to avoid circular dependencies between
// LLVMCpu0CodeGen and LLVMCpu0AsmPrinter.
class TargetMachine;
class Cpu0InstPrinter : public MCInstPrinter {
public:
Cpu0InstPrinter(const MCAsmInfo &MAI, const MCInstrInfo &MII,
const MCRegisterInfo &MRI)
: MCInstPrinter(MAI, MII, MRI) {}
// Autogenerated by tblgen.
std::pair<const char *, uint64_t> getMnemonic(const MCInst *MI) override;
void printInstruction(const MCInst *MI, uint64_t Address, raw_ostream &O);
static const char *getRegisterName(unsigned RegNo);
void printRegName(raw_ostream &OS, unsigned RegNo) const override;
void printInst(const MCInst *MI, uint64_t Address, StringRef Annot,
const MCSubtargetInfo &STI, raw_ostream &O) override;
bool printAliasInstr(const MCInst *MI, uint64_t Address, raw_ostream &OS);
void printCustomAliasOperand(const MCInst *MI, uint64_t Address,
unsigned OpIdx, unsigned PrintMethodIdx,
raw_ostream &O);
private:
void printOperand(const MCInst *MI, unsigned OpNo, raw_ostream &O);
void printOperand(const MCInst *MI, uint64_t /*Address*/, unsigned OpNum,
raw_ostream &O) {
printOperand(MI, OpNum, O);
}
void printUnsignedImm(const MCInst *MI, int opNum, raw_ostream &O);
void printMemOperand(const MCInst *MI, int opNum, raw_ostream &O);
//#if CH >= CH7_1
void printMemOperandEA(const MCInst *MI, int opNum, raw_ostream &O);
//#endif
};
} // end namespace llvm
#endif
lbdex/chapters/Chapter3_2/InstPrinter/Cpu0InstPrinter.cpp
//===-- Cpu0InstPrinter.cpp - Convert Cpu0 MCInst to assembly syntax ------===//
//
// The LLVM Compiler Infrastructure
//
// This file is distributed under the University of Illinois Open Source
// License. See LICENSE.TXT for details.
//
//===----------------------------------------------------------------------===//
//
// This class prints an Cpu0 MCInst to a .s file.
//
//===----------------------------------------------------------------------===//
#include "Cpu0InstPrinter.h"
#include "Cpu0InstrInfo.h"
#include "llvm/ADT/StringExtras.h"
#include "llvm/MC/MCExpr.h"
#include "llvm/MC/MCInst.h"
#include "llvm/MC/MCInstrInfo.h"
#include "llvm/MC/MCSymbol.h"
#include "llvm/Support/ErrorHandling.h"
#include "llvm/Support/raw_ostream.h"
using namespace llvm;
#define DEBUG_TYPE "asm-printer"
#define PRINT_ALIAS_INSTR
#include "Cpu0GenAsmWriter.inc"
void Cpu0InstPrinter::printRegName(raw_ostream &OS, unsigned RegNo) const {
//- getRegisterName(RegNo) defined in Cpu0GenAsmWriter.inc which indicate in
// Cpu0.td.
OS << '$' << StringRef(getRegisterName(RegNo)).lower();
}
//@1 {
void Cpu0InstPrinter::printInst(const MCInst *MI, uint64_t Address,
StringRef Annot, const MCSubtargetInfo &STI,
raw_ostream &O) {
// Try to print any aliases first.
if (!printAliasInstr(MI, Address, O))
//@1 }
//- printInstruction(MI, O) defined in Cpu0GenAsmWriter.inc which came from
// Cpu0.td indicate.
printInstruction(MI, Address, O);
printAnnotation(O, Annot);
}
void Cpu0InstPrinter::printOperand(const MCInst *MI, unsigned OpNo,
raw_ostream &O) {
const MCOperand &Op = MI->getOperand(OpNo);
if (Op.isReg()) {
printRegName(O, Op.getReg());
return;
}
if (Op.isImm()) {
O << Op.getImm();
return;
}
assert(Op.isExpr() && "unknown operand kind in printOperand");
Op.getExpr()->print(O, &MAI, true);
}
void Cpu0InstPrinter::printUnsignedImm(const MCInst *MI, int opNum,
raw_ostream &O) {
const MCOperand &MO = MI->getOperand(opNum);
if (MO.isImm())
O << (unsigned short int)MO.getImm();
else
printOperand(MI, opNum, O);
}
void Cpu0InstPrinter::
printMemOperand(const MCInst *MI, int opNum, raw_ostream &O) {
// Load/Store memory operands -- imm($reg)
// If PIC target the target is loaded as the
// pattern ld $t9,%call16($gp)
printOperand(MI, opNum+1, O);
O << "(";
printOperand(MI, opNum, O);
O << ")";
}
//#if CH >= CH7_1
// The DAG data node, mem_ea of Cpu0InstrInfo.td, cannot be disabled by
// ch7_1, only opcode node can be disabled.
void Cpu0InstPrinter::
printMemOperandEA(const MCInst *MI, int opNum, raw_ostream &O) {
// when using stack locations for not load/store instructions
// print the same way as all normal 3 operand instructions.
printOperand(MI, opNum, O);
O << ", ";
printOperand(MI, opNum+1, O);
return;
}
//#endif
lbdex/chapters/Chapter3_2/InstPrinter/CMakeLists.txt
add_llvm_component_library(LLVMCpu0AsmPrinter
Cpu0InstPrinter.cpp
LINK_COMPONENTS
Support
ADD_TO_COMPONENT
Cpu0
)
Cpu0GenAsmWriter.inc contains the implementations of Cpu0InstPrinter::printInstruction() and Cpu0InstPrinter::getRegisterName(). Both of these functions are auto-generated based on the information defined in Cpu0InstrInfo.td and Cpu0RegisterInfo.td.
To enable these functions in our code, we only need to add a class Cpu0InstPrinter and include them, as demonstrated in Chapter3_2.
The file Chapter3_2/Cpu0/InstPrinter/Cpu0InstPrinter.cpp includes Cpu0GenAsmWriter.inc and invokes the auto-generated functions from TableGen.
The process of printing assembly and the interaction between Cpu0InstPrinter.cpp and Cpu0GenAsmWriter.inc is illustrated in Fig. 23.
Cpu0AsmPrinter::emitInstruction() calls Cpu0MCInstLower::Lower(const MachineInstr *MI, MCInst &OutMI) to extract MCInst from MachineInstr.
![digraph G {
rankdir=TB;
E1 -> E2 [label="MachineInstr"];
E2 -> E1 [label="MCInst"];
E1 -> E3 [label="MCInst"];
E3 -> "MCTargetStreamer::prettyPrintAsm()" [label="MCInst"];
"MCTargetStreamer::prettyPrintAsm()" -> "printInst()" [label="MCInst"];
"printInst()" -> "printInstruction()" [label="MCInst"];
"printInstruction()" -> "getMnemonic()" [label="MCInst,opNum"];
"getMnemonic()" -> "printInstruction()" [label="(NameOfOpcode,Bits*)"];
"printInstruction()" -> POP [label="MCInst,opNum"];
POP:P1 -> "getRegisterName()" [label="RegNo"];
"getRegisterName()" -> POP:P1 [label="RegName"];
"printInst()" -> "printAliasInstr()";
subgraph clusterCpu0Asm {
label = "Cpu0AsmPrinter.cpp";
E1 [label="Cpu0AsmPrinter::emitInstruction()"];
}
subgraph clusterMCInstLower {
label = "lib/MC/MCInstLower.cpp";
E2 [label="Cpu0MCInstLower::Lower()"];
}
subgraph clusterMCAsm {
label = "lib/MC/MCAsmStreamer.cpp";
E3 [label="MCAsmStreamer::emitInstruction()*"];
}
subgraph clusterMC {
label = "lib/MC/MCStreamer.cpp";
"MCTargetStreamer::prettyPrintAsm()";
}
subgraph clusterInc {
label = "Cpu0GenAsmWrite.inc";
getMnemonic [label="getMnemonic()"];
"printInstruction()";
"getRegisterName()";
"printAliasInstr()" [label="printAliasInstr()\n (print \"move $fp, $sp\" instead of \n addiu $fp, 0, $sp)\n"];
}
subgraph clusterCpu0InstPrinter {
label = "Cpu0InstPrinter.cpp";
"printInst()";
POP [label="<P1> printRegName() | printUnsignedImm() | printMemOperand() | printOperand()", shape=record];
}
// label = "Figure: The flow of printing assembly and calling between Cpu0InstPrinter.cpp and Cpu0GenAsmWrite.inc";
}](_images/graphviz-57820ee296dfb48ae95e71b6bb5459926ccd580e.png)
Fig. 23 The flow of printing assembly and calling between Cpu0InstPrinter.cpp and Cpu0GenAsmWrite.inc¶
AsmPrinter::OutStreamer is nMCAsmStreamer if llc -filetype=asm; AsmPrinter::OutStreamer is nMCObjectStreamer if llc -filetype=obj as Fig. 31.
Bits is the format of instruction for Opcode, used to print “,” between operands.
The function Cpu0InstPrinter::printMemOperand() is defined in Chapter3_2/InstPrinter/Cpu0InstPrinter.cpp, as shown above. This function is triggered because Cpu0InstrInfo.td defines ‘let PrintMethod = “printMemOperand”;’, as shown below.
lbdex/chapters/Chapter2/Cpu0InstrInfo.td
// Address operand
def mem : Operand<i32> {
let PrintMethod = "printMemOperand";
let MIOperandInfo = (ops CPURegs, simm16);
let EncoderMethod = "getMemEncoding";
}
...
// 32-bit load.
multiclass LoadM32<bits<8> op, string instr_asm, PatFrag OpNode,
bit Pseudo = 0> {
def #NAME# : LoadM<op, instr_asm, OpNode, GPROut, mem, Pseudo>;
}
// 32-bit store.
multiclass StoreM32<bits<8> op, string instr_asm, PatFrag OpNode,
bit Pseudo = 0> {
def #NAME# : StoreM<op, instr_asm, OpNode, CPURegs, mem, Pseudo>;
}
defm LD : LoadM32<0x01, "ld", load_a>;
defm ST : StoreM32<0x02, "st", store_a>;
Cpu0InstPrinter::printMemOperand() will print backend operands for “local variable access”, which is like the following,
ld $2, 16($fp)
st $2, 8($fp)
Next, add Cpu0MCInstLower (Cpu0MCInstLower.h, Cpu0MCInstLower.cpp) as well as Cpu0BaseInfo.h, Cpu0FixupKinds.h, and Cpu0MCAsmInfo (Cpu0MCAsmInfo.h, Cpu0MCAsmInfo.cpp) in the sub-directory MCTargetDesc, as shown below.
lbdex/chapters/Chapter3_2/Cpu0MCInstLower.h
//===-- Cpu0MCInstLower.h - Lower MachineInstr to MCInst -------*- C++ -*--===//
//
// The LLVM Compiler Infrastructure
//
// This file is distributed under the University of Illinois Open Source
// License. See LICENSE.TXT for details.
//
//===----------------------------------------------------------------------===//
#ifndef LLVM_LIB_TARGET_CPU0_CPU0MCINSTLOWER_H
#define LLVM_LIB_TARGET_CPU0_CPU0MCINSTLOWER_H
#include "Cpu0Config.h"
#include "llvm/ADT/SmallVector.h"
#include "llvm/CodeGen/MachineOperand.h"
#include "llvm/Support/Compiler.h"
namespace llvm {
class MCContext;
class MCInst;
class MCOperand;
class MachineInstr;
class MachineFunction;
class Cpu0AsmPrinter;
//@1 {
/// This class is used to lower an MachineInstr into an MCInst.
class LLVM_LIBRARY_VISIBILITY Cpu0MCInstLower {
//@2
typedef MachineOperand::MachineOperandType MachineOperandType;
MCContext *Ctx;
Cpu0AsmPrinter &AsmPrinter;
public:
Cpu0MCInstLower(Cpu0AsmPrinter &asmprinter);
void Initialize(MCContext* C);
void Lower(const MachineInstr *MI, MCInst &OutMI) const;
MCOperand LowerOperand(const MachineOperand& MO, unsigned offset = 0) const;
};
}
#endif
lbdex/chapters/Chapter3_2/Cpu0MCInstLower.cpp
//===-- Cpu0MCInstLower.cpp - Convert Cpu0 MachineInstr to MCInst ---------===//
//
// The LLVM Compiler Infrastructure
//
// This file is distributed under the University of Illinois Open Source
// License. See LICENSE.TXT for details.
//
//===----------------------------------------------------------------------===//
//
// This file contains code to lower Cpu0 MachineInstrs to their corresponding
// MCInst records.
//
//===----------------------------------------------------------------------===//
#include "Cpu0MCInstLower.h"
#include "Cpu0AsmPrinter.h"
#include "Cpu0InstrInfo.h"
#include "MCTargetDesc/Cpu0BaseInfo.h"
#include "llvm/CodeGen/MachineFunction.h"
#include "llvm/CodeGen/MachineInstr.h"
#include "llvm/CodeGen/MachineOperand.h"
#include "llvm/IR/Mangler.h"
#include "llvm/MC/MCContext.h"
#include "llvm/MC/MCExpr.h"
#include "llvm/MC/MCInst.h"
using namespace llvm;
Cpu0MCInstLower::Cpu0MCInstLower(Cpu0AsmPrinter &asmprinter)
: AsmPrinter(asmprinter) {}
void Cpu0MCInstLower::Initialize(MCContext* C) {
Ctx = C;
}
static void CreateMCInst(MCInst& Inst, unsigned Opc, const MCOperand& Opnd0,
const MCOperand& Opnd1,
const MCOperand& Opnd2 = MCOperand()) {
Inst.setOpcode(Opc);
Inst.addOperand(Opnd0);
Inst.addOperand(Opnd1);
if (Opnd2.isValid())
Inst.addOperand(Opnd2);
}
//@LowerOperand {
MCOperand Cpu0MCInstLower::LowerOperand(const MachineOperand& MO,
unsigned offset) const {
MachineOperandType MOTy = MO.getType();
switch (MOTy) {
//@2
default: llvm_unreachable("unknown operand type");
case MachineOperand::MO_Register:
// Ignore all implicit register operands.
if (MO.isImplicit()) break;
return MCOperand::createReg(MO.getReg());
case MachineOperand::MO_Immediate:
return MCOperand::createImm(MO.getImm() + offset);
case MachineOperand::MO_RegisterMask:
break;
}
return MCOperand();
}
void Cpu0MCInstLower::Lower(const MachineInstr *MI, MCInst &OutMI) const {
OutMI.setOpcode(MI->getOpcode());
for (unsigned i = 0, e = MI->getNumOperands(); i != e; ++i) {
const MachineOperand &MO = MI->getOperand(i);
MCOperand MCOp = LowerOperand(MO);
if (MCOp.isValid())
OutMI.addOperand(MCOp);
}
}
lbdex/chapters/Chapter3_2/MCTargetDesc/Cpu0BaseInfo.h
//===-- Cpu0BaseInfo.h - Top level definitions for CPU0 MC ------*- C++ -*-===//
//
// The LLVM Compiler Infrastructure
//
// This file is distributed under the University of Illinois Open Source
// License. See LICENSE.TXT for details.
//
//===----------------------------------------------------------------------===//
//
// This file contains small standalone helper functions and enum definitions for
// the Cpu0 target useful for the compiler back-end and the MC libraries.
//
//===----------------------------------------------------------------------===//
#ifndef LLVM_LIB_TARGET_CPU0_MCTARGETDESC_CPU0BASEINFO_H
#define LLVM_LIB_TARGET_CPU0_MCTARGETDESC_CPU0BASEINFO_H
#include "Cpu0Config.h"
#include "Cpu0MCTargetDesc.h"
#include "llvm/MC/MCExpr.h"
#include "llvm/Support/DataTypes.h"
#include "llvm/Support/ErrorHandling.h"
namespace llvm {
/// Cpu0II - This namespace holds all of the target specific flags that
/// instruction info tracks.
//@Cpu0II
namespace Cpu0II {
/// Target Operand Flag enum.
enum TOF {
//===------------------------------------------------------------------===//
// Cpu0 Specific MachineOperand flags.
MO_NO_FLAG,
/// MO_GOT_CALL - Represents the offset into the global offset table at
/// which the address of a call site relocation entry symbol resides
/// during execution. This is different from the above since this flag
/// can only be present in call instructions.
MO_GOT_CALL,
/// MO_GPREL - Represents the offset from the current gp value to be used
/// for the relocatable object file being produced.
MO_GPREL,
/// MO_ABS_HI/LO - Represents the hi or low part of an absolute symbol
/// address.
MO_ABS_HI,
MO_ABS_LO,
/// MO_GOT_HI16/LO16 - Relocations used for large GOTs.
MO_GOT_HI16,
MO_GOT_LO16
}; // enum TOF {
enum {
//===------------------------------------------------------------------===//
// Instruction encodings. These are the standard/most common forms for
// Cpu0 instructions.
//
// Pseudo - This represents an instruction that is a pseudo instruction
// or one that has not been implemented yet. It is illegal to code generate
// it, but tolerated for intermediate implementation stages.
Pseudo = 0,
/// FrmR - This form is for instructions of the format R.
FrmR = 1,
/// FrmI - This form is for instructions of the format I.
FrmI = 2,
/// FrmJ - This form is for instructions of the format J.
FrmJ = 3,
/// FrmOther - This form is for instructions that have no specific format.
FrmOther = 4,
FormMask = 15
};
}
}
#endif
lbdex/chapters/Chapter3_2/Cpu0MCAsmInfo.h
//===-- Cpu0MCAsmInfo.h - Cpu0 Asm Info ------------------------*- C++ -*--===//
//
// The LLVM Compiler Infrastructure
//
// This file is distributed under the University of Illinois Open Source
// License. See LICENSE.TXT for details.
//
//===----------------------------------------------------------------------===//
//
// This file contains the declaration of the Cpu0MCAsmInfo class.
//
//===----------------------------------------------------------------------===//
#ifndef LLVM_LIB_TARGET_CPU0_MCTARGETDESC_CPU0MCASMINFO_H
#define LLVM_LIB_TARGET_CPU0_MCTARGETDESC_CPU0MCASMINFO_H
#include "Cpu0Config.h"
#if CH >= CH3_2
#include "llvm/MC/MCAsmInfoELF.h"
namespace llvm {
class Triple;
class Cpu0MCAsmInfo : public MCAsmInfoELF {
void anchor() override;
public:
explicit Cpu0MCAsmInfo(const Triple &TheTriple);
};
} // namespace llvm
#endif // #if CH >= CH3_2
#endif
lbdex/chapters/Chapter3_2/Cpu0MCAsmInfo.cpp
//===-- Cpu0MCAsmInfo.cpp - Cpu0 Asm Properties ---------------------------===//
//
// The LLVM Compiler Infrastructure
//
// This file is distributed under the University of Illinois Open Source
// License. See LICENSE.TXT for details.
//
//===----------------------------------------------------------------------===//
//
// This file contains the declarations of the Cpu0MCAsmInfo properties.
//
//===----------------------------------------------------------------------===//
#include "Cpu0MCAsmInfo.h"
#if CH >= CH3_2
#include "llvm/ADT/Triple.h"
using namespace llvm;
void Cpu0MCAsmInfo::anchor() { }
Cpu0MCAsmInfo::Cpu0MCAsmInfo(const Triple &TheTriple) {
if ((TheTriple.getArch() == Triple::cpu0))
IsLittleEndian = false; // the default of IsLittleEndian is true
AlignmentIsInBytes = false;
Data16bitsDirective = "\t.2byte\t";
Data32bitsDirective = "\t.4byte\t";
Data64bitsDirective = "\t.8byte\t";
PrivateGlobalPrefix = "$";
// PrivateLabelPrefix: display $BB for the labels of basic block
PrivateLabelPrefix = "$";
CommentString = "#";
ZeroDirective = "\t.space\t";
GPRel32Directive = "\t.gpword\t";
GPRel64Directive = "\t.gpdword\t";
WeakRefDirective = "\t.weak\t";
UseAssignmentForEHBegin = true;
SupportsDebugInformation = true;
ExceptionsType = ExceptionHandling::DwarfCFI;
DwarfRegNumForCFI = true;
}
#endif // #if CH >= CH3_2
Finally, add code in Cpu0MCTargetDesc.cpp to register Cpu0InstPrinter as shown below. It also registers other classes (register, instruction, and subtarget) that were defined in Chapter3_1 at this point.
lbdex/chapters/Chapter3_2/MCTargetDesc/Cpu0MCTargetDesc.h
namespace llvm {
class MCAsmBackend;
class MCCodeEmitter;
class MCContext;
class MCInstrInfo;
class MCObjectWriter;
class MCRegisterInfo;
class MCSubtargetInfo;
class StringRef;
...
class raw_ostream;
...
}
lbdex/chapters/Chapter3_2/MCTargetDesc/Cpu0MCTargetDesc.cpp
#include "InstPrinter/Cpu0InstPrinter.h"
#include "Cpu0MCAsmInfo.h"
/// Select the Cpu0 Architecture Feature for the given triple and cpu name.
/// The function will be called at command 'llvm-objdump -d' for Cpu0 elf input.
static std::string selectCpu0ArchFeature(const Triple &TT, StringRef CPU) {
std::string Cpu0ArchFeature;
if (CPU.empty() || CPU == "generic") {
if (TT.getArch() == Triple::cpu0 || TT.getArch() == Triple::cpu0el) {
if (CPU.empty() || CPU == "cpu032II") {
Cpu0ArchFeature = "+cpu032II";
}
else {
if (CPU == "cpu032I") {
Cpu0ArchFeature = "+cpu032I";
}
}
}
}
return Cpu0ArchFeature;
}
//@1 }
static MCInstrInfo *createCpu0MCInstrInfo() {
MCInstrInfo *X = new MCInstrInfo();
InitCpu0MCInstrInfo(X); // defined in Cpu0GenInstrInfo.inc
return X;
}
static MCRegisterInfo *createCpu0MCRegisterInfo(const Triple &TT) {
MCRegisterInfo *X = new MCRegisterInfo();
InitCpu0MCRegisterInfo(X, Cpu0::SW); // defined in Cpu0GenRegisterInfo.inc
return X;
}
static MCSubtargetInfo *createCpu0MCSubtargetInfo(const Triple &TT,
StringRef CPU, StringRef FS) {
std::string ArchFS = selectCpu0ArchFeature(TT,CPU);
if (!FS.empty()) {
if (!ArchFS.empty())
ArchFS = ArchFS + "," + FS.str();
else
ArchFS = FS.str();
}
return createCpu0MCSubtargetInfoImpl(TT, CPU, /*TuneCPU*/ CPU, ArchFS);
// createCpu0MCSubtargetInfoImpl defined in Cpu0GenSubtargetInfo.inc
}
static MCAsmInfo *createCpu0MCAsmInfo(const MCRegisterInfo &MRI,
const Triple &TT,
const MCTargetOptions &Options) {
MCAsmInfo *MAI = new Cpu0MCAsmInfo(TT);
unsigned SP = MRI.getDwarfRegNum(Cpu0::SP, true);
MCCFIInstruction Inst = MCCFIInstruction::createDefCfaRegister(nullptr, SP);
MAI->addInitialFrameState(Inst);
return MAI;
}
static MCInstPrinter *createCpu0MCInstPrinter(const Triple &T,
unsigned SyntaxVariant,
const MCAsmInfo &MAI,
const MCInstrInfo &MII,
const MCRegisterInfo &MRI) {
return new Cpu0InstPrinter(MAI, MII, MRI);
}
namespace {
class Cpu0MCInstrAnalysis : public MCInstrAnalysis {
public:
Cpu0MCInstrAnalysis(const MCInstrInfo *Info) : MCInstrAnalysis(Info) {}
};
}
static MCInstrAnalysis *createCpu0MCInstrAnalysis(const MCInstrInfo *Info) {
return new Cpu0MCInstrAnalysis(Info);
}
//@2 {
extern "C" void LLVMInitializeCpu0TargetMC() {
for (Target *T : {&TheCpu0Target, &TheCpu0elTarget}) {
// Register the MC asm info.
RegisterMCAsmInfoFn X(*T, createCpu0MCAsmInfo);
// Register the MC instruction info.
TargetRegistry::RegisterMCInstrInfo(*T, createCpu0MCInstrInfo);
// Register the MC register info.
TargetRegistry::RegisterMCRegInfo(*T, createCpu0MCRegisterInfo);
// Register the MC subtarget info.
TargetRegistry::RegisterMCSubtargetInfo(*T,
createCpu0MCSubtargetInfo);
// Register the MC instruction analyzer.
TargetRegistry::RegisterMCInstrAnalysis(*T, createCpu0MCInstrAnalysis);
// Register the MCInstPrinter.
TargetRegistry::RegisterMCInstPrinter(*T,
createCpu0MCInstPrinter);
}
}
//@2 }
lbdex/chapters/Chapter3_2/MCTargetDesc/CMakeLists.txt
Cpu0MCAsmInfo.cpp
To make the registration clearly, summary as the following diagram, Fig. 24.
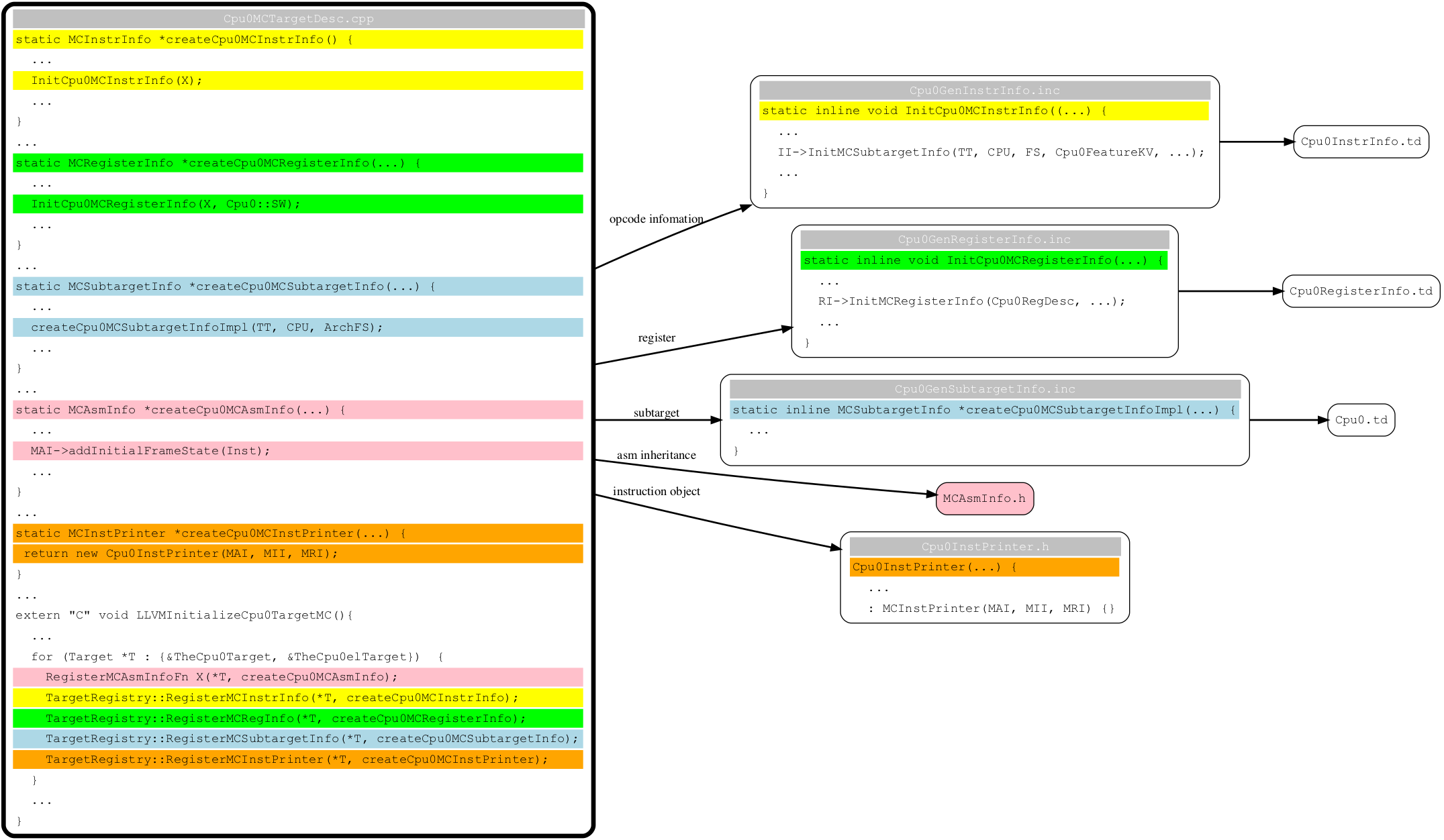
Fig. 24 Tblgen generate files for Cpu0 backend¶
Above createCpu0MCAsmInfo() registering the object of class Cpu0MCAsmInfo for target TheCpu0Target and TheCpu0elTarget. TheCpu0Target is for big endian and TheCpu0elTarget is for little endian. Cpu0MCAsmInfo is derived from MCAsmInfo which is an llvm built-in class. Most code is implemented in it’s parent, backend reuses those code by inheritance.
Above createCpu0MCAsmInfo() registers the Cpu0MCAsmInfo object for the targets TheCpu0Target (big-endian) and TheCpu0elTarget (little-endian). Cpu0MCAsmInfo is derived from MCAsmInfo, an LLVM built-in class. Most of its functionality is inherited from its parent class.
Above createCpu0MCInstrInfo() instantiates an MCInstrInfo object X and initializes it using InitCpu0MCInstrInfo(X). Since InitCpu0MCInstrInfo(X) is defined in Cpu0GenInstrInfo.inc, this function incorporates the instruction details specified in Cpu0InstrInfo.td.
Above createCpu0MCInstPrinter() instantiates Cpu0InstPrinter, which handles instruction printing.
Above createCpu0MCRegisterInfo() follows a similar approach to “Register function of MC instruction info” but initializes register information from Cpu0RegisterInfo.td. It reuses values from the instruction/register TableGen descriptions, eliminating redundancy in the initialization routine if they remain consistent.
Above createCpu0MCSubtargetInfo() instantiates an MCSubtargetInfo object and initializes it with details from Cpu0.td.
According to “section Target Registration” [3], we can register Cpu0 backend classes in LLVMInitializeCpu0TargetMC() using LLVM’s dynamic registration mechanism.
Now, it’s time to work with AsmPrinter, as shown below.
lbdex/chapters/Chapter3_2/Cpu0AsmPrinter.h
//===-- Cpu0AsmPrinter.h - Cpu0 LLVM Assembly Printer ----------*- C++ -*--===//
//
// The LLVM Compiler Infrastructure
//
// This file is distributed under the University of Illinois Open Source
// License. See LICENSE.TXT for details.
//
//===----------------------------------------------------------------------===//
//
// Cpu0 Assembly printer class.
//
//===----------------------------------------------------------------------===//
#ifndef LLVM_LIB_TARGET_CPU0_CPU0ASMPRINTER_H
#define LLVM_LIB_TARGET_CPU0_CPU0ASMPRINTER_H
#include "Cpu0Config.h"
#include "Cpu0MachineFunction.h"
#include "Cpu0MCInstLower.h"
#include "Cpu0Subtarget.h"
#include "Cpu0TargetMachine.h"
#include "llvm/CodeGen/AsmPrinter.h"
#include "llvm/MC/MCStreamer.h"
#include "llvm/Support/Compiler.h"
#include "llvm/Target/TargetMachine.h"
namespace llvm {
class MCStreamer;
class MachineInstr;
class MachineBasicBlock;
class Module;
class raw_ostream;
class LLVM_LIBRARY_VISIBILITY Cpu0AsmPrinter : public AsmPrinter {
void EmitInstrWithMacroNoAT(const MachineInstr *MI);
private:
// lowerOperand - Convert a MachineOperand into the equivalent MCOperand.
bool lowerOperand(const MachineOperand &MO, MCOperand &MCOp);
public:
const Cpu0Subtarget *Subtarget;
const Cpu0FunctionInfo *Cpu0FI;
Cpu0MCInstLower MCInstLowering;
explicit Cpu0AsmPrinter(TargetMachine &TM,
std::unique_ptr<MCStreamer> Streamer)
: AsmPrinter(TM, std::move(Streamer)),
MCInstLowering(*this) {
Subtarget = static_cast<Cpu0TargetMachine &>(TM).getSubtargetImpl();
}
StringRef getPassName() const override {
return "Cpu0 Assembly Printer";
}
virtual bool runOnMachineFunction(MachineFunction &MF) override;
//- emitInstruction() must exists or will have run time error.
void emitInstruction(const MachineInstr *MI) override;
void printSavedRegsBitmask(raw_ostream &O);
void printHex32(unsigned int Value, raw_ostream &O);
void emitFrameDirective();
const char *getCurrentABIString() const;
void emitFunctionEntryLabel() override;
void emitFunctionBodyStart() override;
void emitFunctionBodyEnd() override;
void emitStartOfAsmFile(Module &M) override;
void PrintDebugValueComment(const MachineInstr *MI, raw_ostream &OS);
};
}
#endif
lbdex/chapters/Chapter3_2/Cpu0AsmPrinter.cpp
//===-- Cpu0AsmPrinter.cpp - Cpu0 LLVM Assembly Printer -------------------===//
//
// The LLVM Compiler Infrastructure
//
// This file is distributed under the University of Illinois Open Source
// License. See LICENSE.TXT for details.
//
//===----------------------------------------------------------------------===//
//
// This file contains a printer that converts from our internal representation
// of machine-dependent LLVM code to GAS-format CPU0 assembly language.
//
//===----------------------------------------------------------------------===//
#include "Cpu0AsmPrinter.h"
#include "InstPrinter/Cpu0InstPrinter.h"
#include "MCTargetDesc/Cpu0BaseInfo.h"
#include "Cpu0.h"
#include "Cpu0InstrInfo.h"
#include "llvm/ADT/SmallString.h"
#include "llvm/ADT/StringExtras.h"
#include "llvm/ADT/Twine.h"
#include "llvm/CodeGen/MachineConstantPool.h"
#include "llvm/CodeGen/MachineFunctionPass.h"
#include "llvm/CodeGen/MachineFrameInfo.h"
#include "llvm/CodeGen/MachineInstr.h"
#include "llvm/CodeGen/MachineMemOperand.h"
#include "llvm/IR/BasicBlock.h"
#include "llvm/IR/Instructions.h"
#include "llvm/IR/Mangler.h"
#include "llvm/MC/MCAsmInfo.h"
#include "llvm/MC/MCInst.h"
#include "llvm/MC/MCStreamer.h"
#include "llvm/MC/MCSymbol.h"
#include "llvm/Support/raw_ostream.h"
#include "llvm/Support/TargetRegistry.h"
#include "llvm/Target/TargetLoweringObjectFile.h"
#include "llvm/Target/TargetOptions.h"
using namespace llvm;
#define DEBUG_TYPE "cpu0-asm-printer"
bool Cpu0AsmPrinter::runOnMachineFunction(MachineFunction &MF) {
Cpu0FI = MF.getInfo<Cpu0FunctionInfo>();
AsmPrinter::runOnMachineFunction(MF);
return true;
}
//@EmitInstruction {
//- emitInstruction() must exists or will have run time error.
void Cpu0AsmPrinter::emitInstruction(const MachineInstr *MI) {
//@EmitInstruction body {
if (MI->isDebugValue()) {
SmallString<128> Str;
raw_svector_ostream OS(Str);
PrintDebugValueComment(MI, OS);
return;
}
//@print out instruction:
// Print out both ordinary instruction and boudle instruction
MachineBasicBlock::const_instr_iterator I = MI->getIterator();
MachineBasicBlock::const_instr_iterator E = MI->getParent()->instr_end();
do {
if (I->isPseudo())
llvm_unreachable("Pseudo opcode found in emitInstruction()");
MCInst TmpInst0;
// Call Cpu0MCInstLower::Lower(const MachineInstr *MI, MCInst &OutMI) to
// extracts MCInst from MachineInstr.
MCInstLowering.Lower(&*I, TmpInst0);
OutStreamer->emitInstruction(TmpInst0, getSubtargetInfo());
} while ((++I != E) && I->isInsideBundle()); // Delay slot check
}
//@EmitInstruction }
//===----------------------------------------------------------------------===//
//
// Cpu0 Asm Directives
//
// -- Frame directive "frame Stackpointer, Stacksize, RARegister"
// Describe the stack frame.
//
// -- Mask directives "(f)mask bitmask, offset"
// Tells the assembler which registers are saved and where.
// bitmask - contain a little endian bitset indicating which registers are
// saved on function prologue (e.g. with a 0x80000000 mask, the
// assembler knows the register 31 (RA) is saved at prologue.
// offset - the position before stack pointer subtraction indicating where
// the first saved register on prologue is located. (e.g. with a
//
// Consider the following function prologue:
//
// .frame $fp,48,$ra
// .mask 0xc0000000,-8
// addiu $sp, $sp, -48
// st $ra, 40($sp)
// st $fp, 36($sp)
//
// With a 0xc0000000 mask, the assembler knows the register 31 (RA) and
// 30 (FP) are saved at prologue. As the save order on prologue is from
// left to right, RA is saved first. A -8 offset means that after the
// stack pointer subtration, the first register in the mask (RA) will be
// saved at address 48-8=40.
//
//===----------------------------------------------------------------------===//
//===----------------------------------------------------------------------===//
// Mask directives
//===----------------------------------------------------------------------===//
// .frame $sp,8,$lr
//-> .mask 0x00000000,0
// .set noreorder
// .set nomacro
// Create a bitmask with all callee saved registers for CPU or Floating Point
// registers. For CPU registers consider LR, GP and FP for saving if necessary.
void Cpu0AsmPrinter::printSavedRegsBitmask(raw_ostream &O) {
// CPU and FPU Saved Registers Bitmasks
unsigned CPUBitmask = 0;
int CPUTopSavedRegOff;
// Set the CPU and FPU Bitmasks
const MachineFrameInfo &MFI = MF->getFrameInfo();
const TargetRegisterInfo *TRI = MF->getSubtarget().getRegisterInfo();
const std::vector<CalleeSavedInfo> &CSI = MFI.getCalleeSavedInfo();
// size of stack area to which FP callee-saved regs are saved.
unsigned CPURegSize = TRI->getRegSizeInBits(Cpu0::CPURegsRegClass) / 8;
unsigned i = 0, e = CSI.size();
// Set CPU Bitmask.
for (; i != e; ++i) {
unsigned Reg = CSI[i].getReg();
unsigned RegNum = TRI->getEncodingValue(Reg);
CPUBitmask |= (1 << RegNum);
}
CPUTopSavedRegOff = CPUBitmask ? -CPURegSize : 0;
// Print CPUBitmask
O << "\t.mask \t"; printHex32(CPUBitmask, O);
O << ',' << CPUTopSavedRegOff << '\n';
}
// Print a 32 bit hex number with all numbers.
void Cpu0AsmPrinter::printHex32(unsigned Value, raw_ostream &O) {
O << "0x";
for (int i = 7; i >= 0; i--)
O.write_hex((Value & (0xF << (i*4))) >> (i*4));
}
//===----------------------------------------------------------------------===//
// Frame and Set directives
//===----------------------------------------------------------------------===//
//-> .frame $sp,8,$lr
// .mask 0x00000000,0
// .set noreorder
// .set nomacro
/// Frame Directive
void Cpu0AsmPrinter::emitFrameDirective() {
const TargetRegisterInfo &RI = *MF->getSubtarget().getRegisterInfo();
unsigned stackReg = RI.getFrameRegister(*MF);
unsigned returnReg = RI.getRARegister();
unsigned stackSize = MF->getFrameInfo().getStackSize();
if (OutStreamer->hasRawTextSupport())
OutStreamer->emitRawText("\t.frame\t$" +
StringRef(Cpu0InstPrinter::getRegisterName(stackReg)).lower() +
"," + Twine(stackSize) + ",$" +
StringRef(Cpu0InstPrinter::getRegisterName(returnReg)).lower());
}
/// Emit Set directives.
const char *Cpu0AsmPrinter::getCurrentABIString() const {
switch (static_cast<Cpu0TargetMachine &>(TM).getABI().GetEnumValue()) {
case Cpu0ABIInfo::ABI::O32: return "abiO32";
case Cpu0ABIInfo::ABI::S32: return "abiS32";
default: llvm_unreachable("Unknown Cpu0 ABI");
}
}
// .type main,@function
//-> .ent main # @main
// main:
void Cpu0AsmPrinter::emitFunctionEntryLabel() {
if (OutStreamer->hasRawTextSupport())
OutStreamer->emitRawText("\t.ent\t" + Twine(CurrentFnSym->getName()));
OutStreamer->emitLabel(CurrentFnSym);
}
// .frame $sp,8,$pc
// .mask 0x00000000,0
//-> .set noreorder
//@-> .set nomacro
/// EmitFunctionBodyStart - Targets can override this to emit stuff before
/// the first basic block in the function.
void Cpu0AsmPrinter::emitFunctionBodyStart() {
MCInstLowering.Initialize(&MF->getContext());
emitFrameDirective();
if (OutStreamer->hasRawTextSupport()) {
SmallString<128> Str;
raw_svector_ostream OS(Str);
printSavedRegsBitmask(OS);
OutStreamer->emitRawText(OS.str());
OutStreamer->emitRawText(StringRef("\t.set\tnoreorder"));
OutStreamer->emitRawText(StringRef("\t.set\tnomacro"));
if (Cpu0FI->getEmitNOAT())
OutStreamer->emitRawText(StringRef("\t.set\tnoat"));
}
}
//-> .set macro
//-> .set reorder
//-> .end main
/// EmitFunctionBodyEnd - Targets can override this to emit stuff after
/// the last basic block in the function.
void Cpu0AsmPrinter::emitFunctionBodyEnd() {
// There are instruction for this macros, but they must
// always be at the function end, and we can't emit and
// break with BB logic.
if (OutStreamer->hasRawTextSupport()) {
if (Cpu0FI->getEmitNOAT())
OutStreamer->emitRawText(StringRef("\t.set\tat"));
OutStreamer->emitRawText(StringRef("\t.set\tmacro"));
OutStreamer->emitRawText(StringRef("\t.set\treorder"));
OutStreamer->emitRawText("\t.end\t" + Twine(CurrentFnSym->getName()));
}
}
// .section .mdebug.abi32
// .previous
void Cpu0AsmPrinter::emitStartOfAsmFile(Module &M) {
// FIXME: Use SwitchSection.
// Tell the assembler which ABI we are using
if (OutStreamer->hasRawTextSupport())
OutStreamer->emitRawText("\t.section .mdebug." +
Twine(getCurrentABIString()));
// return to previous section
if (OutStreamer->hasRawTextSupport())
OutStreamer->emitRawText(StringRef("\t.previous"));
}
void Cpu0AsmPrinter::PrintDebugValueComment(const MachineInstr *MI,
raw_ostream &OS) {
// TODO: implement
OS << "PrintDebugValueComment()";
}
// Force static initialization.
extern "C" void LLVMInitializeCpu0AsmPrinter() {
RegisterAsmPrinter<Cpu0AsmPrinter> X(TheCpu0Target);
RegisterAsmPrinter<Cpu0AsmPrinter> Y(TheCpu0elTarget);
}
When an instruction is ready to be printed, the function Cpu0AsmPrinter::EmitInstruction() is triggered first. It then calls OutStreamer.EmitInstruction() to print the opcode and register names based on the information from Cpu0GenInstrInfo.inc and Cpu0GenRegisterInfo.inc. Both files are registered dynamically in LLVMInitializeCpu0TargetMC().
Note that Cpu0InstPrinter.cpp only prints the operands, while the opcode information comes from Cpu0InstrInfo.td.
Add the following code to Cpu0ISelLowering.cpp.
lbdex/chapters/Chapter3_2/Cpu0ISelLowering.cpp
Cpu0TargetLowering::
Cpu0TargetLowering(Cpu0TargetMachine &TM)
: TargetLowering(TM, new Cpu0TargetObjectFile()),
Subtarget(&TM.getSubtarget<Cpu0Subtarget>()) {
//- Set .align 2
// It will emit .align 2 later
setMinFunctionAlignment(2);
// must, computeRegisterProperties - Once all of the register classes are
// added, this allows us to compute derived properties we expose.
computeRegisterProperties();
}
Add the following code to Cpu0MachineFunction.h since Cpu0AsmPrinter.cpp will call getEmitNOAT().
lbdex/chapters/Chapter3_2/Cpu0MachineFunction.h
class Cpu0FunctionInfo : public MachineFunctionInfo {
public:
Cpu0FunctionInfo(MachineFunction& MF)
: ...
, EmitNOAT(false)
{}
...
bool getEmitNOAT() const { return EmitNOAT; }
void setEmitNOAT() { EmitNOAT = true; }
private:
...
bool EmitNOAT;
};
lbdex/chapters/Chapter3_2/CMakeLists.txt
tablegen(LLVM Cpu0GenCodeEmitter.inc -gen-emitter)
tablegen(LLVM Cpu0GenMCCodeEmitter.inc -gen-emitter)
tablegen(LLVM Cpu0GenAsmWriter.inc -gen-asm-writer)
...
add_llvm_target(Cpu0CodeGen
Cpu0AsmPrinter.cpp
Cpu0MCInstLower.cpp
LINK_COMPONENTS
...
Cpu0AsmPrinter
...
)
...
add_subdirectory(InstPrinter)
Now, run Chapter3_2/Cpu0 for AsmPrinter support, and you will get a new error message as follows,
118-165-78-230:input Jonathan$ /Users/Jonathan/llvm/test/build/
bin/llc -march=cpu0 -relocation-model=pic -filetype=asm ch3.bc -o
ch3.cpu0.s
/Users/Jonathan/llvm/test/build/bin/llc: target does not
support generation of this file type!
The llc fails to compile IR code into machine code
since we haven’t implemented the class Cpu0DAGToDAGISel.
Add Cpu0DAGToDAGISel class¶
The IR DAG to machine instruction DAG transformation was introduced in the previous chapter.
Now, let’s check what IR DAG nodes the file ch3.bc contains. List ch3.ll as follows:
// ch3.ll
define i32 @main() nounwind uwtable {
%1 = alloca i32, align 4
store i32 0, i32* %1
ret i32 0
}
As above, ch3.ll uses the IR DAG node store, ret. So, the definitions in Cpu0InstrInfo.td as below are enough. The ADDiu is used for stack adjustment, which will be needed in the later section “Add Prologue/Epilogue functions” of this chapter.
IR DAG is defined in the file include/llvm/Target/TargetSelectionDAG.td.
lbdex/chapters/Chapter2/Cpu0InstrInfo.td
//===----------------------------------------------------------------------===//
/// Load and Store Instructions
/// aligned
defm LD : LoadM32<0x01, "ld", load_a>;
defm ST : StoreM32<0x02, "st", store_a>;
/// Arithmetic Instructions (ALU Immediate)
// IR "add" defined in include/llvm/Target/TargetSelectionDAG.td, line 315 (def add).
def ADDiu : ArithLogicI<0x09, "addiu", add, simm16, immSExt16, CPURegs>;
let isReturn=1, isTerminator=1, hasDelaySlot=1, isBarrier=1, hasCtrlDep=1 in
def RetLR : Cpu0Pseudo<(outs), (ins), "", [(Cpu0Ret)]>;
def RET : RetBase<GPROut>;
Add class Cpu0DAGToDAGISel (Cpu0ISelDAGToDAG.cpp) to CMakeLists.txt, and add the following fragment to Cpu0TargetMachine.cpp,
lbdex/chapters/Chapter3_3/CMakeLists.txt
add_llvm_target(
...
Cpu0ISelDAGToDAG.cpp
Cpu0SEISelDAGToDAG.cpp
...
)
The following code in Cpu0TargetMachine.cpp will create a pass in the instruction selection stage.
lbdex/chapters/Chapter3_3/Cpu0TargetMachine.cpp
#include "Cpu0SEISelDAGToDAG.h"
...
class Cpu0PassConfig : public TargetPassConfig {
public:
...
bool addInstSelector() override;
};
...
// Install an instruction selector pass using
// the ISelDag to gen Cpu0 code.
bool Cpu0PassConfig::addInstSelector() {
addPass(createCpu0SEISelDag(getCpu0TargetMachine(), getOptLevel()));
return false;
}
lbdex/chapters/Chapter3_3/Cpu0ISelDAGToDAG.h
//===---- Cpu0ISelDAGToDAG.h - A Dag to Dag Inst Selector for Cpu0 --------===//
//
// The LLVM Compiler Infrastructure
//
// This file is distributed under the University of Illinois Open Source
// License. See LICENSE.TXT for details.
//
//===----------------------------------------------------------------------===//
//
// This file defines an instruction selector for the CPU0 target.
//
//===----------------------------------------------------------------------===//
#ifndef LLVM_LIB_TARGET_CPU0_CPU0ISELDAGTODAG_H
#define LLVM_LIB_TARGET_CPU0_CPU0ISELDAGTODAG_H
#include "Cpu0Config.h"
#include "Cpu0.h"
#include "Cpu0Subtarget.h"
#include "Cpu0TargetMachine.h"
#include "llvm/CodeGen/SelectionDAGISel.h"
#include "llvm/IR/Type.h"
#include "llvm/Support/Debug.h"
//===----------------------------------------------------------------------===//
// Instruction Selector Implementation
//===----------------------------------------------------------------------===//
//===----------------------------------------------------------------------===//
// Cpu0DAGToDAGISel - CPU0 specific code to select CPU0 machine
// instructions for SelectionDAG operations.
//===----------------------------------------------------------------------===//
namespace llvm {
class Cpu0DAGToDAGISel : public SelectionDAGISel {
public:
explicit Cpu0DAGToDAGISel(Cpu0TargetMachine &TM, CodeGenOpt::Level OL)
: SelectionDAGISel(TM, OL), Subtarget(nullptr) {}
// Pass Name
StringRef getPassName() const override {
return "CPU0 DAG->DAG Pattern Instruction Selection";
}
bool runOnMachineFunction(MachineFunction &MF) override;
protected:
/// Keep a pointer to the Cpu0Subtarget around so that we can make the right
/// decision when generating code for different targets.
const Cpu0Subtarget *Subtarget;
private:
// Include the pieces autogenerated from the target description.
#include "Cpu0GenDAGISel.inc"
/// getTargetMachine - Return a reference to the TargetMachine, casted
/// to the target-specific type.
const Cpu0TargetMachine &getTargetMachine() {
return static_cast<const Cpu0TargetMachine &>(TM);
}
void Select(SDNode *N) override;
virtual bool trySelect(SDNode *Node) = 0;
// Complex Pattern.
bool SelectAddr(SDNode *Parent, SDValue N, SDValue &Base, SDValue &Offset);
// getImm - Return a target constant with the specified value.
inline SDValue getImm(const SDNode *Node, unsigned Imm) {
return CurDAG->getTargetConstant(Imm, SDLoc(Node), Node->getValueType(0));
}
virtual void processFunctionAfterISel(MachineFunction &MF) = 0;
};
}
#endif
lbdex/chapters/Chapter3_3/Cpu0ISelDAGToDAG.cpp
//===-- Cpu0ISelDAGToDAG.cpp - A Dag to Dag Inst Selector for Cpu0 --------===//
//
// The LLVM Compiler Infrastructure
//
// This file is distributed under the University of Illinois Open Source
// License. See LICENSE.TXT for details.
//
//===----------------------------------------------------------------------===//
//
// This file defines an instruction selector for the CPU0 target.
//
//===----------------------------------------------------------------------===//
#include "Cpu0ISelDAGToDAG.h"
#include "Cpu0.h"
#include "Cpu0MachineFunction.h"
#include "Cpu0RegisterInfo.h"
#include "Cpu0SEISelDAGToDAG.h"
#include "Cpu0TargetMachine.h"
#include "llvm/CodeGen/MachineConstantPool.h"
#include "llvm/CodeGen/MachineFrameInfo.h"
#include "llvm/CodeGen/MachineFunction.h"
#include "llvm/CodeGen/MachineInstrBuilder.h"
#include "llvm/CodeGen/MachineRegisterInfo.h"
#include "llvm/CodeGen/SelectionDAGISel.h"
#include "llvm/CodeGen/SelectionDAGNodes.h"
#include "llvm/IR/CFG.h"
#include "llvm/IR/GlobalValue.h"
#include "llvm/IR/Instructions.h"
#include "llvm/IR/Intrinsics.h"
#include "llvm/IR/Type.h"
#include "llvm/Support/Debug.h"
#include "llvm/Support/ErrorHandling.h"
#include "llvm/Support/raw_ostream.h"
#include "llvm/Target/TargetMachine.h"
using namespace llvm;
#define DEBUG_TYPE "cpu0-isel"
//===----------------------------------------------------------------------===//
// Instruction Selector Implementation
//===----------------------------------------------------------------------===//
//===----------------------------------------------------------------------===//
// Cpu0DAGToDAGISel - CPU0 specific code to select CPU0 machine
// instructions for SelectionDAG operations.
//===----------------------------------------------------------------------===//
bool Cpu0DAGToDAGISel::runOnMachineFunction(MachineFunction &MF) {
bool Ret = SelectionDAGISel::runOnMachineFunction(MF);
return Ret;
}
//@SelectAddr {
/// ComplexPattern used on Cpu0InstrInfo
/// Used on Cpu0 Load/Store instructions
bool Cpu0DAGToDAGISel::
SelectAddr(SDNode *Parent, SDValue Addr, SDValue &Base, SDValue &Offset) {
//@SelectAddr }
EVT ValTy = Addr.getValueType();
SDLoc DL(Addr);
// If Parent is an unaligned f32 load or store, select a (base + index)
// floating point load/store instruction (luxc1 or suxc1).
const LSBaseSDNode* LS = 0;
if (Parent && (LS = dyn_cast<LSBaseSDNode>(Parent))) {
EVT VT = LS->getMemoryVT();
if (VT.getSizeInBits() / 8 > LS->getAlignment()) {
assert(0 && "Unaligned loads/stores not supported for this type.");
if (VT == MVT::f32)
return false;
}
}
// if Address is FI, get the TargetFrameIndex.
if (FrameIndexSDNode *FIN = dyn_cast<FrameIndexSDNode>(Addr)) {
Base = CurDAG->getTargetFrameIndex(FIN->getIndex(), ValTy);
Offset = CurDAG->getTargetConstant(0, DL, ValTy);
return true;
}
Base = Addr;
Offset = CurDAG->getTargetConstant(0, DL, ValTy);
return true;
}
//@Select {
/// Select instructions not customized! Used for
/// expanded, promoted and normal instructions
void Cpu0DAGToDAGISel::Select(SDNode *Node) {
//@Select }
unsigned Opcode = Node->getOpcode();
// If we have a custom node, we already have selected!
if (Node->isMachineOpcode()) {
LLVM_DEBUG(errs() << "== "; Node->dump(CurDAG); errs() << "\n");
Node->setNodeId(-1);
return;
}
// See if subclasses can handle this node.
if (trySelect(Node))
return;
switch(Opcode) {
default: break;
}
// Select the default instruction
SelectCode(Node);
}
lbdex/chapters/Chapter3_3/Cpu0SEISelDAGToDAG.h
//===-- Cpu0SEISelDAGToDAG.h - A Dag to Dag Inst Selector for Cpu0SE -----===//
//
// The LLVM Compiler Infrastructure
//
// This file is distributed under the University of Illinois Open Source
// License. See LICENSE.TXT for details.
//
//===----------------------------------------------------------------------===//
//
// Subclass of Cpu0DAGToDAGISel specialized for cpu032.
//
//===----------------------------------------------------------------------===//
#ifndef LLVM_LIB_TARGET_CPU0_CPU0SEISELDAGTODAG_H
#define LLVM_LIB_TARGET_CPU0_CPU0SEISELDAGTODAG_H
#include "Cpu0Config.h"
#include "Cpu0ISelDAGToDAG.h"
namespace llvm {
class Cpu0SEDAGToDAGISel : public Cpu0DAGToDAGISel {
public:
explicit Cpu0SEDAGToDAGISel(Cpu0TargetMachine &TM, CodeGenOpt::Level OL)
: Cpu0DAGToDAGISel(TM, OL) {}
private:
bool runOnMachineFunction(MachineFunction &MF) override;
bool trySelect(SDNode *Node) override;
void processFunctionAfterISel(MachineFunction &MF) override;
// Insert instructions to initialize the global base register in the
// first MBB of the function.
// void initGlobalBaseReg(MachineFunction &MF);
};
FunctionPass *createCpu0SEISelDag(Cpu0TargetMachine &TM,
CodeGenOpt::Level OptLevel);
}
#endif
lbdex/chapters/Chapter3_3/Cpu0ISelDAGToDAG.cpp
//===-- Cpu0SEISelDAGToDAG.cpp - A Dag to Dag Inst Selector for Cpu0SE ----===//
//
// The LLVM Compiler Infrastructure
//
// This file is distributed under the University of Illinois Open Source
// License. See LICENSE.TXT for details.
//
//===----------------------------------------------------------------------===//
//
// Subclass of Cpu0DAGToDAGISel specialized for cpu032.
//
//===----------------------------------------------------------------------===//
#include "Cpu0SEISelDAGToDAG.h"
#include "MCTargetDesc/Cpu0BaseInfo.h"
#include "Cpu0.h"
#include "Cpu0MachineFunction.h"
#include "Cpu0RegisterInfo.h"
#include "llvm/CodeGen/MachineConstantPool.h"
#include "llvm/CodeGen/MachineFrameInfo.h"
#include "llvm/CodeGen/MachineFunction.h"
#include "llvm/CodeGen/MachineInstrBuilder.h"
#include "llvm/CodeGen/MachineRegisterInfo.h"
#include "llvm/CodeGen/SelectionDAGNodes.h"
#include "llvm/IR/CFG.h"
#include "llvm/IR/GlobalValue.h"
#include "llvm/IR/Instructions.h"
#include "llvm/IR/Intrinsics.h"
#include "llvm/IR/Type.h"
#include "llvm/Support/Debug.h"
#include "llvm/Support/ErrorHandling.h"
#include "llvm/Support/raw_ostream.h"
#include "llvm/Target/TargetMachine.h"
using namespace llvm;
#define DEBUG_TYPE "cpu0-isel"
bool Cpu0SEDAGToDAGISel::runOnMachineFunction(MachineFunction &MF) {
Subtarget = &static_cast<const Cpu0Subtarget &>(MF.getSubtarget());
return Cpu0DAGToDAGISel::runOnMachineFunction(MF);
}
void Cpu0SEDAGToDAGISel::processFunctionAfterISel(MachineFunction &MF) {
}
//@selectNode
bool Cpu0SEDAGToDAGISel::trySelect(SDNode *Node) {
unsigned Opcode = Node->getOpcode();
SDLoc DL(Node);
///
// Instruction Selection not handled by the auto-generated
// tablegen selection should be handled here.
///
///
// Instruction Selection not handled by the auto-generated
// tablegen selection should be handled here.
///
EVT NodeTy = Node->getValueType(0);
unsigned MultOpc;
switch(Opcode) {
default: break;
}
return false;
}
FunctionPass *llvm::createCpu0SEISelDag(Cpu0TargetMachine &TM,
CodeGenOpt::Level OptLevel) {
return new Cpu0SEDAGToDAGISel(TM, OptLevel);
}
Function Cpu0DAGToDAGISel::Select() of Cpu0ISelDAGToDAG.cpp is for the selection of “OP code DAG node,” while Cpu0DAGToDAGISel::SelectAddr() is for the selection of “DATA DAG node with addr type,” which is defined in Chapter2/Cpu0InstrInfo.td. This method’s name corresponds to Chapter2/Cpu0InstrInfo.td as follows:
lbdex/chapters/Chapter2/Cpu0InstrInfo.td
def addr : ComplexPattern<iPTR, 2, "SelectAddr", [frameindex], [SDNPWantParent]>;
The iPTR, ComplexPattern, frameindex, and SDNPWantParent are defined as follows:
llvm/include/llvm/Target/TargetSelection.td
def SDNPWantParent : SDNodeProperty; // ComplexPattern gets the parent
...
def frameindex : SDNode<"ISD::FrameIndex", SDTPtrLeaf, [],
"FrameIndexSDNode">;
...
// Complex patterns, e.g. X86 addressing mode, requires pattern matching code
// in C++. NumOperands is the number of operands returned by the select function;
// SelectFunc is the name of the function used to pattern match the max. pattern;
// RootNodes are the list of possible root nodes of the sub-dags to match.
// e.g. X86 addressing mode - def addr : ComplexPattern<4, "SelectAddr", [add]>;
//
class ComplexPattern<ValueType ty, int numops, string fn,
list<SDNode> roots = [], list<SDNodeProperty> props = []> {
ValueType Ty = ty;
int NumOperands = numops;
string SelectFunc = fn;
list<SDNode> RootNodes = roots;
list<SDNodeProperty> Properties = props;
}
llvm/include/llvm/CodeGen/ValueTypes.td
// Pseudo valuetype mapped to the current pointer size.
def iPTR : ValueType<0 , 255>;
Build Chapter3_3 and run it. The error message from Chapter3_2 is gone. The new error message for Chapter3_3 is as follows:
118-165-78-230:input Jonathan$ /Users/Jonathan/llvm/test/build/
bin/llc -march=cpu0 -relocation-model=pic -filetype=asm ch3.bc -o
ch3.cpu0.s
...
LLVM ERROR: Cannot select: t6: ch = Cpu0ISD::Ret t4, Register:i32 $lr
t5: i32 = Register $lr
...
The above can display the error message for the DAG node “Cpu0ISD::Ret” because the following code was added in Chapter3_1/Cpu0ISelLowering.cpp.
lbdex/chapters/Chapter3_1/Cpu0ISelLowering.cpp
const char *Cpu0TargetLowering::getTargetNodeName(unsigned Opcode) const {
switch (Opcode) {
case Cpu0ISD::JmpLink: return "Cpu0ISD::JmpLink";
case Cpu0ISD::TailCall: return "Cpu0ISD::TailCall";
case Cpu0ISD::Hi: return "Cpu0ISD::Hi";
case Cpu0ISD::Lo: return "Cpu0ISD::Lo";
case Cpu0ISD::GPRel: return "Cpu0ISD::GPRel";
case Cpu0ISD::Ret: return "Cpu0ISD::Ret";
case Cpu0ISD::EH_RETURN: return "Cpu0ISD::EH_RETURN";
case Cpu0ISD::DivRem: return "Cpu0ISD::DivRem";
case Cpu0ISD::DivRemU: return "Cpu0ISD::DivRemU";
case Cpu0ISD::Wrapper: return "Cpu0ISD::Wrapper";
default: return NULL;
}
}
Handle return register $lr¶
The following code is the result of running the Mips backend with ch3.cpp.
JonathantekiiMac:input Jonathan$ ~/llvm/debug/build/bin/llc
-march=mips -relocation-model=pic -filetype=asm ch3.bc -o -
.text
.abicalls
.section .mdebug.abi32,"",@progbits
.nan legacy
.file "ch3.bc"
.text
.globl main
.align 2
.type main,@function
.set nomicromips
.set nomips16
.ent main
main: # @main
.frame $fp,8,$ra
.mask 0x40000000,-4
.fmask 0x00000000,0
.set noreorder
.set nomacro
.set noat
# BB#0:
addiu $sp, $sp, -8
sw $fp, 4($sp) # 4-byte Folded Spill
move $fp, $sp
sw $zero, 0($fp)
addiu $2, $zero, 0
move $sp, $fp
lw $fp, 4($sp) # 4-byte Folded Reload
jr $ra
addiu $sp, $sp, 8
.set at
.set macro
.set reorder
.end main
$func_end0:
.size main, ($func_end0)-main
As you can see, Mips returns to the caller by using “jr $ra”, where $ra is a specific register that holds the caller’s next instruction address. It also stores the return value in register $2.
If we only create DAGs directly, we encounter the following two problems:
LLVM can allocate any register for the return value, such as $3, rather than keeping it in $2.
LLVM may randomly allocate a register for “jr” since “jr” requires one operand. For example, it might generate “jr $8” instead of “jr $ra”.
If the backend strictly uses the “jal sub-routine” and “jr” while always storing the return address in the specific register $ra, the second problem does not occur. However, in Mips, programmers are allowed to use “jal $rx, sub-routine” and “jr $rx”, where $rx is not necessarily $ra.
Allowing programmers to use registers other than $ra provides more flexibility for high-level languages such as C when integrating assembly.
The following file, ch8_2_longbranch.cpp, demonstrates this concept. It uses “jr $1” without spilling the $ra register. This optimization can significantly improve performance, especially in hot functions.
lbdex/input/ch8_2_longbranch.cpp
int test_longbranch()
{
volatile int a = 2;
volatile int b = 1;
int result = 0;
if (a < b)
result = 1;
return result;
}
JonathantekiiMac:input Jonathan$ clang -target mips-unknown-linux-gnu -c
ch8_2_longbranch.cpp -emit-llvm -o ch8_2_longbranch.bc
JonathantekiiMac:input Jonathan$ ~/llvm/debug/build/bin/llc
-march=mips -relocation-model=pic -filetype=asm -force-mips-long-branch
ch8_2_longbranch.bc -o -
...
.ent _Z15test_longbranchv
_Z15test_longbranchv: # @_Z15test_longbranchv
.frame $fp,16,$ra
.mask 0x40000000,-4
.fmask 0x00000000,0
.set noreorder
.set nomacro
.set noat
# BB#0:
addiu $sp, $sp, -16
sw $fp, 12($sp) # 4-byte Folded Spill
move $fp, $sp
addiu $1, $zero, 2
sw $1, 8($fp)
addiu $2, $zero, 1
sw $2, 4($fp)
sw $zero, 0($fp)
lw $1, 8($fp)
lw $3, 4($fp)
slt $1, $1, $3
bnez $1, $BB0_3
nop
# BB#1:
addiu $sp, $sp, -8
sw $ra, 0($sp)
lui $1, %hi(($BB0_4)-($BB0_2))
bal $BB0_2
addiu $1, $1, %lo(($BB0_4)-($BB0_2))
$BB0_2:
addu $1, $ra, $1
lw $ra, 0($sp)
jr $1
addiu $sp, $sp, 8
$BB0_3:
sw $2, 0($fp)
$BB0_4:
lw $2, 0($fp)
move $sp, $fp
lw $fp, 12($sp) # 4-byte Folded Reload
jr $ra
addiu $sp, $sp, 16
.set at
.set macro
.set reorder
.end _Z15test_longbranchv
$func_end0:
.size _Z15test_longbranchv, ($func_end0)-_Z15test_longbranchv
The following code handles the return register $lr.
lbdex/chapters/Chapter3_4/Cpu0CallingConv.td
def RetCC_Cpu0EABI : CallingConv<[
// i32 are returned in registers V0, V1, A0, A1
CCIfType<[i32], CCAssignToReg<[V0, V1, A0, A1]>>
]>;
def RetCC_Cpu0 : CallingConv<[
CCDelegateTo<RetCC_Cpu0EABI>
]>;
lbdex/chapters/Chapter3_4/Cpu0InstrFormats.td
// Cpu0 Pseudo Instructions Format
class Cpu0Pseudo<dag outs, dag ins, string asmstr, list<dag> pattern>:
Cpu0Inst<outs, ins, asmstr, pattern, IIPseudo, Pseudo> {
let isCodeGenOnly = 1;
let isPseudo = 1;
}
lbdex/chapters/Chapter3_4/Cpu0InstrInfo.td
let Predicates = [Ch3_4] in {
let isReturn=1, isTerminator=1, hasDelaySlot=1, isBarrier=1, hasCtrlDep=1 in
def RetLR : Cpu0Pseudo<(outs), (ins), "", [(Cpu0Ret)]>;
}
lbdex/chapters/Chapter3_4/Cpu0ISelLowering.h
/// Cpu0CC - This class provides methods used to analyze formal and call
/// arguments and inquire about calling convention information.
class Cpu0CC {
public:
enum SpecialCallingConvType {
NoSpecialCallingConv
};
Cpu0CC(CallingConv::ID CallConv, bool IsO32, CCState &Info,
SpecialCallingConvType SpecialCallingConv = NoSpecialCallingConv);
void analyzeCallResult(const SmallVectorImpl<ISD::InputArg> &Ins,
bool IsSoftFloat, const SDNode *CallNode,
const Type *RetTy) const;
void analyzeReturn(const SmallVectorImpl<ISD::OutputArg> &Outs,
bool IsSoftFloat, const Type *RetTy) const;
const CCState &getCCInfo() const { return CCInfo; }
/// hasByValArg - Returns true if function has byval arguments.
bool hasByValArg() const { return !ByValArgs.empty(); }
/// reservedArgArea - The size of the area the caller reserves for
/// register arguments. This is 16-byte if ABI is O32.
unsigned reservedArgArea() const;
typedef SmallVectorImpl<ByValArgInfo>::const_iterator byval_iterator;
byval_iterator byval_begin() const { return ByValArgs.begin(); }
byval_iterator byval_end() const { return ByValArgs.end(); }
private:
/// Return the type of the register which is used to pass an argument or
/// return a value. This function returns f64 if the argument is an i64
/// value which has been generated as a result of softening an f128 value.
/// Otherwise, it just returns VT.
MVT getRegVT(MVT VT, bool IsSoftFloat) const;
template<typename Ty>
void analyzeReturn(const SmallVectorImpl<Ty> &RetVals, bool IsSoftFloat,
const SDNode *CallNode, const Type *RetTy) const;
CCState &CCInfo;
CallingConv::ID CallConv;
bool IsO32;
SmallVector<ByValArgInfo, 2> ByValArgs;
};
lbdex/chapters/Chapter3_4/Cpu0ISelLowering.cpp
SDValue
Cpu0TargetLowering::LowerReturn(SDValue Chain,
CallingConv::ID CallConv, bool IsVarArg,
const SmallVectorImpl<ISD::OutputArg> &Outs,
const SmallVectorImpl<SDValue> &OutVals,
const SDLoc &DL, SelectionDAG &DAG) const {
// CCValAssign - represent the assignment of
// the return value to a location
SmallVector<CCValAssign, 16> RVLocs;
MachineFunction &MF = DAG.getMachineFunction();
// CCState - Info about the registers and stack slot.
CCState CCInfo(CallConv, IsVarArg, MF, RVLocs,
*DAG.getContext());
Cpu0CC Cpu0CCInfo(CallConv, ABI.IsO32(),
CCInfo);
// Analyze return values.
Cpu0CCInfo.analyzeReturn(Outs, Subtarget.abiUsesSoftFloat(),
MF.getFunction().getReturnType());
SDValue Flag;
SmallVector<SDValue, 4> RetOps(1, Chain);
// Copy the result values into the output registers.
for (unsigned i = 0; i != RVLocs.size(); ++i) {
SDValue Val = OutVals[i];
CCValAssign &VA = RVLocs[i];
assert(VA.isRegLoc() && "Can only return in registers!");
if (RVLocs[i].getValVT() != RVLocs[i].getLocVT())
Val = DAG.getNode(ISD::BITCAST, DL, RVLocs[i].getLocVT(), Val);
Chain = DAG.getCopyToReg(Chain, DL, VA.getLocReg(), Val, Flag);
// Guarantee that all emitted copies are stuck together with flags.
Flag = Chain.getValue(1);
RetOps.push_back(DAG.getRegister(VA.getLocReg(), VA.getLocVT()));
}
//@Ordinary struct type: 2 {
// The cpu0 ABIs for returning structs by value requires that we copy
// the sret argument into $v0 for the return. We saved the argument into
// a virtual register in the entry block, so now we copy the value out
// and into $v0.
if (MF.getFunction().hasStructRetAttr()) {
Cpu0FunctionInfo *Cpu0FI = MF.getInfo<Cpu0FunctionInfo>();
unsigned Reg = Cpu0FI->getSRetReturnReg();
if (!Reg)
llvm_unreachable("sret virtual register not created in the entry block");
SDValue Val =
DAG.getCopyFromReg(Chain, DL, Reg, getPointerTy(DAG.getDataLayout()));
unsigned V0 = Cpu0::V0;
Chain = DAG.getCopyToReg(Chain, DL, V0, Val, Flag);
Flag = Chain.getValue(1);
RetOps.push_back(DAG.getRegister(V0, getPointerTy(DAG.getDataLayout())));
}
//@Ordinary struct type: 2 }
RetOps[0] = Chain; // Update chain.
// Add the flag if we have it.
if (Flag.getNode())
RetOps.push_back(Flag);
// Return on Cpu0 is always a "ret $lr"
return DAG.getNode(Cpu0ISD::Ret, DL, MVT::Other, RetOps);
}
template<typename Ty>
void Cpu0TargetLowering::Cpu0CC::
analyzeReturn(const SmallVectorImpl<Ty> &RetVals, bool IsSoftFloat,
const SDNode *CallNode, const Type *RetTy) const {
CCAssignFn *Fn;
Fn = RetCC_Cpu0;
for (unsigned I = 0, E = RetVals.size(); I < E; ++I) {
MVT VT = RetVals[I].VT;
ISD::ArgFlagsTy Flags = RetVals[I].Flags;
MVT RegVT = this->getRegVT(VT, IsSoftFloat);
if (Fn(I, VT, RegVT, CCValAssign::Full, Flags, this->CCInfo)) {
#ifndef NDEBUG
dbgs() << "Call result #" << I << " has unhandled type "
<< EVT(VT).getEVTString() << '\n';
#endif
llvm_unreachable(nullptr);
}
}
}
void Cpu0TargetLowering::Cpu0CC::
analyzeCallResult(const SmallVectorImpl<ISD::InputArg> &Ins, bool IsSoftFloat,
const SDNode *CallNode, const Type *RetTy) const {
analyzeReturn(Ins, IsSoftFloat, CallNode, RetTy);
}
void Cpu0TargetLowering::Cpu0CC::
analyzeReturn(const SmallVectorImpl<ISD::OutputArg> &Outs, bool IsSoftFloat,
const Type *RetTy) const {
analyzeReturn(Outs, IsSoftFloat, nullptr, RetTy);
}
unsigned Cpu0TargetLowering::Cpu0CC::reservedArgArea() const {
return (IsO32 && (CallConv != CallingConv::Fast)) ? 8 : 0;
}
MVT Cpu0TargetLowering::Cpu0CC::getRegVT(MVT VT,
bool IsSoftFloat) const {
if (IsSoftFloat || IsO32)
return VT;
return VT;
}
lbdex/chapters/Chapter3_4/Cpu0MachineFunction.h
/// Cpu0FunctionInfo - This class is derived from MachineFunction private
/// Cpu0 target-specific information for each MachineFunction.
class Cpu0FunctionInfo : public MachineFunctionInfo {
SRetReturnReg(0), CallsEhReturn(false), CallsEhDwarf(false),
unsigned getSRetReturnReg() const { return SRetReturnReg; }
void setSRetReturnReg(unsigned Reg) { SRetReturnReg = Reg; }
bool hasByvalArg() const { return HasByvalArg; }
void setFormalArgInfo(unsigned Size, bool HasByval) {
IncomingArgSize = Size;
HasByvalArg = HasByval;
}
/// SRetReturnReg - Some subtargets require that sret lowering includes
/// returning the value of the returned struct in a register. This field
/// holds the virtual register into which the sret argument is passed.
unsigned SRetReturnReg;
/// True if function has a byval argument.
bool HasByvalArg;
/// Size of incoming argument area.
unsigned IncomingArgSize;
/// CallsEhReturn - Whether the function calls llvm.eh.return.
bool CallsEhReturn;
/// CallsEhDwarf - Whether the function calls llvm.eh.dwarf.
bool CallsEhDwarf;
/// Frame objects for spilling eh data registers.
int EhDataRegFI[2];
}
lbdex/chapters/Chapter3_4/Cpu0SEInstrInfo.h
//@expandPostRAPseudo
bool expandPostRAPseudo(MachineInstr &MI) const override;
private:
void expandRetLR(MachineBasicBlock &MBB, MachineBasicBlock::iterator I) const;
lbdex/chapters/Chapter3_4/Cpu0SEInstrInfo.cpp
//@expandPostRAPseudo
/// Expand Pseudo instructions into real backend instructions
bool Cpu0SEInstrInfo::expandPostRAPseudo(MachineInstr &MI) const {
//@expandPostRAPseudo-body
MachineBasicBlock &MBB = *MI.getParent();
switch (MI.getDesc().getOpcode()) {
default:
return false;
case Cpu0::RetLR:
expandRetLR(MBB, MI);
break;
}
MBB.erase(MI);
return true;
}
void Cpu0SEInstrInfo::expandRetLR(MachineBasicBlock &MBB,
MachineBasicBlock::iterator I) const {
BuildMI(MBB, I, I->getDebugLoc(), get(Cpu0::RET)).addReg(Cpu0::LR);
}
Build Chapter3_4 and run with it, finding the error message in Chapter3_3 is gone. The compilation result will hang, and please press “Ctrl+C” to abort as follows,
118-165-78-230:input Jonathan$ clang -target mips-unknown-linux-gnu -c
ch3.cpp -emit-llvm -o ch3.bc
118-165-78-230:input Jonathan$ ~/llvm/test/build/bin/llvm-dis
ch3.bc -o -
...
define i32 @main() #0 {
%1 = alloca i32, align 4
store i32 0, i32* %1
ret i32 0
}
118-165-78-230:input Jonathan$ /Users/Jonathan/llvm/test/build/
bin/llc -march=cpu0 -relocation-model=pic -filetype=asm ch3.bc -o -
...
.text
.section .mdebug.abiO32
.previous
.file "ch3.bc"
^C
It hangs because the Cpu0 backend has not handled stack slots for local variables. The instruction “store i32 0, i32* %1” in the above IR requires Cpu0 to allocate a stack slot and save to it.
However, ch3.cpp can be run with the option clang -O2 as follows,
118-165-78-230:input Jonathan$ clang -O2 -target mips-unknown-linux-gnu -c
ch3.cpp -emit-llvm -o ch3.bc
118-165-78-230:input Jonathan$ ~/llvm/test/build/bin/llvm-dis
ch3.bc -o -
...
define i32 @main() #0 {
ret i32 0
}
118-165-78-230:input Jonathan$ /Users/Jonathan/llvm/test/build/
bin/llc -march=cpu0 -relocation-model=pic -filetype=asm ch3.bc -o -
.text
.section .mdebug.abiO32
.previous
.file "ch3.bc"
.globl main
.align 2
.type main,@function
.ent main # @main
main:
.frame $sp,0,$lr
.mask 0x00000000,0
.set noreorder
.set nomacro
# BB#0:
addiu $2, $zero, 0
ret $lr
.set macro
.set reorder
.end main
$func_end0:
.size main, ($func_end0)-main
To see how the ‘DAG->DAG Pattern Instruction Selection’ works in llc,
let’s compile with the option llc -print-before-all -print-after-all and
get the following result.
The DAGs before and after the instruction selection stage are shown below,
118-165-78-230:input Jonathan$ clang -O2 -target mips-unknown-linux-gnu -c
ch3.cpp -emit-llvm -o ch3.bc
118-165-78-12:input Jonathan$ /Users/Jonathan/llvm/test/build/
bin/llc -march=cpu0 -relocation-model=pic -filetype=asm
-print-before-all -print-after-all ch3.bc -o -
...
*** IR Dump After Module Verifier ***
; Function Attrs: nounwind readnone
define i32 @main() #0 {
ret i32 0
}
...
Initial selection DAG: BB#0 'main:'
SelectionDAG has 5 nodes:
t0: ch = EntryToken
t3: ch,glue = CopyToReg t0, Register:i32 %V0, Constant:i32<0>
t4: ch = Cpu0ISD::Ret t3, Register:i32 %V0, t3:1
...
===== Instruction selection begins: BB#0 ''
Selecting: t4: ch = Cpu0ISD::Ret t3, Register:i32 %V0, t3:1
ISEL: Starting pattern match on root node: t4: ch = Cpu0ISD::Ret t3, Register:i32 %V0, t3:1
Morphed node: t4: ch = RetLR Register:i32 %V0, t3, t3:1
ISEL: Match complete!
Selecting: t3: ch,glue = CopyToReg t0, Register:i32 %V0, Constant:i32<0>
Selecting: t2: i32 = Register %V0
Selecting: t1: i32 = Constant<0>
ISEL: Starting pattern match on root node: t1: i32 = Constant<0>
Initial Opcode index to 3158
Morphed node: t1: i32 = ADDiu Register:i32 %ZERO, TargetConstant:i32<0>
ISEL: Match complete!
Selecting: t0: ch = EntryToken
===== Instruction selection ends:
Selected selection DAG: BB#0 'main:'
SelectionDAG has 7 nodes:
t0: ch = EntryToken
t1: i32 = ADDiu Register:i32 %ZERO, TargetConstant:i32<0>
t3: ch,glue = CopyToReg t0, Register:i32 %V0, t1
t4: ch = RetLR Register:i32 %V0, t3, t3:1
...
********** REWRITE VIRTUAL REGISTERS **********
********** Function: main
********** REGISTER MAP **********
[%vreg0 -> %V0] GPROut
0B BB#0: derived from LLVM BB %0
16B %vreg0<def> = ADDiu %ZERO, 0; GPROut:%vreg0
32B %V0<def> = COPY %vreg0<kill>; GPROut:%vreg0
48B RetLR %V0<imp-use>
> %V0<def> = ADDiu %ZERO, 0
> %V0<def> = COPY %V0<kill>
Identity copy: %V0<def> = COPY %V0<kill>
deleted.
> RetLR %V0<imp-use>
# *** IR Dump After Virtual Register Rewriter ***:
# Machine code for function main: Properties: <Post SSA, tracking liveness, AllVRegsAllocated>
0B BB#0: derived from LLVM BB %0
16B %V0<def> = ADDiu %ZERO, 0
48B RetLR %V0<imp-use>
...
********** EXPANDING POST-RA PSEUDO INSTRS **********
********** Function: main
# *** IR Dump After Post-RA pseudo instruction expansion pass ***:
# Machine code for function main: Properties: <Post SSA, tracking liveness, AllVRegsAllocated>
BB#0: derived from LLVM BB %0
%V0<def> = ADDiu %ZERO, 0
RET %LR
...
.globl main
.p2align 2
.type main,@function
.ent main # @main
main:
.frame $sp,0,$lr
.mask 0x00000000,0
.set noreorder
.set nomacro
# BB#0:
addiu $2, $zero, 0
ret $lr
.set macro
.set reorder
.end main
$func_end0:
.size main, ($func_end0)-main
.ident "Apple LLVM version 7.0.0 (clang-700.1.76)"
.section ".note.GNU-stack","",@progbits
Summary above translation into Table: Chapter 3 .bc IR instructions.
.bc |
Lower |
ISel |
RVR |
Post-RA |
AsmP |
|---|---|---|---|---|---|
constant 0 |
constant 0 |
ADDiu |
ADDiu |
ADDiu |
addiu |
ret |
Cpu0ISD::Ret |
CopyToReg,RetLR |
RetLR |
RET |
ret |
Lower: Initial selection DAG (Cpu0ISelLowering.cpp, LowerReturn(…))
ISel: Instruction selection
RVR: REWRITE VIRTUAL REGISTERS, remove CopyToReg
AsmP: Cpu0 Asm Printer
Post-RA: Post-RA pseudo instruction expansion pass
From the above llc -print-before-all -print-after-all display, we observe
that ret is translated into Cpu0ISD::Ret in the stage of Optimized
Legalized Selection DAG, and then finally translated into the Cpu0 instruction
ret.
Since ret uses constant 0 (ret i32 0 in this example), the constant 0 is translated into “addiu $2, $zero, 0” via the following pattern defined in Cpu0InstrInfo.td.
lbdex/chapters/Chapter2/Cpu0InstrInfo.td
// Small immediates
def : Pat<(i32 immSExt16:$in),
(ADDiu ZERO, imm:$in)>;
In order to handle the IR ret, the following codes in Cpu0InstrInfo.td perform the following tasks:
Declare a pseudo node Cpu0::RetLR to handle the IR Cpu0ISD::Ret with the following code:
lbdex/chapters/Chapter3_4/Cpu0InstrInfo.td
// Return
def Cpu0Ret : SDNode<"Cpu0ISD::Ret", SDTNone,
[SDNPHasChain, SDNPOptInGlue, SDNPVariadic]>;
let Predicates = [Ch3_4] in {
let isReturn=1, isTerminator=1, hasDelaySlot=1, isBarrier=1, hasCtrlDep=1 in
def RetLR : Cpu0Pseudo<(outs), (ins), "", [(Cpu0Ret)]>;
}
Create the Cpu0ISD::Ret node in LowerReturn() of Cpu0ISelLowering.cpp, which is called when encountering the return keyword in C. Reminder: In LowerReturn(), the return value is placed in register $2 ($v0).
If we use the following code in Cpu0, then V0 won’t live out.
lbdex/chapters/Chapter3_4/Cpu0ISelLowering.cpp
SDValue
Cpu0TargetLowering::LowerReturn(SDValue Chain,
CallingConv::ID CallConv, bool IsVarArg,
const SmallVectorImpl<ISD::OutputArg> &Outs,
const SmallVectorImpl<SDValue> &OutVals,
const SDLoc &DL, SelectionDAG &DAG) const {
return DAG.getNode(Cpu0ISD::Ret, DL, MVT::Other,
Chain, DAG.getRegister(Cpu0::LR, MVT::i32));
}
After instruction selection, the Cpu0ISD::Ret node is replaced by Cpu0::RetLR as shown below. This effect comes from the “def RetLR” declaration in step 1.
===== Instruction selection begins: BB#0 'entry'
Selecting: 0x1ea4050: ch = Cpu0ISD::Ret 0x1ea3f50, 0x1ea3e50,
0x1ea3f50:1 [ID=27]
ISEL: Starting pattern match on root node: 0x1ea4050: ch = Cpu0ISD::Ret
0x1ea3f50, 0x1ea3e50, 0x1ea3f50:1 [ID=27]
Morphed node: 0x1ea4050: ch = RetLR 0x1ea3e50, 0x1ea3f50, 0x1ea3f50:1
...
ISEL: Match complete!
=> 0x1ea4050: ch = RetLR 0x1ea3e50, 0x1ea3f50, 0x1ea3f50:1
...
===== Instruction selection ends:
Selected selection DAG: BB#0 'main:entry'
SelectionDAG has 28 nodes:
...
0x1ea3e50: <multiple use>
0x1ea3f50: <multiple use>
0x1ea3f50: <multiple use>
0x1ea4050: ch = RetLR 0x1ea3e50, 0x1ea3f50, 0x1ea3f50:1
Expand the Cpu0ISD::RetLR into the instruction Cpu0::RET $lr during the “Post-RA pseudo instruction expansion pass” stage using the code in Chapter3_4/Cpu0SEInstrInfo.cpp as mentioned above. This stage occurs after register allocation, so we can replace V0 ($r2) with LR ($lr) without any side effects.
Print assembly or object code based on the information from .inc files generated by TableGen from .td files during the “Cpu0 Assembly Print” stage.
lbdex/chapters/Chapter2/Cpu0InstrInfo.td
//@JumpFR {
let isBranch=1, isTerminator=1, isBarrier=1, imm16=0, hasDelaySlot = 1,
isIndirectBranch = 1 in
class JumpFR<bits<8> op, string instr_asm, RegisterClass RC>:
FL<op, (outs), (ins RC:$ra),
!strconcat(instr_asm, "\t$ra"), [(brind RC:$ra)], IIBranch> {
let rb = 0;
let imm16 = 0;
}
def RET : RetBase<GPROut>;
Stage |
Function |
|---|---|
Write Code |
Declare a pseudo node Cpu0::RetLR |
for IR Cpu0::Ret; |
|
Before CPU0 DAG->DAG Pattern Instruction Selection |
Create Cpu0ISD::Ret DAG |
Instruction selection |
Cpu0::Ret is replaced by Cpu0::RetLR |
Post-RA pseudo instruction expansion pass |
Cpu0::RetLR -> Cpu0::RET $lr |
Cpu0 Assembly Printer |
Print according “def RET” |
The function LowerReturn() in Cpu0ISelLowering.cpp correctly handles the return variable.
In Chapter3_4/Cpu0ISelLowering.cpp, the function LowerReturn() creates the Cpu0ISD::Ret node, which is called by the LLVM system when it encounters the return keyword in C.
More specifically, it constructs the DAG as follows:
Cpu0ISD::Ret (CopyToReg %X, %V0, %Y), %V0, Flag
Add Prologue/Epilogue functions¶
Concept¶
Following come from tricore_llvm.pdf section “4.4.2 Non-static Register Information ”.
For some target architectures, some aspects of the target architecture’s register set are dependent upon variable factors and have to be determined at runtime. As a consequence, they cannot be generated statically from a TableGen description – although that would be possible for the bulk of them in the case of the TriCore backend. Among them are the following points:
Callee-saved registers. Normally, the ABI specifies a set of registers that a function must save on entry and restore on return if their contents are possibly modified during execution.
Reserved registers. Although the set of unavailable registers is already defined in the TableGen file, TriCoreRegisterInfo contains a method that marks all non-allocatable register numbers in a bit vector.
The following methods are implemented:
emitPrologue() inserts prologue code at the beginning of a function. Thanks to TriCore’s context model, this is a trivial task as it is not required to save any registers manually. The only thing that has to be done is reserving space for the function’s stack frame by decrementing the stack pointer. In addition, if the function needs a frame pointer, the frame register %a14 is set to the old value of the stack pointer beforehand.
emitEpilogue() is intended to emit instructions to destroy the stack frame and restore all previously saved registers before returning from a function. However, as %a10 (stack pointer), %a11 (return address), and %a14 (frame pointer, if any) are all part of the upper context, no epilogue code is needed at all. All cleanup operations are performed implicitly by the ret instruction.
eliminateFrameIndex() is called for each instruction that references a word of data in a stack slot. All previous passes of the code generator have been addressing stack slots through an abstract frame index and an immediate offset. The purpose of this function is to translate such a reference into a register–offset pair. Depending on whether the machine function that contains the instruction has a fixed or a variable stack frame, either the stack pointer %a10 or the frame pointer %a14 is used as the base register. The offset is computed accordingly. Fig. 25 demonstrates for both cases how a stack slot is addressed.
If the addressing mode of the affected instruction cannot handle the address because the offset is too large (the offset field has 10 bits for the BO addressing mode and 16 bits for the BOL mode), a sequence of instructions is emitted that explicitly computes the effective address. Interim results are put into an unused address register. If none is available, an already occupied address register is scavenged. For this purpose, LLVM’s framework offers a class named RegScavenger that takes care of all the details.
Fig. 25 Addressing of a variable a located on the stack. If the stack frame has a variable size, slot must be addressed relative to the frame pointer¶
Prologue and Epilogue functions¶
The Prologue and Epilogue functions as follows,
lbdex/chapters/Chapter3_5/Cpu0SEFrameLowering.cpp
void Cpu0SEFrameLowering::emitPrologue(MachineFunction &MF,
MachineBasicBlock &MBB) const {
MachineFrameInfo &MFI = MF.getFrameInfo();
Cpu0FunctionInfo *Cpu0FI = MF.getInfo<Cpu0FunctionInfo>();
const Cpu0SEInstrInfo &TII =
*static_cast<const Cpu0SEInstrInfo*>(STI.getInstrInfo());
const Cpu0RegisterInfo &RegInfo =
*static_cast<const Cpu0RegisterInfo *>(STI.getRegisterInfo());
MachineBasicBlock::iterator MBBI = MBB.begin();
DebugLoc dl = MBBI != MBB.end() ? MBBI->getDebugLoc() : DebugLoc();
Cpu0ABIInfo ABI = STI.getABI();
unsigned SP = Cpu0::SP;
const TargetRegisterClass *RC = &Cpu0::GPROutRegClass;
// First, compute final stack size.
uint64_t StackSize = MFI.getStackSize();
// No need to allocate space on the stack.
if (StackSize == 0 && !MFI.adjustsStack()) return;
MachineModuleInfo &MMI = MF.getMMI();
const MCRegisterInfo *MRI = MMI.getContext().getRegisterInfo();
// Adjust stack.
TII.adjustStackPtr(SP, -StackSize, MBB, MBBI);
// emit ".cfi_def_cfa_offset StackSize"
unsigned CFIIndex =
MF.addFrameInst(
MCCFIInstruction::cfiDefCfaOffset(nullptr, StackSize));
BuildMI(MBB, MBBI, dl, TII.get(TargetOpcode::CFI_INSTRUCTION))
.addCFIIndex(CFIIndex);
const std::vector<CalleeSavedInfo> &CSI = MFI.getCalleeSavedInfo();
if (!CSI.empty()) {
// Find the instruction past the last instruction that saves a callee-saved
// register to the stack.
for (unsigned i = 0; i < CSI.size(); ++i)
++MBBI;
// Iterate over list of callee-saved registers and emit .cfi_offset
// directives.
for (std::vector<CalleeSavedInfo>::const_iterator I = CSI.begin(),
E = CSI.end(); I != E; ++I) {
int64_t Offset = MFI.getObjectOffset(I->getFrameIdx());
unsigned Reg = I->getReg();
{
// Reg is in CPURegs.
unsigned CFIIndex = MF.addFrameInst(MCCFIInstruction::createOffset(
nullptr, MRI->getDwarfRegNum(Reg, true), Offset));
BuildMI(MBB, MBBI, dl, TII.get(TargetOpcode::CFI_INSTRUCTION))
.addCFIIndex(CFIIndex);
}
}
}
}
void Cpu0SEFrameLowering::emitEpilogue(MachineFunction &MF,
MachineBasicBlock &MBB) const {
MachineBasicBlock::iterator MBBI = MBB.getFirstTerminator();
MachineFrameInfo &MFI = MF.getFrameInfo();
Cpu0FunctionInfo *Cpu0FI = MF.getInfo<Cpu0FunctionInfo>();
const Cpu0SEInstrInfo &TII =
*static_cast<const Cpu0SEInstrInfo *>(STI.getInstrInfo());
const Cpu0RegisterInfo &RegInfo =
*static_cast<const Cpu0RegisterInfo *>(STI.getRegisterInfo());
DebugLoc DL = MBBI != MBB.end() ? MBBI->getDebugLoc() : DebugLoc();
Cpu0ABIInfo ABI = STI.getABI();
unsigned SP = Cpu0::SP;
// Get the number of bytes from FrameInfo
uint64_t StackSize = MFI.getStackSize();
if (!StackSize)
return;
// Adjust stack.
TII.adjustStackPtr(SP, StackSize, MBB, MBBI);
}
bool
Cpu0SEFrameLowering::hasReservedCallFrame(const MachineFunction &MF) const {
const MachineFrameInfo &MFI = MF.getFrameInfo();
// Reserve call frame if the size of the maximum call frame fits into 16-bit
// immediate field and there are no variable sized objects on the stack.
// Make sure the second register scavenger spill slot can be accessed with one
// instruction.
return isInt<16>(MFI.getMaxCallFrameSize() + getStackAlignment()) &&
!MFI.hasVarSizedObjects();
}
lbdex/chapters/Chapter3_5/Cpu0MachineFunction.h
unsigned getIncomingArgSize() const { return IncomingArgSize; }
bool callsEhReturn() const { return CallsEhReturn; }
void setCallsEhReturn() { CallsEhReturn = true; }
bool callsEhDwarf() const { return CallsEhDwarf; }
void setCallsEhDwarf() { CallsEhDwarf = true; }
void createEhDataRegsFI();
int getEhDataRegFI(unsigned Reg) const { return EhDataRegFI[Reg]; }
unsigned getMaxCallFrameSize() const { return MaxCallFrameSize; }
void setMaxCallFrameSize(unsigned S) { MaxCallFrameSize = S; }
Now, we further explain the Prologue and Epilogue with an example.
For the following LLVM IR code of ch3.cpp, Chapter3_5 of the Cpu0 backend will emit the corresponding machine instructions as follows:
118-165-78-230:input Jonathan$ clang -target mips-unknown-linux-gnu -c
ch3.cpp -emit-llvm -o ch3.bc
118-165-78-230:input Jonathan$ ~/llvm/test/build/bin/llvm-dis
ch3.bc -o -
...
define i32 @main() #0 {
%1 = alloca i32, align 4
store i32 0, i32* %1
ret i32 0
}
118-165-78-230:input Jonathan$ /Users/Jonathan/llvm/test/build/
bin/llc -march=cpu0 -relocation-model=pic -filetype=asm ch3.bc -o -
...
.section .mdebug.abi32
.previous
.file "ch3.bc"
.text
.globl main//static void expandLargeImm\\n
.align 2
.type main,@function
.ent main # @main
main:
.cfi_startproc
.frame $sp,8,$lr
.mask 0x00000000,0
.set noreorder
.set nomacro
# BB#0:
addiu $sp, $sp, -8
$tmp1:
.cfi_def_cfa_offset 8
addiu $2, $zero, 0
st $2, 4($sp)
addiu $sp, $sp, 8
ret $lr
.set macro
.set reorder
.end main
$tmp2:
.size main, ($tmp2)-main
.cfi_endproc
LLVM get the stack size by counting how many virtual registers is assigned to local variables. After that, it calls emitPrologue().
virtual void adjustStackPtr(unsigned SP, int64_t Amount,
MachineBasicBlock &MBB,
MachineBasicBlock::iterator I) const = 0;
lbdex/chapters/Chapter3_5/Cpu0SEInstrInfo.h
/// Adjust SP by Amount bytes.
void adjustStackPtr(unsigned SP, int64_t Amount, MachineBasicBlock &MBB,
MachineBasicBlock::iterator I) const override;
/// Emit a series of instructions to load an immediate. If NewImm is a
/// non-NULL parameter, the last instruction is not emitted, but instead
/// its immediate operand is returned in NewImm.
unsigned loadImmediate(int64_t Imm, MachineBasicBlock &MBB,
MachineBasicBlock::iterator II, const DebugLoc &DL,
unsigned *NewImm) const;
lbdex/chapters/Chapter3_5/Cpu0SEInstrInfo.cpp
/// Adjust SP by Amount bytes.
void Cpu0SEInstrInfo::adjustStackPtr(unsigned SP, int64_t Amount,
MachineBasicBlock &MBB,
MachineBasicBlock::iterator I) const {
DebugLoc DL = I != MBB.end() ? I->getDebugLoc() : DebugLoc();
unsigned ADDu = Cpu0::ADDu;
unsigned ADDiu = Cpu0::ADDiu;
if (isInt<16>(Amount)) {
// addiu sp, sp, amount
BuildMI(MBB, I, DL, get(ADDiu), SP).addReg(SP).addImm(Amount);
}
else { // Expand immediate that doesn't fit in 16-bit.
unsigned Reg = loadImmediate(Amount, MBB, I, DL, nullptr);
BuildMI(MBB, I, DL, get(ADDu), SP).addReg(SP).addReg(Reg, RegState::Kill);
}
}
/// This function generates the sequence of instructions needed to get the
/// result of adding register REG and immediate IMM.
unsigned
Cpu0SEInstrInfo::loadImmediate(int64_t Imm, MachineBasicBlock &MBB,
MachineBasicBlock::iterator II,
const DebugLoc &DL,
unsigned *NewImm) const {
Cpu0AnalyzeImmediate AnalyzeImm;
unsigned Size = 32;
unsigned LUi = Cpu0::LUi;
unsigned ZEROReg = Cpu0::ZERO;
unsigned ATReg = Cpu0::AT;
bool LastInstrIsADDiu = NewImm;
const Cpu0AnalyzeImmediate::InstSeq &Seq =
AnalyzeImm.Analyze(Imm, Size, LastInstrIsADDiu);
Cpu0AnalyzeImmediate::InstSeq::const_iterator Inst = Seq.begin();
assert(Seq.size() && (!LastInstrIsADDiu || (Seq.size() > 1)));
// The first instruction can be a LUi, which is different from other
// instructions (ADDiu, ORI and SLL) in that it does not have a register
// operand.
if (Inst->Opc == LUi)
BuildMI(MBB, II, DL, get(LUi), ATReg).addImm(SignExtend64<16>(Inst->ImmOpnd));
else
BuildMI(MBB, II, DL, get(Inst->Opc), ATReg).addReg(ZEROReg)
.addImm(SignExtend64<16>(Inst->ImmOpnd));
// Build the remaining instructions in Seq.
for (++Inst; Inst != Seq.end() - LastInstrIsADDiu; ++Inst)
BuildMI(MBB, II, DL, get(Inst->Opc), ATReg).addReg(ATReg)
.addImm(SignExtend64<16>(Inst->ImmOpnd));
if (LastInstrIsADDiu)
*NewImm = Inst->ImmOpnd;
return ATReg;
}
In emitPrologue(), it emits machine instructions to adjust the sp (stack pointer register) for local variables. For our example, it will emit the instruction:
addiu $sp, $sp, -8
In the above ch3.cpp assembly output, it generates:
addiu $2, $zero, 0
rather than:
ori $2, $zero, 0
because ADDiu is defined before ORi as shown below, so it takes priority. Of course, if ORi were defined first, it would translate into the ori instruction.
lbdex/chapters/Chapter2/Cpu0InstrInfo.td
// Small immediates
def : Pat<(i32 immSExt16:$in),
(ADDiu ZERO, imm:$in)>;
lbdex/chapters/Chapter3_5/Cpu0InstrInfo.td
let Predicates = [Ch3_5] in {
def : Pat<(i32 immZExt16:$in),
(ORi ZERO, imm:$in)>;
def : Pat<(i32 immLow16Zero:$in),
(LUi (HI16 imm:$in))>;
// Arbitrary immediates
def : Pat<(i32 imm:$imm),
(ORi (LUi (HI16 imm:$imm)), (LO16 imm:$imm))>;
} // let Predicates = [Ch3_4]
Handle stack slot for local variables¶
The following code handle the stack slot for local variables.
lbdex/chapters/Chapter3_5/Cpu0RegisterInfo.cpp
//- If no eliminateFrameIndex(), it will hang on run.
// pure virtual method
// FrameIndex represent objects inside a abstract stack.
// We must replace FrameIndex with an stack/frame pointer
// direct reference.
void Cpu0RegisterInfo::
eliminateFrameIndex(MachineBasicBlock::iterator II, int SPAdj,
unsigned FIOperandNum, RegScavenger *RS) const {
MachineInstr &MI = *II;
MachineFunction &MF = *MI.getParent()->getParent();
MachineFrameInfo &MFI = MF.getFrameInfo();
Cpu0FunctionInfo *Cpu0FI = MF.getInfo<Cpu0FunctionInfo>();
unsigned i = 0;
while (!MI.getOperand(i).isFI()) {
++i;
assert(i < MI.getNumOperands() &&
"Instr doesn't have FrameIndex operand!");
}
LLVM_DEBUG(errs() << "\nFunction : " << MF.getFunction().getName() << "\n";
errs() << "<--------->\n" << MI);
int FrameIndex = MI.getOperand(i).getIndex();
uint64_t stackSize = MF.getFrameInfo().getStackSize();
int64_t spOffset = MF.getFrameInfo().getObjectOffset(FrameIndex);
LLVM_DEBUG(errs() << "FrameIndex : " << FrameIndex << "\n"
<< "spOffset : " << spOffset << "\n"
<< "stackSize : " << stackSize << "\n");
const std::vector<CalleeSavedInfo> &CSI = MFI.getCalleeSavedInfo();
int MinCSFI = 0;
int MaxCSFI = -1;
if (CSI.size()) {
MinCSFI = CSI[0].getFrameIdx();
MaxCSFI = CSI[CSI.size() - 1].getFrameIdx();
}
// The following stack frame objects are always referenced relative to $sp:
// 1. Outgoing arguments.
// 2. Pointer to dynamically allocated stack space.
// 3. Locations for callee-saved registers.
// Everything else is referenced relative to whatever register
// getFrameRegister() returns.
unsigned FrameReg;
FrameReg = Cpu0::SP;
// Calculate final offset.
// - There is no need to change the offset if the frame object is one of the
// following: an outgoing argument, pointer to a dynamically allocated
// stack space or a $gp restore location,
// - If the frame object is any of the following, its offset must be adjusted
// by adding the size of the stack:
// incoming argument, callee-saved register location or local variable.
int64_t Offset;
Offset = spOffset + (int64_t)stackSize;
Offset += MI.getOperand(i+1).getImm();
LLVM_DEBUG(errs() << "Offset : " << Offset << "\n" << "<--------->\n");
// If MI is not a debug value, make sure Offset fits in the 16-bit immediate
// field.
if (!MI.isDebugValue() && !isInt<16>(Offset)) {
errs() << "!!!ERROR!!! Not support large frame over 16-bit at this point.\n"
<< "Though CH3_5 support it."
<< "Reference: "
"http://jonathan2251.github.io/lbd/backendstructure.html#large-stack\n"
<< "However the CH9_3, dynamic-stack-allocation-support bring instruction "
"move $fp, $sp that make it complicated in coding against the tutoral "
"purpose of Cpu0.\n"
<< "Reference: "
"http://jonathan2251.github.io/lbd/funccall.html#dynamic-stack-allocation-support\n";
assert(0 && "(!MI.isDebugValue() && !isInt<16>(Offset))");
}
MI.getOperand(i).ChangeToRegister(FrameReg, false);
MI.getOperand(i+1).ChangeToImmediate(Offset);
}
The eliminateFrameIndex() function in Cpu0RegisterInfo.cpp is called after the stages of instruction selection and register allocation. It translates the frame index to the correct offset of the stack pointer using:
spOffset = MF.getFrameInfo()->getObjectOffset(FrameIndex);
For instance, in ch3.cpp, the offset calculation is displayed as follows:
Spilling live registers at end of block.
BB#0: derived from LLVM BB %0
%V0<def> = ADDiu %ZERO, 0
ST %V0, <fi#0>, 0; mem:ST4[%1]
RetLR %V0<imp-use,kill>
alloc FI(0) at SP[-4]
Function : main
<--------->
ST %V0, <fi#0>, 0; mem:ST4[%1]
FrameIndex : 0
spOffset : -4
stackSize : 8
Offset : 4
<--------->
...
.file "ch3.bc"
...
.frame $sp,8,$lr
...
# BB#0:
addiu $sp, $sp, -8
$tmp1:
.cfi_def_cfa_offset 8
addiu $2, $zero, 0
st $2, 4($sp)
...
lbdex/chapters/Chapter3_5/Cpu0SEFrameLowering.cpp
// This method is called immediately before PrologEpilogInserter scans the
// physical registers used to determine what callee saved registers should be
// spilled. This method is optional.
void Cpu0SEFrameLowering::determineCalleeSaves(MachineFunction &MF,
BitVector &SavedRegs,
RegScavenger *RS) const {
//@determineCalleeSaves-body
TargetFrameLowering::determineCalleeSaves(MF, SavedRegs, RS);
Cpu0FunctionInfo *Cpu0FI = MF.getInfo<Cpu0FunctionInfo>();
if (MF.getFrameInfo().hasCalls())
setAliasRegs(MF, SavedRegs, Cpu0::LR);
return;
}
The determineCalleeSaves() function in Cpu0SEFrameLowering.cpp determines the spill registers. Once the spill registers are identified, the function SpillCalleeSavedRegisters() will save/restore registers to/from stack slots via the following code:
lbdex/chapters/Chapter3_5/Cpu0InstrInfo.h
void storeRegToStackSlot(MachineBasicBlock &MBB,
MachineBasicBlock::iterator MBBI,
Register SrcReg, bool isKill, int FrameIndex,
const TargetRegisterClass *RC,
const TargetRegisterInfo *TRI) const override {
storeRegToStack(MBB, MBBI, SrcReg, isKill, FrameIndex, RC, TRI, 0);
}
void loadRegFromStackSlot(MachineBasicBlock &MBB,
MachineBasicBlock::iterator MBBI,
Register DestReg, int FrameIndex,
const TargetRegisterClass *RC,
const TargetRegisterInfo *TRI) const override {
loadRegFromStack(MBB, MBBI, DestReg, FrameIndex, RC, TRI, 0);
}
virtual void storeRegToStack(MachineBasicBlock &MBB,
MachineBasicBlock::iterator MI,
Register SrcReg, bool isKill, int FrameIndex,
const TargetRegisterClass *RC,
const TargetRegisterInfo *TRI,
int64_t Offset) const = 0;
virtual void loadRegFromStack(MachineBasicBlock &MBB,
MachineBasicBlock::iterator MI,
Register DestReg, int FrameIndex,
const TargetRegisterClass *RC,
const TargetRegisterInfo *TRI,
int64_t Offset) const = 0;
MachineMemOperand *GetMemOperand(MachineBasicBlock &MBB, int FI,
MachineMemOperand::Flags Flags) const;
lbdex/chapters/Chapter3_5/Cpu0InstrInfo.cpp
MachineMemOperand *
Cpu0InstrInfo::GetMemOperand(MachineBasicBlock &MBB, int FI,
MachineMemOperand::Flags Flags) const {
MachineFunction &MF = *MBB.getParent();
MachineFrameInfo &MFI = MF.getFrameInfo();
return MF.getMachineMemOperand(MachinePointerInfo::getFixedStack(MF, FI),
Flags, MFI.getObjectSize(FI),
MFI.getObjectAlign(FI));
}
lbdex/chapters/Chapter3_5/Cpu0SEInstrInfo.h
void storeRegToStack(MachineBasicBlock &MBB,
MachineBasicBlock::iterator MI,
Register SrcReg, bool isKill, int FrameIndex,
const TargetRegisterClass *RC,
const TargetRegisterInfo *TRI,
int64_t Offset) const override;
void loadRegFromStack(MachineBasicBlock &MBB,
MachineBasicBlock::iterator MI,
Register DestReg, int FrameIndex,
const TargetRegisterClass *RC,
const TargetRegisterInfo *TRI,
int64_t Offset) const override;
lbdex/chapters/Chapter3_5/Cpu0SEInstrInfo.cpp
void Cpu0SEInstrInfo::
storeRegToStack(MachineBasicBlock &MBB, MachineBasicBlock::iterator I,
Register SrcReg, bool isKill, int FI,
const TargetRegisterClass *RC, const TargetRegisterInfo *TRI,
int64_t Offset) const {
DebugLoc DL;
MachineMemOperand *MMO = GetMemOperand(MBB, FI, MachineMemOperand::MOStore);
unsigned Opc = 0;
Opc = Cpu0::ST;
assert(Opc && "Register class not handled!");
BuildMI(MBB, I, DL, get(Opc)).addReg(SrcReg, getKillRegState(isKill))
.addFrameIndex(FI).addImm(Offset).addMemOperand(MMO);
}
void Cpu0SEInstrInfo::
loadRegFromStack(MachineBasicBlock &MBB, MachineBasicBlock::iterator I,
Register DestReg, int FI, const TargetRegisterClass *RC,
const TargetRegisterInfo *TRI, int64_t Offset) const {
DebugLoc DL;
if (I != MBB.end()) DL = I->getDebugLoc();
MachineMemOperand *MMO = GetMemOperand(MBB, FI, MachineMemOperand::MOLoad);
unsigned Opc = 0;
Opc = Cpu0::LD;
assert(Opc && "Register class not handled!");
BuildMI(MBB, I, DL, get(Opc), DestReg).addFrameIndex(FI).addImm(Offset)
.addMemOperand(MMO);
}
Functions storeRegToStack() in Cpu0SEInstrInfo.cpp and storeRegToStackSlot() in Cpu0InstrInfo.cpp handle register spilling during the register allocation process.
Each local variable is associated with a frame index. The code .addFrameIndex(FI).addImm(Offset).addMemOperand(MMO); in storeRegToStack() (where Offset is 0) is added for each virtual register.
The functions loadRegFromStackSlot() and loadRegFromStack() are used when registers need to be reloaded from stack slots.
If V0 is added to Cpu0CallingConv.td as shown below and both storeRegToStack() and storeRegToStackSlot() are absent in Cpu0SEInstrInfo.cpp, Cpu0SEInstrInfo.h, and Cpu0InstrInfo.h, the following error will occur.
lbdex/Cpu0/Cpu0CallingConv.td
def CSR_O32 : CalleeSavedRegs<(add LR, FP, V0,
(sequence "S%u", 1, 0))>;
114-43-191-19:input Jonathan$ ~/llvm/test/build/bin/llc
-march=cpu0 -relocation-model=pic -filetype=asm ch3.bc -o -
.text
.section .mdebug.abiO32
.previous
.file "ch3.bc"
Target didn't implement TargetInstrInfo::storeRegToStackSlot!
...
Stack dump:
...
Abort trap: 6
Stage |
Function |
|---|---|
Prologue/Epilogue Insertion & Frame Finalization |
|
|
|
|
|
|
|
|
|
|
|
File PrologEpilogInserter.cpp will call backend functions spillCalleeSavedRegisters(), emitProlog(), emitEpilog() and eliminateFrameIndex() as follows,
lib/CodeGen/PrologEpilogInserter.cpp
class PEI : public MachineFunctionPass {
public:
static char ID;
explicit PEI(const TargetMachine *TM = nullptr) : MachineFunctionPass(ID) {
initializePEIPass(*PassRegistry::getPassRegistry());
if (TM && (!TM->usesPhysRegsForPEI())) {
...
} else {
SpillCalleeSavedRegisters = doSpillCalleeSavedRegs;
...
}
}
...
}
/// insertCSRSpillsAndRestores - Insert spill and restore code for
/// callee saved registers used in the function.
///
static void insertCSRSpillsAndRestores(MachineFunction &Fn,
const MBBVector &SaveBlocks,
const MBBVector &RestoreBlocks) {
...
// Spill using target interface.
for (MachineBasicBlock *SaveBlock : SaveBlocks) {
...
if (!TFI->spillCalleeSavedRegisters(*SaveBlock, I, CSI, TRI)) {
for (unsigned i = 0, e = CSI.size(); i != e; ++i) {
// Insert the spill to the stack frame.
...
TII.storeRegToStackSlot(*SaveBlock, I, Reg, true, CSI[i].getFrameIdx(),
RC, TRI);
}
}
...
}
// Restore using target interface.
for (MachineBasicBlock *MBB : RestoreBlocks) {
...
// Restore all registers immediately before the return and any
// terminators that precede it.
if (!TFI->restoreCalleeSavedRegisters(*MBB, I, CSI, TRI)) {
for (unsigned i = 0, e = CSI.size(); i != e; ++i) {
...
TII.loadRegFromStackSlot(*MBB, I, Reg, CSI[i].getFrameIdx(), RC, TRI);
...
}
...
}
...
}
static void doSpillCalleeSavedRegs(MachineFunction &Fn, RegScavenger *RS,
unsigned &MinCSFrameIndex,
unsigned &MaxCSFrameIndex,
const MBBVector &SaveBlocks,
const MBBVector &RestoreBlocks) {
const Function *F = Fn.getFunction();
const TargetFrameLowering *TFI = Fn.getSubtarget().getFrameLowering();
MinCSFrameIndex = std::numeric_limits<unsigned>::max();
MaxCSFrameIndex = 0;
// Determine which of the registers in the callee save list should be saved.
BitVector SavedRegs;
TFI->determineCalleeSaves(Fn, SavedRegs, RS);
// Assign stack slots for any callee-saved registers that must be spilled.
assignCalleeSavedSpillSlots(Fn, SavedRegs, MinCSFrameIndex, MaxCSFrameIndex);
// Add the code to save and restore the callee saved registers.
if (!F->hasFnAttribute(Attribute::Naked))
insertCSRSpillsAndRestores(Fn, SaveBlocks, RestoreBlocks);
}
void PEI::insertPrologEpilogCode(MachineFunction &Fn) {
const TargetFrameLowering &TFI = *Fn.getSubtarget().getFrameLowering();
// Add prologue to the function...
for (MachineBasicBlock *SaveBlock : SaveBlocks)
TFI.emitPrologue(Fn, *SaveBlock);
// Add epilogue to restore the callee-save registers in each exiting block.
for (MachineBasicBlock *RestoreBlock : RestoreBlocks)
TFI.emitEpilogue(Fn, *RestoreBlock);
...
}
void PEI::replaceFrameIndices(MachineBasicBlock *BB, MachineFunction &Fn,
int &SPAdj) {
...
for (unsigned i = 0, e = MI.getNumOperands(); i != e; ++i) {
...
// If this instruction has a FrameIndex operand, we need to
// use that target machine register info object to eliminate
// it.
TRI.eliminateFrameIndex(MI, SPAdj, i,
FrameIndexVirtualScavenging ? nullptr : RS);
...
}
...
}
/// replaceFrameIndices - Replace all MO_FrameIndex operands with physical
/// register references and actual offsets.
///
void PEI::replaceFrameIndices(MachineFunction &Fn) {
...
// Iterate over the reachable blocks in DFS order.
for (auto DFI = df_ext_begin(&Fn, Reachable), DFE = df_ext_end(&Fn, Reachable);
DFI != DFE; ++DFI) {
...
replaceFrameIndices(BB, Fn, SPAdj);
...
}
// Handle the unreachable blocks.
for (auto &BB : Fn) {
...
replaceFrameIndices(&BB, Fn, SPAdj);
}
}
bool PEI::runOnMachineFunction(MachineFunction &Fn) {
const TargetFrameLowering &TFI = *Fn.getSubtarget().getFrameLowering();
...
FrameIndexVirtualScavenging = TRI->requiresFrameIndexScavenging(Fn);
...
// Handle CSR spilling and restoring, for targets that need it.
SpillCalleeSavedRegisters(Fn, RS, MinCSFrameIndex, MaxCSFrameIndex,
SaveBlocks, RestoreBlocks);
...
// Calculate actual frame offsets for all abstract stack objects...
calculateFrameObjectOffsets(Fn);
// Add prolog and epilog code to the function. This function is required
// to align the stack frame as necessary for any stack variables or
// called functions. Because of this, calculateCalleeSavedRegisters()
// must be called before this function in order to set the AdjustsStack
// and MaxCallFrameSize variables.
if (!F->hasFnAttribute(Attribute::Naked))
insertPrologEpilogCode(Fn);
// Replace all MO_FrameIndex operands with physical register references
// and actual offsets.
//
replaceFrameIndices(Fn);
// If register scavenging is needed, as we've enabled doing it as a
// post-pass, scavenge the virtual registers that frame index elimination
// inserted.
if (TRI->requiresRegisterScavenging(Fn) && FrameIndexVirtualScavenging) {
ScavengeFrameVirtualRegs(Fn, RS);
// Clear any vregs created by virtual scavenging.
Fn.getRegInfo().clearVirtRegs();
}
...
}
Large stack¶
At this stage, we have successfully translated a simple main()
function containing only return 0;. However, the stack size
adjustments for 32-bit values are handled by Cpu0AnalyzeImmediate.cpp
and the instruction definitions in Cpu0InstrInfo.td from Chapter3_5.
Later, in CH9_3, dynamic stack allocation support introduces the instruction:
move $fp, $sp
This addition makes the implementation more complex, potentially diverging from the tutorial’s primary focus on the Cpu0 architecture.
Thus, for simplicity, we avoid handling large stack frames at this stage. [4]
lbdex/chapters/Chapter3_5/CMakeLists.txt
add_llvm_target(
...
Cpu0AnalyzeImmediate.cpp
...
)
lbdex/chapters/Chapter3_5/Cpu0AnalyzeImmediate.h
//===-- Cpu0AnalyzeImmediate.h - Analyze Immediates ------------*- C++ -*--===//
//
// The LLVM Compiler Infrastructure
//
// This file is distributed under the University of Illinois Open Source
// License. See LICENSE.TXT for details.
//
//===----------------------------------------------------------------------===//
#ifndef CPU0_ANALYZE_IMMEDIATE_H
#define CPU0_ANALYZE_IMMEDIATE_H
#include "Cpu0Config.h"
#if CH >= CH3_5
#include "llvm/ADT/SmallVector.h"
#include "llvm/Support/DataTypes.h"
namespace llvm {
class Cpu0AnalyzeImmediate {
public:
struct Inst {
unsigned Opc, ImmOpnd;
Inst(unsigned Opc, unsigned ImmOpnd);
};
typedef SmallVector<Inst, 7 > InstSeq;
/// Analyze - Get an instruction sequence to load immediate Imm. The last
/// instruction in the sequence must be an ADDiu if LastInstrIsADDiu is
/// true;
const InstSeq &Analyze(uint64_t Imm, unsigned Size, bool LastInstrIsADDiu);
private:
typedef SmallVector<InstSeq, 5> InstSeqLs;
/// AddInstr - Add I to all instruction sequences in SeqLs.
void AddInstr(InstSeqLs &SeqLs, const Inst &I);
/// GetInstSeqLsADDiu - Get instruction sequences which end with an ADDiu to
/// load immediate Imm
void GetInstSeqLsADDiu(uint64_t Imm, unsigned RemSize, InstSeqLs &SeqLs);
/// GetInstSeqLsORi - Get instruction sequences which end with an ORi to
/// load immediate Imm
void GetInstSeqLsORi(uint64_t Imm, unsigned RemSize, InstSeqLs &SeqLs);
/// GetInstSeqLsSHL - Get instruction sequences which end with a SHL to
/// load immediate Imm
void GetInstSeqLsSHL(uint64_t Imm, unsigned RemSize, InstSeqLs &SeqLs);
/// GetInstSeqLs - Get instruction sequences to load immediate Imm.
void GetInstSeqLs(uint64_t Imm, unsigned RemSize, InstSeqLs &SeqLs);
/// ReplaceADDiuSHLWithLUi - Replace an ADDiu & SHL pair with a LUi.
void ReplaceADDiuSHLWithLUi(InstSeq &Seq);
/// GetShortestSeq - Find the shortest instruction sequence in SeqLs and
/// return it in Insts.
void GetShortestSeq(InstSeqLs &SeqLs, InstSeq &Insts);
unsigned Size;
unsigned ADDiu, ORi, SHL, LUi;
InstSeq Insts;
};
}
#endif // #if CH >= CH3_5
#endif
lbdex/chapters/Chapter3_5/Cpu0AnalyzeImmediate.cpp
//===-- Cpu0AnalyzeImmediate.cpp - Analyze Immediates ---------------------===//
//
// The LLVM Compiler Infrastructure
//
// This file is distributed under the University of Illinois Open Source
// License. See LICENSE.TXT for details.
//
//===----------------------------------------------------------------------===//
#include "Cpu0AnalyzeImmediate.h"
#include "Cpu0.h"
#if CH >= CH3_5
#include "llvm/Support/MathExtras.h"
using namespace llvm;
Cpu0AnalyzeImmediate::Inst::Inst(unsigned O, unsigned I) : Opc(O), ImmOpnd(I) {}
// Add I to the instruction sequences.
void Cpu0AnalyzeImmediate::AddInstr(InstSeqLs &SeqLs, const Inst &I) {
// Add an instruction seqeunce consisting of just I.
if (SeqLs.empty()) {
SeqLs.push_back(InstSeq(1, I));
return;
}
for (InstSeqLs::iterator Iter = SeqLs.begin(); Iter != SeqLs.end(); ++Iter)
Iter->push_back(I);
}
void Cpu0AnalyzeImmediate::GetInstSeqLsADDiu(uint64_t Imm, unsigned RemSize,
InstSeqLs &SeqLs) {
GetInstSeqLs((Imm + 0x8000ULL) & 0xffffffffffff0000ULL, RemSize, SeqLs);
AddInstr(SeqLs, Inst(ADDiu, Imm & 0xffffULL));
}
void Cpu0AnalyzeImmediate::GetInstSeqLsORi(uint64_t Imm, unsigned RemSize,
InstSeqLs &SeqLs) {
GetInstSeqLs(Imm & 0xffffffffffff0000ULL, RemSize, SeqLs);
AddInstr(SeqLs, Inst(ORi, Imm & 0xffffULL));
}
void Cpu0AnalyzeImmediate::GetInstSeqLsSHL(uint64_t Imm, unsigned RemSize,
InstSeqLs &SeqLs) {
unsigned Shamt = countTrailingZeros(Imm);
GetInstSeqLs(Imm >> Shamt, RemSize - Shamt, SeqLs);
AddInstr(SeqLs, Inst(SHL, Shamt));
}
void Cpu0AnalyzeImmediate::GetInstSeqLs(uint64_t Imm, unsigned RemSize,
InstSeqLs &SeqLs) {
uint64_t MaskedImm = Imm & (0xffffffffffffffffULL >> (64 - Size));
// Do nothing if Imm is 0.
if (!MaskedImm)
return;
// A single ADDiu will do if RemSize <= 16.
if (RemSize <= 16) {
AddInstr(SeqLs, Inst(ADDiu, MaskedImm));
return;
}
// Shift if the lower 16-bit is cleared.
if (!(Imm & 0xffff)) {
GetInstSeqLsSHL(Imm, RemSize, SeqLs);
return;
}
GetInstSeqLsADDiu(Imm, RemSize, SeqLs);
// If bit 15 is cleared, it doesn't make a difference whether the last
// instruction is an ADDiu or ORi. In that case, do not call GetInstSeqLsORi.
if (Imm & 0x8000) {
InstSeqLs SeqLsORi;
GetInstSeqLsORi(Imm, RemSize, SeqLsORi);
SeqLs.insert(SeqLs.end(), SeqLsORi.begin(), SeqLsORi.end());
}
}
// Replace a ADDiu & SHL pair with a LUi.
// e.g. the following two instructions
// ADDiu 0x0111
// SHL 18
// are replaced with
// LUi 0x444
void Cpu0AnalyzeImmediate::ReplaceADDiuSHLWithLUi(InstSeq &Seq) {
// Check if the first two instructions are ADDiu and SHL and the shift amount
// is at least 16.
if ((Seq.size() < 2) || (Seq[0].Opc != ADDiu) ||
(Seq[1].Opc != SHL) || (Seq[1].ImmOpnd < 16))
return;
// Sign-extend and shift operand of ADDiu and see if it still fits in 16-bit.
int64_t Imm = SignExtend64<16>(Seq[0].ImmOpnd);
int64_t ShiftedImm = (uint64_t)Imm << (Seq[1].ImmOpnd - 16);
if (!isInt<16>(ShiftedImm))
return;
// Replace the first instruction and erase the second.
Seq[0].Opc = LUi;
Seq[0].ImmOpnd = (unsigned)(ShiftedImm & 0xffff);
Seq.erase(Seq.begin() + 1);
}
void Cpu0AnalyzeImmediate::GetShortestSeq(InstSeqLs &SeqLs, InstSeq &Insts) {
InstSeqLs::iterator ShortestSeq = SeqLs.end();
// The length of an instruction sequence is at most 7.
unsigned ShortestLength = 8;
for (InstSeqLs::iterator S = SeqLs.begin(); S != SeqLs.end(); ++S) {
ReplaceADDiuSHLWithLUi(*S);
assert(S->size() <= 7);
if (S->size() < ShortestLength) {
ShortestSeq = S;
ShortestLength = S->size();
}
}
Insts.clear();
Insts.append(ShortestSeq->begin(), ShortestSeq->end());
}
const Cpu0AnalyzeImmediate::InstSeq
&Cpu0AnalyzeImmediate::Analyze(uint64_t Imm, unsigned Size,
bool LastInstrIsADDiu) {
this->Size = Size;
ADDiu = Cpu0::ADDiu;
ORi = Cpu0::ORi;
SHL = Cpu0::SHL;
LUi = Cpu0::LUi;
InstSeqLs SeqLs;
// Get the list of instruction sequences.
if (LastInstrIsADDiu | !Imm)
GetInstSeqLsADDiu(Imm, Size, SeqLs);
else
GetInstSeqLs(Imm, Size, SeqLs);
// Set Insts to the shortest instruction sequence.
GetShortestSeq(SeqLs, Insts);
return Insts;
}
#endif
lbdex/chapters/Chapter3_5/Cpu0InstrInfo.h
#include "Cpu0AnalyzeImmediate.h"
lbdex/chapters/Chapter3_5/Cpu0InstrInfo.td
class Cpu0InstAlias<string Asm, dag Result, bit Emit = 0b1> :
InstAlias<Asm, Result, Emit>;
def shamt : Operand<i32>;
// Unsigned Operand
def uimm16 : Operand<i32> {
let PrintMethod = "printUnsignedImm";
}
// Transformation Function - get the lower 16 bits.
def LO16 : SDNodeXForm<imm, [{
return getImm(N, N->getZExtValue() & 0xffff);
}]>;
// Transformation Function - get the higher 16 bits.
def HI16 : SDNodeXForm<imm, [{
return getImm(N, (N->getZExtValue() >> 16) & 0xffff);
}]>;
// Node immediate fits as 16-bit zero extended on target immediate.
// The LO16 param means that only the lower 16 bits of the node
// immediate are caught.
// e.g. addiu, sltiu
def immZExt16 : PatLeaf<(imm), [{
if (N->getValueType(0) == MVT::i32)
return (uint32_t)N->getZExtValue() == (unsigned short)N->getZExtValue();
else
return (uint64_t)N->getZExtValue() == (unsigned short)N->getZExtValue();
}], LO16>;
// Immediate can be loaded with LUi (32-bit int with lower 16-bit cleared).
def immLow16Zero : PatLeaf<(imm), [{
int64_t Val = N->getSExtValue();
return isInt<32>(Val) && !(Val & 0xffff);
}]>;
// shamt field must fit in 5 bits.
def immZExt5 : ImmLeaf<i32, [{return Imm == (Imm & 0x1f);}]>;
let Predicates = [Ch3_5] in {
// Arithmetic and logical instructions with 3 register operands.
class ArithLogicR<bits<8> op, string instr_asm, SDNode OpNode,
InstrItinClass itin, RegisterClass RC, bit isComm = 0>:
FA<op, (outs GPROut:$ra), (ins RC:$rb, RC:$rc),
!strconcat(instr_asm, "\t$ra, $rb, $rc"),
[(set GPROut:$ra, (OpNode RC:$rb, RC:$rc))], itin> {
let shamt = 0;
let isCommutable = isComm; // e.g. add rb rc = add rc rb
let isReMaterializable = 1;
}
}
let Predicates = [Ch3_5] in {
// Shifts
class shift_rotate_imm<bits<8> op, bits<4> isRotate, string instr_asm,
SDNode OpNode, PatFrag PF, Operand ImmOpnd,
RegisterClass RC>:
FA<op, (outs GPROut:$ra), (ins RC:$rb, ImmOpnd:$shamt),
!strconcat(instr_asm, "\t$ra, $rb, $shamt"),
[(set GPROut:$ra, (OpNode RC:$rb, PF:$shamt))], IIAlu> {
let rc = 0;
}
// 32-bit shift instructions.
class shift_rotate_imm32<bits<8> op, bits<4> isRotate, string instr_asm,
SDNode OpNode>:
shift_rotate_imm<op, isRotate, instr_asm, OpNode, immZExt5, shamt, CPURegs>;
}
let Predicates = [Ch3_5] in {
// Load Upper Imediate
class LoadUpper<bits<8> op, string instr_asm, RegisterClass RC, Operand Imm>:
FL<op, (outs RC:$ra), (ins Imm:$imm16),
!strconcat(instr_asm, "\t$ra, $imm16"), [], IIAlu> {
let rb = 0;
let isReMaterializable = 1;
}
}
let Predicates = [Ch3_5] in {
def ORi : ArithLogicI<0x0d, "ori", or, uimm16, immZExt16, CPURegs>;
}
let Predicates = [Ch3_5] in {
def LUi : LoadUpper<0x0F, "lui", GPROut, uimm16>;
}
let Predicates = [Ch3_5] in {
let Predicates = [DisableOverflow] in {
def ADDu : ArithLogicR<0x11, "addu", add, IIAlu, CPURegs, 1>;
}
}
let Predicates = [Ch3_5] in {
def SHL : shift_rotate_imm32<0x1e, 0x00, "shl", shl>;
}
let Predicates = [Ch3_5] in {
//===----------------------------------------------------------------------===//
// Instruction aliases
//===----------------------------------------------------------------------===//
def : Cpu0InstAlias<"move $dst, $src",
(ADDu GPROut:$dst, GPROut:$src,ZERO), 1>;
}
let Predicates = [Ch3_5] in {
def : Pat<(i32 immZExt16:$in),
(ORi ZERO, imm:$in)>;
def : Pat<(i32 immLow16Zero:$in),
(LUi (HI16 imm:$in))>;
// Arbitrary immediates
def : Pat<(i32 imm:$imm),
(ORi (LUi (HI16 imm:$imm)), (LO16 imm:$imm))>;
} // let Predicates = [Ch3_4]
The Cpu0AnalyzeImmediate.cpp implementation is recursive and has a
somewhat complex logic. However, recursive techniques are commonly
covered in compiler frontend books, so you should already be familiar
with them.
Instead of tracing the code directly, we list the stack size and the corresponding instructions generated in:
Table: Cpu0 stack adjustment instructions before replacing ``addiu`` and ``shl`` with ``lui`` instructions
as follows, and in:
Table: Cpu0 stack adjustment instructions after replacing ``addiu`` and ``shl`` with ``lui`` instructions
in the next section.
stack size range |
ex. stack size |
Cpu0 Prologue instructions |
Cpu0 Epilogue instructions |
|---|---|---|---|
0 ~ 0x7ff8 |
|
|
|
0x8000 ~ 0xfff8 |
|
|
|
x10000 ~ 0xfffffff8 |
|
|
|
x10000 ~ 0xfffffff8 |
|
|
|
Since the Cpu0 stack is 8-byte aligned, addresses from 0x7FF9 to 0x7FFF cannot exist.
Assume sp = 0xA0008000 and stack size = 0x90008000, then
(0xA0008000 - 0x90008000) => 0x10000000.
Verify with the Cpu0 prologue instructions as follows,
“addiu $1, $zero, -9” => ($1 = 0 + 0xfffffff7) => $1 = 0xfffffff7.
“shl $1, $1, 28;” => $1 = 0x70000000.
“addiu $1, $1, -32768” => $1 = (0x70000000 + 0xffff8000) => $1 = 0x6fff8000.
“addu $sp, $sp, $1” => $sp = (0xa0008000 + 0x6fff8000) => $sp = 0x10000000.
Verify with the Cpu0 epilogue instructions with sp = 0x10000000 and
stack size = 0x90008000 as follows,
“addiu $1, $zero, -28671” => ($1 = 0 + 0xffff9001) => $1 = 0xffff9001.
“shl $1, $1, 16;” => $1 = 0x90010000.
“addiu $1, $1, -32768” => $1 = (0x90010000 + 0xffff8000) => $1 = 0x90008000.
“addu $sp, $sp, $1” => $sp = (0x10000000 + 0x90008000) => $sp = 0xa0008000.
The Cpu0AnalyzeImmediate::GetShortestSeq() will call
Cpu0AnalyzeImmediate::ReplaceADDiuSHLWithLUi() to replace addiu and
shl with a single instruction lui only.
The effect is shown in the following table.
stack size range |
ex. stack size |
Cpu0 Prologue instructions |
Cpu0 Epilogue instructions |
|---|---|---|---|
0x8000 ~ 0xfff8 |
|
|
|
x10000 ~ 0xfffffff8 |
|
|
|
x10000 ~ 0xfffffff8 |
|
|
|
Assume sp = 0xA0008000 and stack size = 0x90008000, then
(0xA0008000 - 0x90008000) => 0x10000000.
Verify with the Cpu0 prologue instructions as follows,
“lui $1, 28671” => $1 = 0x6fff0000.
“ori $1, $1, 32768” => $1 = (0x6fff0000 + 0x00008000) => $1 = 0x6fff8000.
“addu $sp, $sp, $1” => $sp = (0xa0008000 + 0x6fff8000) => $sp = 0x10000000.
Verify with the Cpu0 epilogue instructions with sp = 0x10000000 and
stack size = 0x90008000 as follows,
“lui $1, 36865” => $1 = 0x90010000.
“addiu $1, $1, -32768” => $1 = (0x90010000 + 0xffff8000) => $1 = 0x90008000.
“addu $sp, $sp, $1” => $sp = (0x10000000 + 0x90008000) => $sp = 0xa0008000.
The file ch3_largeframe.cpp includes the large frame test.
Running Chapter3_5 with ch3_largeframe.cpp will produce the following result.
lbdex/input/ch3_largeframe.cpp
int test_largegframe() {
int a[469753856];
return 0;
}
118-165-78-12:input Jonathan$ clang -target mips-unknown-linux-gnu -c
ch3_largeframe.cpp -emit-llvm -o ch3_largeframe.bc
118-165-78-12:input Jonathan$ /Users/Jonathan/llvm/test/build/
bin/llc -march=cpu0 -relocation-model=pic -filetype=asm
ch3_largeframe.bc.bc -o -
...
.section .mdebug.abiO32
.previous
.file "ch3_largeframe.bc"
.globl _Z16test_largegframev
.align 2
.type _Z16test_largegframev,@function
.ent _Z16test_largegframev # @_Z16test_largegframev
_Z16test_largegframev:
.frame $fp,1879015424,$lr
.mask 0x00000000,0
.set noreorder
.set nomacro
.set noat
# BB#0:
lui $1, 36865
addiu $1, $1, -32768
addu $sp, $sp, $1
addiu $2, $zero, 0
lui $1, 28672
addiu $1, $1, -32768
addu $sp, $sp, $1
ret $lr
.set at
.set macro
.set reorder
.end _Z16test_largegframev
$func_end0:
.size _Z16test_largegframev, ($func_end0)-_Z16test_largegframev
Data operands DAGs¶
From the above or the compiler book, you can see that all the OP codes are the internal nodes in DAG graphs, and operands are the leaves of DAGs.
To develop your backend, you can copy the related data operand DAG nodes from other backends since the IR data nodes are handled by all backends.
Regarding data DAG nodes, you can understand some of them through
Cpu0InstrInfo.td and find them using the following command:
grep -R “<datadag>” `find llvm/include/llvm`,
By spending a little more time thinking or making educated guesses, you can identify them. Some data DAGs are well understood, some are partially understood, and some remain unknown—but that is acceptable.
Here is a list of some data DAGs we understand and have encountered so far:
include/llvm/Target/TargetSelectionDAG.td
// PatLeaf's are pattern fragments that have no operands. This is just a helper
// to define immediates and other common things concisely.
class PatLeaf<dag frag, code pred = [{}], SDNodeXForm xform = NOOP_SDNodeXForm>
: PatFrag<(ops), frag, pred, xform>;
// ImmLeaf is a pattern fragment with a constraint on the immediate. The
// constraint is a function that is run on the immediate (always with the value
// sign extended out to an int64_t) as Imm. For example:
//
// def immSExt8 : ImmLeaf<i16, [{ return (char)Imm == Imm; }]>;
//
// this is a more convenient form to match 'imm' nodes in than PatLeaf and also
// is preferred over using PatLeaf because it allows the code generator to
// reason more about the constraint.
//
// If FastIsel should ignore all instructions that have an operand of this type,
// the FastIselShouldIgnore flag can be set. This is an optimization to reduce
// the code size of the generated fast instruction selector.
class ImmLeaf<ValueType vt, code pred, SDNodeXForm xform = NOOP_SDNodeXForm>
: PatFrag<(ops), (vt imm), [{}], xform> {
let ImmediateCode = pred;
bit FastIselShouldIgnore = 0;
}
lbdex/chapters/Chapter3_5/Cpu0InstrInfo.td
// Signed Operand
def simm16 : Operand<i32> {
let DecoderMethod= "DecodeSimm16";
}
def shamt : Operand<i32>;
// Unsigned Operand
def uimm16 : Operand<i32> {
let PrintMethod = "printUnsignedImm";
}
// Address operand
def mem : Operand<iPTR> {
let PrintMethod = "printMemOperand";
let MIOperandInfo = (ops GPROut, simm16);
let EncoderMethod = "getMemEncoding";
}
// Transformation Function - get the lower 16 bits.
def LO16 : SDNodeXForm<imm, [{
return getImm(N, N->getZExtValue() & 0xffff);
}]>;
// Transformation Function - get the higher 16 bits.
def HI16 : SDNodeXForm<imm, [{
return getImm(N, (N->getZExtValue() >> 16) & 0xffff);
}]>;
// Node immediate fits as 16-bit sign extended on target immediate.
// e.g. addi, andi
def immSExt16 : PatLeaf<(imm), [{ return isInt<16>(N->getSExtValue()); }]>;
// Node immediate fits as 16-bit zero extended on target immediate.
// The LO16 param means that only the lower 16 bits of the node
// immediate are caught.
// e.g. addiu, sltiu
def immZExt16 : PatLeaf<(imm), [{
if (N->getValueType(0) == MVT::i32)
return (uint32_t)N->getZExtValue() == (unsigned short)N->getZExtValue();
else
return (uint64_t)N->getZExtValue() == (unsigned short)N->getZExtValue();
}], LO16>;
// Immediate can be loaded with LUi (32-bit int with lower 16-bit cleared).
def immLow16Zero : PatLeaf<(imm), [{
int64_t Val = N->getSExtValue();
return isInt<32>(Val) && !(Val & 0xffff);
}]>;
// shamt field must fit in 5 bits.
def immZExt5 : ImmLeaf<i32, [{return Imm == (Imm & 0x1f);}]>;
// Cpu0 Address Mode! SDNode frameindex could possibily be a match
// since load and store instructions from stack used it.
def addr :
ComplexPattern<iPTR, 2, "SelectAddr", [frameindex], [SDNPWantParent]>;
//===----------------------------------------------------------------------===//
// Pattern fragment for load/store
//===----------------------------------------------------------------------===//
class AlignedLoad<PatFrag Node> :
PatFrag<(ops node:$ptr), (Node node:$ptr), [{
LoadSDNode *LD = cast<LoadSDNode>(N);
return LD->getMemoryVT().getSizeInBits()/8 <= LD->getAlignment();
}]>;
class AlignedStore<PatFrag Node> :
PatFrag<(ops node:$val, node:$ptr), (Node node:$val, node:$ptr), [{
StoreSDNode *SD = cast<StoreSDNode>(N);
return SD->getMemoryVT().getSizeInBits()/8 <= SD->getAlignment();
}]>;
def load_a : AlignedLoad<load>;
def store_a : AlignedStore<store>;
As mentioned in the subsection “Instruction Selection” of the last chapter,
immSExt16 is a data leaf DAG node that returns true if its value is
within the range of a signed 16-bit integer. The load_a, store_a,
and others are similar, but they check for alignment.
The mem is explained in Chapter3_2 for printing operands, and addr
is explained in Chapter3_3 for data DAG selection.
The simm16, …, are inherited from Operand<i32> because Cpu0 is
a 32-bit architecture. It may exceed 16 bits, so the immSExt16 pattern
leaf is used to constrain it, as seen in the ADDiu example mentioned
in the last chapter.
The PatLeaf immZExt16, immLow16Zero, and ImmLeaf immZExt5 are
similar to immSExt16.
Summary of this Chapter
———————–
Summary the functions for llvm backend stages as the following table.
118-165-79-200:input Jonathan$ /Users/Jonathan/llvm/test/build/
bin/llc -march=cpu0 -relocation-model=pic -filetype=asm ch3.bc
-debug-pass=Structure -o -
...
Machine Branch Probability Analysis
ModulePass Manager
FunctionPass Manager
...
CPU0 DAG->DAG Pattern Instruction Selection
Initial selection DAG
Optimized lowered selection DAG
Type-legalized selection DAG
Optimized type-legalized selection DAG
Legalized selection DAG
Optimized legalized selection DAG
Instruction selection
Selected selection DAG
Scheduling
...
Greedy Register Allocator
...
Prologue/Epilogue Insertion & Frame Finalization
...
Post-RA pseudo instruction expansion pass
...
Cpu0 Assembly Printer
Stage |
Function |
|---|---|
Before CPU0 DAG->DAG Pattern Instruction Selection |
|
Instruction selection |
|
Prologue/Epilogue Insertion & Frame Finalization |
|
|
|
|
|
|
|
|
|
|
|
Post-RA pseudo instruction expansion pass |
|
Cpu0 Assembly Printer |
|
We add a pass in Instruction Section stage in section “Add Cpu0DAGToDAGISel
class”. You can embed your code into other passes like that. Please check
CodeGen/Passes.h for the information. Remember the pass is called according
the function unit as the llc -debug-pass=Structure indicated.
We have finished a simple compiler for cpu0 which only supports ld, st, addiu, ori, lui, addu, shl and ret 8 instructions.
We add a pass in the Instruction Selection stage in the section
“Add Cpu0DAGToDAGISel class.” You can embed your code into other passes
similarly. Please check CodeGen/Passes.h for more information.
Remember that passes are called according to the function unit, as indicated
by the command llc -debug-pass=Structure.
We have completed a simple compiler for Cpu0, which only supports eight instructions: ld, st, addiu, ori, lui, addu, shl, and ret.
We are satisfied with this result. However, you might think, “After writing so much code, we only implemented these eight instructions!” The key takeaway is that we have built a framework for the Cpu0 target machine. (Refer to the LLVM backend structure class inheritance tree earlier in this chapter.)
So far, we have written over 3,000 lines of source code, including comments,
across multiple files: *.cpp, *.h, *.td, and CMakeLists.txt.
You can count them using the command:
wc `find dir -name *.cpp`
for *.cpp, *.h, *.td, and *.txt files.
In contrast, the LLVM front-end tutorial contains only about 700 lines of
source code (excluding comments).
Don’t be discouraged by these results. In reality, writing a backend starts slowly but speeds up over time.
For comparison:
Clang has over 500,000 lines of source code (including comments) in the
clang/libdirectory, supporting both C++ and Objective-C.The MIPS backend in LLVM 3.1 contains 15,000 lines (with comments).
Even the complex x86 CPU backend, which is CISC externally but RISC internally (using micro-instructions), has only 45,000 lines in LLVM 3.1 (with comments).
In the next chapter, we will demonstrate how adding support for a new instruction is as easy as 1-2-3!