Cpu0 ELF linker¶
LLD changes frequently, and the figures in this chapter are not up to date. Like LLVM, the LLD linker includes support for multiple targets in ELF format.
The term “Cpu0 backend” used in this chapter can refer to ELF format handling for the Cpu0 target under LLD, the LLVM compiler backend, or both. It is assumed that readers will understand the intended meaning from the context.
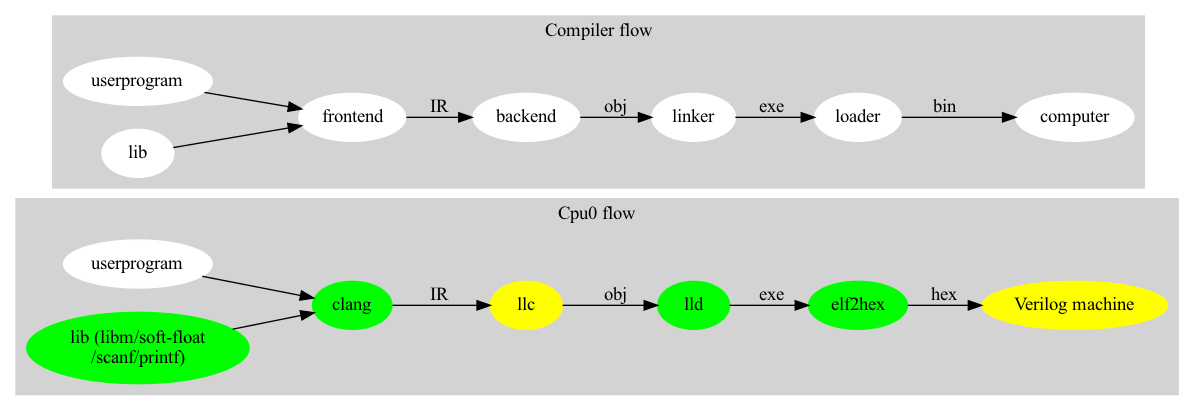
Fig. 3 Code generation and execution flow¶
As depicted in Fig. 3 of chapter About, beside LLVM backend, we implement ELF linker and elf2hex to run on Cpu0 Verilog simulator.
This chapter extends LLD to support the Cpu0 backend as well as elf2hex to replace the Cpu0 loader.
After linking with LLD, the program with global variables can be allocated in ELF file format layout. This means relocation records of global variables are resolved.
In addition, elf2hex is implemented to generate Hex files from ELF.
With these two tools, global variables in sections .data and .rodata can be accessed and transferred to Hex files which feed the Verilog Cpu0 machine running on your PC/Laptop.
As previous chapters mentioned, Cpu0 has two relocation models for static and
dynamic linking respectively, controlled by the option -relocation-model in
llc. This chapter supports static linking.
For more about LLD, please refer to the LLD website here [1] and the LLD install requirements on Linux here [2].
Currently, LLD can be built by gcc and clang on Ubuntu. On iMac, LLD can be built by clang with the Xcode version as described in the next subsection.
If you run inside a Virtual Machine (VM), please set the physical memory size over 1GB to avoid insufficient memory link errors.
ELF to Hex¶
The code to convert ELF file format into Hex format for Cpu0 as follows,
exlbt/elf2hex/CMakeLists.txt
# elf2hex.cpp needs backend related functions, like
# LLVMInitializeCpu0TargetInfo and LLVMInitializeCpu0Disassembler ... etc.
# Set LLVM_LINK_COMPONENTS then it can link them during the link stage.
set(LLVM_LINK_COMPONENTS
AllTargetsDescs
AllTargetsDisassemblers
AllTargetsInfos
CodeGen
MCDisassembler
Symbolize
)
add_llvm_tool(elf2hex
elf2hex.cpp
../dishex/disas.cpp
)
if(HAVE_LIBXAR)
target_link_libraries(elf2hex PRIVATE ${XAR_LIB})
endif()
if(LLVM_INSTALL_BINUTILS_SYMLINKS)
add_llvm_tool_symlink(elf2hex elf2hex)
endif()
exlbt/elf2hex/elf2hex.h
//
// The LLVM Compiler Infrastructure
//
// This file is distributed under the University of Illinois Open Source
// License. See LICENSE.TXT for details.
//
//===----------------------------------------------------------------------===//
#ifndef LLVM_TOOLS_ELF2HEX_ELF2HEX_H
#define LLVM_TOOLS_ELF2HEX_ELF2HEX_H
#include "../dishex/disas.h"
#include "llvm/DebugInfo/DIContext.h"
#include "llvm/Support/CommandLine.h"
#include <stdio.h>
#include "llvm/Support/raw_ostream.h"
#define BOOT_SIZE 16
#define DLINK
//#define ELF2HEX_DEBUG
namespace llvm {
namespace elf2hex {
using namespace object;
class HexOut {
public:
virtual void ProcessDisAsmInstruction(uint64_t Size,
ArrayRef<uint8_t> Bytes, const ObjectFile *Obj) = 0;
virtual void ProcessDataSection(SectionRef Section) {};
virtual ~HexOut() {};
};
// Split HexOut from Reader::DisassembleObject() for separating hex output
// functions.
class VerilogHex : public HexOut {
public:
VerilogHex(const ObjectFile *Obj);
void ProcessDisAsmInstruction(uint64_t Size,
ArrayRef<uint8_t> Bytes, const ObjectFile *Obj) override;
void ProcessDataSection(SectionRef Section) override;
private:
void PrintBootSection(uint64_t textOffset, uint64_t isrAddr, bool isLittleEndian);
void Fill0s(uint64_t startAddr, uint64_t endAddr);
void PrintDataSection(SectionRef Section);
uint64_t lastDumpAddr;
unsigned si;
StringRef sectionName;
DisAs *Disas;
};
class Reader {
public:
void DisassembleObject(const ObjectFile *Obj);
StringRef CurrentSymbol();
SectionRef CurrentSection();
unsigned CurrentSi();
uint64_t CurrentIndex();
private:
SectionRef _section;
std::vector<std::pair<uint64_t, StringRef> > Symbols;
unsigned si;
uint64_t Index;
};
} // end namespace elf2hex
} // end namespace llvm
//using namespace llvm;
#endif
exlbt/elf2hex/elf2hex.cpp
//===-- llvm-objdump.cpp - Object file dumping utility for llvm -----------===//
//
// The LLVM Compiler Infrastructure
//
// This file is distributed under the University of Illinois Open Source
// License. See LICENSE.TXT for details.
//
//===----------------------------------------------------------------------===//
//
// This program is a utility that works like binutils "objdump", that is, it
// dumps out a plethora of information about an object file depending on the
// flags.
//
// The flags and output of this program should be near identical to those of
// binutils objdump.
//
//===----------------------------------------------------------------------===//
#define ELF2HEX
#include "elf2hex.h"
#include "llvm/MC/MCAsmInfo.h"
#include "llvm/MC/MCContext.h"
#include "llvm/MC/MCInst.h"
#include "llvm/MC/MCInstrAnalysis.h"
#include "llvm/MC/MCInstrInfo.h"
#include "llvm/MC/MCObjectFileInfo.h"
#include "llvm/MC/MCTargetOptions.h"
#include "llvm/Object/MachO.h"
#include "llvm/Support/InitLLVM.h"
#include "llvm/Support/TargetSelect.h"
using namespace llvm;
using namespace llvm::object;
extern StringRef ToolName;
static StringRef CurrInputFile;
// copy from llvm-objdump.cpp
LLVM_ATTRIBUTE_NORETURN void reportError(StringRef File,
const Twine &Message) {
outs().flush();
WithColor::error(errs(), ToolName) << "'" << File << "': " << Message << "\n";
exit(1);
}
// copy from llvm-objdump.h
template <typename T, typename... Ts>
T unwrapOrError(Expected<T> EO, Ts &&... Args) {
if (EO)
return std::move(*EO);
assert(0 && "error in unwrapOrError()");
}
// copy from llvm-objdump.cpp
static cl::OptionCategory Elf2hexCat("elf2hex Options");
static cl::list<std::string> InputFilenames(cl::Positional,
cl::desc("<input object files>"),
cl::ZeroOrMore,
cl::cat(Elf2hexCat));
std::string TripleName = "";
bool isRelocAddressLess(RelocationRef A, RelocationRef B) {
return A.getOffset() < B.getOffset();
}
void error(std::error_code EC) {
if (!EC)
return;
WithColor::error(errs(), ToolName)
<< "reading file: " << EC.message() << ".\n";
errs().flush();
exit(1);
}
static void getName(llvm::object::SectionRef const &Section, StringRef Name) {
Name = unwrapOrError(Section.getName(), CurrInputFile);
#ifdef ELF2HEX_DEBUG
llvm::dbgs() << Name << "\n";
#endif
}
static cl::opt<bool>
LittleEndian("le",
cl::desc("Little endian format"));
#ifdef ELF2HEX_DEBUG
// Modified from PrintSectionHeaders()
uint64_t GetSectionHeaderStartAddress(const ObjectFile *Obj,
StringRef sectionName) {
// outs() << "Sections:\n"
// "Idx Name Size Address Type\n";
std::error_code ec;
unsigned i = 0;
for (const SectionRef &Section : Obj->sections()) {
error(ec);
StringRef Name;
error(getName(Section, Name));
uint64_t Address;
Address = Section.getAddress();
uint64_t Size;
Size = Section.getSize();
bool Text;
Text = Section.isText();
if (Name == sectionName)
return Address;
else
return 0;
++i;
}
return 0;
}
#endif
// Reference from llvm::printSymbolTable of llvm-objdump.cpp
uint64_t GetSymbolAddress(const ObjectFile *o, StringRef SymbolName) {
for (const SymbolRef &Symbol : o->symbols()) {
Expected<uint64_t> AddressOrError = Symbol.getAddress();
if (!AddressOrError)
reportError(o->getFileName(), SymbolName);
uint64_t Address = *AddressOrError;
Expected<SymbolRef::Type> TypeOrError = Symbol.getType();
if (!TypeOrError)
reportError(o->getFileName(), SymbolName);
SymbolRef::Type Type = *TypeOrError;
section_iterator Section = unwrapOrError(Symbol.getSection(), CurrInputFile);
StringRef Name;
if (Type == SymbolRef::ST_Debug && Section != o->section_end()) {
if (Expected<StringRef> NameOrErr = Section->getName())
Name = *NameOrErr;
else
consumeError(NameOrErr.takeError());
} else {
Name = unwrapOrError(Symbol.getName(), o->getFileName());
}
if (Name == SymbolName)
return Address;
}
return 0;
}
uint64_t SectionOffset(const ObjectFile *o, StringRef secName) {
for (const SectionRef &Section : o->sections()) {
StringRef Name;
uint64_t BaseAddr;
Name = unwrapOrError(Section.getName(), o->getFileName());
unwrapOrError(Section.getContents(), o->getFileName());
BaseAddr = Section.getAddress();
if (Name == secName)
return BaseAddr;
}
return 0;
}
static const Triple getTriple(const ObjectFile *Obj) {
// Figure out the target triple.
static Triple TheTriple("unknown-unknown-unknown");
TheTriple = Obj->makeTriple();
return TheTriple;
}
using namespace llvm::elf2hex;
Reader reader;
VerilogHex::VerilogHex(const ObjectFile *Obj) {
const Triple TheTriple = getTriple(Obj);
this->Disas = new DisAs(TheTriple);
lastDumpAddr = 0;
#ifdef ELF2HEX_DEBUG
//uint64_t startAddr = GetSectionHeaderStartAddress(Obj, "_start");
//errs() << format("_start address:%08" PRIx64 "\n", startAddr);
#endif
uint64_t isrAddr = GetSymbolAddress(Obj, "ISR");
errs() << format("ISR address:%08" PRIx64 "\n", isrAddr);
//uint64_t pltOffset = SectionOffset(Obj, ".plt");
uint64_t textOffset = SectionOffset(Obj, ".text");
PrintBootSection(textOffset, isrAddr, LittleEndian);
lastDumpAddr = BOOT_SIZE;
Fill0s(lastDumpAddr, 0x100);
lastDumpAddr = 0x100;
}
void VerilogHex::PrintBootSection(uint64_t textOffset, uint64_t isrAddr,
bool isLittleEndian) {
uint64_t offset = textOffset - 4;
// isr instruction at 0x8 and PC counter point to next instruction
uint64_t isrOffset = isrAddr - 8 - 4;
if (isLittleEndian) {
outs() << "/* 0:*/ ";
outs() << format("%02" PRIx64 " ", (offset & 0xff));
outs() << format("%02" PRIx64 " ", (offset & 0xff00) >> 8);
outs() << format("%02" PRIx64 "", (offset & 0xff0000) >> 16);
outs() << " 36";
outs() << " /* jmp 0x";
outs() << format("%02" PRIx64 "%02" PRIx64 "%02" PRIx64 " */\n",
(offset & 0xff0000) >> 16, (offset & 0xff00) >> 8, (offset & 0xff));
outs() <<
"/* 4:*/ 04 00 00 36 /* jmp 4 */\n";
offset -= 8;
outs() << "/* 8:*/ ";
outs() << format("%02" PRIx64 " ", (isrOffset & 0xff));
outs() << format("%02" PRIx64 " ", (isrOffset & 0xff00) >> 8);
outs() << format("%02" PRIx64 "", (isrOffset & 0xff0000) >> 16);
outs() << " 36";
outs() << " /* jmp 0x";
outs() << format("%02" PRIx64 "%02" PRIx64 "%02" PRIx64 " */\n",
(isrOffset & 0xff0000) >> 16, (isrOffset & 0xff00) >> 8, (isrOffset & 0xff));
outs() <<
"/* c:*/ fc ff ff 36 /* jmp -4 */\n";
}
else {
outs() << "/* 0:*/ 36 ";
outs() << format("%02" PRIx64 " ", (offset & 0xff0000) >> 16);
outs() << format("%02" PRIx64 " ", (offset & 0xff00) >> 8);
outs() << format("%02" PRIx64 "", (offset & 0xff));
outs() << " /* jmp 0x";
outs() << format("%02" PRIx64 "%02" PRIx64 "%02" PRIx64 " */\n",
(offset & 0xff0000) >> 16, (offset & 0xff00) >> 8, (offset & 0xff));
outs() <<
"/* 4:*/ 36 00 00 04 /* jmp 4 */\n";
offset -= 8;
outs() << "/* 8:*/ 36 ";
outs() << format("%02" PRIx64 " ", (isrOffset & 0xff0000) >> 16);
outs() << format("%02" PRIx64 " ", (isrOffset & 0xff00) >> 8);
outs() << format("%02" PRIx64 "", (isrOffset & 0xff));
outs() << " /* jmp 0x";
outs() << format("%02" PRIx64 "%02" PRIx64 "%02" PRIx64 " */\n",
(isrOffset & 0xff0000) >> 16, (isrOffset & 0xff00) >> 8, (isrOffset & 0xff));
outs() <<
"/* c:*/ 36 ff ff fc /* jmp -4 */\n";
}
}
// Fill /*address*/ 00 00 00 00 [startAddr..endAddr] from startAddr to endAddr.
// Include startAddr and endAddr.
void VerilogHex::Fill0s(uint64_t startAddr, uint64_t endAddr) {
std::size_t addr;
assert((startAddr <= endAddr) && "startAddr must <= BaseAddr");
// Fill /*address*/ 00 00 00 00 for 4 bytes alignment (1 Cpu0 word size)
for (addr = startAddr; addr < endAddr; addr += 4) {
outs() << format("/*%8" PRIx64 ":*/\t", addr);
outs() << format("%02" PRIx64 " ", 0) << format("%02" PRIx64 " ", 0) \
<< format("%02" PRIx64 " ", 0) << format("%02" PRIx64 " ", 0) << '\n';
}
return;
}
// Print {/*memory-address*/, hex instruction, /* assembly instruction */}
// e.g. /* 20840:*/ ff ff 70 0f/* lui $7, 65535*/
void VerilogHex::ProcessDisAsmInstruction(uint64_t Size,
ArrayRef<uint8_t> Bytes, const ObjectFile *Obj) {
SectionRef Section = reader.CurrentSection();
StringRef Name;
StringRef Contents;
Name = unwrapOrError(Section.getName(), Obj->getFileName());
unwrapOrError(Section.getContents(), Obj->getFileName());
uint64_t SectionAddr = Section.getAddress();
uint64_t Index = reader.CurrentIndex();
#ifdef ELF2HEX_DEBUG
errs() << format("SectionAddr + Index = %8" PRIx64 "\n", SectionAddr + Index);
errs() << format("lastDumpAddr %8" PRIx64 "\n", lastDumpAddr);
#endif
if (lastDumpAddr < SectionAddr) {
Fill0s(lastDumpAddr, SectionAddr - 1);
lastDumpAddr = SectionAddr;
}
// print section name when meeting it first time
if (sectionName != Name) {
StringRef SegmentName = "";
if (const MachOObjectFile *MachO =
dyn_cast<const MachOObjectFile>(Obj)) {
DataRefImpl DR = Section.getRawDataRefImpl();
SegmentName = MachO->getSectionFinalSegmentName(DR);
}
outs() << "/*" << "Disassembly of section ";
if (!SegmentName.empty())
outs() << SegmentName << ",";
outs() << Name << ':' << "*/";
sectionName = Name;
}
if (si != reader.CurrentSi()) {
// print function name in section .text just before the first instruction
// is printed
outs() << '\n' << "/*" << reader.CurrentSymbol() << ":*/\n";
si = reader.CurrentSi();
}
// print instruction address
outs() << format("/*%8" PRIx64 ":*/", SectionAddr + Index);
// print instruction in hex format
outs() << "\t";
dumpBytes(Bytes.slice(Index, Size), outs());
// Disassemble and print disassembly instruction to Asm
std::string Asm;
llvm::raw_string_ostream RSO(Asm);
Disas->disassemble(Bytes.slice(Index), RSO);
outs() << "/* " << Asm << "*/\n";
// In section .plt or .text, the Contents.size() maybe < (SectionAddr + Index + 4)
if (Contents.size() < (SectionAddr + Index + 4))
lastDumpAddr = SectionAddr + Index + 4;
else
lastDumpAddr = SectionAddr + Contents.size();
}
void VerilogHex::ProcessDataSection(SectionRef Section) {
std::string Error;
StringRef Name;
StringRef Contents;
uint64_t BaseAddr;
uint64_t size;
getName(Section, Name);
unwrapOrError(Section.getContents(), CurrInputFile);
BaseAddr = Section.getAddress();
#ifdef ELF2HEX_DEBUG
errs() << format("BaseAddr = %8" PRIx64 "\n", BaseAddr);
errs() << format("lastDumpAddr %8" PRIx64 "\n", lastDumpAddr);
#endif
if (lastDumpAddr < BaseAddr) {
Fill0s(lastDumpAddr, BaseAddr - 1);
lastDumpAddr = BaseAddr;
}
if ((Name == ".bss" || Name == ".sbss") && Contents.size() > 0) {
size = (Contents.size() + 3)/4*4;
Fill0s(BaseAddr, BaseAddr + size - 1);
lastDumpAddr = BaseAddr + size;
return;
}
else {
PrintDataSection(Section);
}
}
// Print data section as the following form:
// /*Contents of section :*/
// /* 100d4 */6a 75 73 74 69 66 3a 20 22 25 31 30 73 22 0a 00 /* justif: "%10s"..*/
// /* 100e4 */68 65 78 20 25 30 32 78 20 3d 20 30 30 0a 00 74 /* hex %02x = 00..t*/
// ...
void VerilogHex::PrintDataSection(SectionRef Section) {
std::string Error;
StringRef Name;
uint64_t BaseAddr;
uint64_t size;
getName(Section, Name);
StringRef Contents = unwrapOrError(Section.getContents(), CurrInputFile);
BaseAddr = Section.getAddress();
if (Contents.size() <= 0) {
return;
}
size = (Contents.size()+3)/4*4;
outs() << "/*Contents of section " << Name << ":*/\n";
// Dump out the content as hex and printable ascii characters.
for (std::size_t addr = 0, end = Contents.size(); addr < end; addr += 16) {
outs() << format("/*%8:" PRIx64 ":*/\t", BaseAddr + addr);
// Dump line of hex.
for (std::size_t i = 0; i < 16; ++i) {
if (i != 0 && i % 4 == 0)
outs() << ' ';
if (addr + i < end)
outs() << hexdigit((Contents[addr + i] >> 4) & 0xF, true)
<< hexdigit(Contents[addr + i] & 0xF, true) << " ";
}
// Print ascii.
outs() << "/*" << " ";
for (std::size_t i = 0; i < 16 && addr + i < end; ++i) {
if (std::isprint(static_cast<unsigned char>(Contents[addr + i]) & 0xFF))
outs() << Contents[addr + i];
else
outs() << ".";
}
outs() << "*/" << "\n";
}
for (std::size_t i = Contents.size(); i < size; i++) {
outs() << "00 ";
}
outs() << "\n";
#ifdef ELF2HEX_DEBUG
errs() << "Name " << Name << " BaseAddr ";
errs() << format("%8" PRIx64 " Contents.size() ", BaseAddr);
errs() << format("%8" PRIx64 " size ", Contents.size());
errs() << format("%8" PRIx64 " \n", size);
#endif
// save the end address of this section to lastDumpAddr
lastDumpAddr = BaseAddr + size;
}
StringRef Reader::CurrentSymbol() {
return Symbols[si].second;
}
SectionRef Reader::CurrentSection() {
return _section;
}
unsigned Reader::CurrentSi() {
return si;
}
uint64_t Reader::CurrentIndex() {
return Index;
}
// Porting from DisassembleObject() of llvm-objump.cpp
void Reader::DisassembleObject(const ObjectFile *Obj) {
VerilogHex hexOut(Obj);
std::error_code ec;
for (const SectionRef &Section : Obj->sections()) {
_section = Section;
uint64_t BaseAddr;
unwrapOrError(Section.getContents(), Obj->getFileName());
BaseAddr = Section.getAddress();
uint64_t SectSize = Section.getSize();
if (!SectSize)
continue;
if (BaseAddr < 0x100)
continue;
#ifdef ELF2HEX_DEBUG
StringRef SectionName = unwrapOrError(Section.getName(), Obj->getFileName());
errs() << "SectionName " << SectionName << format(" BaseAddr %8" PRIx64 "\n", BaseAddr);
#endif
bool text;
text = Section.isText();
if (!text) {
hexOut.ProcessDataSection(Section);
continue;
}
// It's .text section
uint64_t SectionAddr;
SectionAddr = Section.getAddress();
// Make a list of all the symbols in this section.
for (const SymbolRef &Symbol : Obj->symbols()) {
if (Section.containsSymbol(Symbol)) {
Expected<uint64_t> AddressOrErr = Symbol.getAddress();
error(errorToErrorCode(AddressOrErr.takeError()));
uint64_t Address = *AddressOrErr;
Address -= SectionAddr;
if (Address >= SectSize)
continue;
Expected<StringRef> Name = Symbol.getName();
error(errorToErrorCode(Name.takeError()));
Symbols.push_back(std::make_pair(Address, *Name));
}
}
// Sort the symbols by address, just in case they didn't come in that way.
array_pod_sort(Symbols.begin(), Symbols.end());
#ifdef ELF2HEX_DEBUG
for (unsigned si = 0, se = Symbols.size(); si != se; ++si) {
errs() << '\n' << "/*" << Symbols[si].first << " " << Symbols[si].second << ":*/\n";
}
#endif
// Make a list of all the relocations for this section.
std::vector<RelocationRef> Rels;
// Sort relocations by address.
std::sort(Rels.begin(), Rels.end(), isRelocAddressLess);
StringRef name;
getName(Section, name);
// If the section has no symbols just insert a dummy one and disassemble
// the whole section.
if (Symbols.empty())
Symbols.push_back(std::make_pair(0, name));
SmallString<40> Comments;
raw_svector_ostream CommentStream(Comments);
ArrayRef<uint8_t> Bytes = arrayRefFromStringRef(
unwrapOrError(Section.getContents(), Obj->getFileName()));
#if 0
Section.getContents();
ArrayRef<uint8_t> Bytes(reinterpret_cast<const uint8_t *>(BytesStr.data()),
BytesStr.size());
#endif
const uint64_t Size = 4;
SectSize = Section.getSize();
// Disassemble symbol by symbol.
unsigned se;
for (si = 0, se = Symbols.size(); si != se; ++si) {
uint64_t Start = Symbols[si].first;
uint64_t End;
// The end is either the size of the section or the beginning of the next
// symbol.
if (si == se - 1)
End = SectSize;
// Make sure this symbol takes up space.
else if (Symbols[si + 1].first != Start)
End = Symbols[si + 1].first - 1;
else {
continue;
}
// Now this section is ".text" section, so disassemble binary instructions
// into assembly instructions
for (Index = Start; Index < End; Index += Size) {
hexOut.ProcessDisAsmInstruction(Size, Bytes, Obj);
} // for
} // for
}
}
// Porting from disassembleObject() of llvm-objump.cpp
static void Elf2Hex(const ObjectFile *Obj) {
reader.DisassembleObject(Obj);
}
static void DumpObject(const ObjectFile *o) {
outs() << "/*";
outs() << o->getFileName()
<< ":\tfile format " << o->getFileFormatName() << "*/";
outs() << "\n\n";
Elf2Hex(o);
}
/// @brief Open file and figure out how to dump it.
static void DumpInput(StringRef file) {
CurrInputFile = file;
// Attempt to open the binary.
Expected<OwningBinary<Binary>> BinaryOrErr = createBinary(file);
if (!BinaryOrErr)
reportError(file, "no this file");
Binary &Binary = *BinaryOrErr.get().getBinary();
if (ObjectFile *o = dyn_cast<ObjectFile>(&Binary))
DumpObject(o);
else
reportError(file, "invalid_file_type");
}
int main(int argc, char **argv) {
using namespace llvm;
InitLLVM X(argc, argv);
cl::HideUnrelatedOptions(Elf2hexCat);
cl::ParseCommandLineOptions(argc, argv, "llvm object file dumper\n");
ToolName = argv[0];
// Defaults to a.out if no filenames specified.
if (InputFilenames.size() == 0)
InputFilenames.push_back("a.out");
std::for_each(InputFilenames.begin(), InputFilenames.end(),
DumpInput);
return EXIT_SUCCESS;
}
exlbt/dishex/disas.h
#ifndef LLVM_TOOLS_DISAS_DISAS_H
#define LLVM_TOOLS_DISAS_DISAS_H
#include "llvm/DebugInfo/DIContext.h"
#include "llvm/MC/MCDisassembler/MCDisassembler.h"
#include "llvm/MC/MCInstPrinter.h"
#include "llvm/Object/MachO.h"
#include "llvm/Support/CommandLine.h"
#include "llvm/Support/Compiler.h"
#include "llvm/Support/DataTypes.h"
#include "llvm/Object/Archive.h"
#include "llvm/Support/raw_ostream.h"
#include "llvm/Support/TargetRegistry.h"
using namespace llvm;
using namespace llvm::object;
class DisAs {
public:
DisAs(const Triple TheTriple);
bool disassemble(const ArrayRef<uint8_t> Bytes, llvm::raw_string_ostream &RSO) const;
bool getInstruction(const ArrayRef<uint8_t> Bytes, MCInst &Inst) const;
const Target *getTarget(const Triple TheTriple) const;
void reportError(const Twine &Message) const;
private:
void initLLVM();
void create(const Triple TheTriple);
const MCSubtargetInfo *createSTI(const Target *TheTarget);
std::unique_ptr<MCDisassembler> DisAsm;
std::unique_ptr<MCInstPrinter> IP;
const MCSubtargetInfo *STI;
const Target *TheTarget;
const MCRegisterInfo *MRI;
const MCAsmInfo *AsmInfo;
MCContext *Ctx;
};
#endif // LIVM_TOOLS_DISAS_DISAS_H
exlbt/dishex/disas.cpp
#include "disas.h"
#include "llvm/MC/MCAsmInfo.h"
#include "llvm/MC/MCContext.h"
#include "llvm/MC/MCInst.h"
#include "llvm/MC/MCInstrAnalysis.h"
#include "llvm/MC/MCInstrInfo.h"
#include "llvm/MC/MCObjectFileInfo.h"
#include "llvm/MC/MCTargetOptions.h"
#include "llvm/Object/MachO.h"
#include "llvm/Support/InitLLVM.h"
#include "llvm/Support/TargetSelect.h"
#include <algorithm>
StringRef ToolName;
static std::string TripleName = "";
static std::string MCPU = "";
void DisAs::reportError(const Twine &Message) const {
outs().flush();
WithColor::error(errs(), ToolName) << ": " << Message << "\n";
exit(1);
}
// Initialize all targets, components and disassemblers.
void DisAs::initLLVM() {
// Initialize targets and assembly printers/parsers.
llvm::InitializeAllTargetInfos();
llvm::InitializeAllTargetMCs();
llvm::InitializeAllDisassemblers();
// Register the target printer for --version.
cl::AddExtraVersionPrinter(TargetRegistry::printRegisteredTargetsForVersion);
}
// Outpu:
// TheTarget
// TripleName
// Input:
// TheTriple
const Target *DisAs::getTarget(const Triple TheTriple) const {
// Get the target specific parser.
Triple Triple2 = TheTriple;;
std:: string Error;
const Target *TheTarget = TargetRegistry::lookupTarget("", Triple2, Error);
if (!TheTarget)
reportError("Can't find target: " + Error);
return TheTarget;
}
// Return/Output:
// STI
// Input:
// TheTarget
const MCSubtargetInfo *DisAs::createSTI(const Target *TheTarget) {
// Package up features to be passed to target/subtarget
SubtargetFeatures Features;
const MCSubtargetInfo *STI =
TheTarget->createMCSubtargetInfo(TripleName, MCPU, Features.getString());
if (!STI)
reportError("no subtarget info for target " + TripleName);
return STI;
}
// Create MCDisassemble and MCInstPrinter for the "disassembler task".
// Output:
// DisAsm, IP(Instruction Printer)
// Important! Remember that certain objects, such as Ctx, must exist outside
// the scope of the `create()` function. Do not declare them as local variables
// with `create()`, or they will be destroyed after the function exists.
void DisAs::create(const Triple TheTriple) {
// Update the triple name and return the found target.
TripleName = TheTriple.getTriple();
TheTarget = getTarget(TheTriple);
MRI = TheTarget->createMCRegInfo(TripleName);
if (!MRI)
reportError("no register info for target " + TripleName);
// Set up disassembler.
MCTargetOptions MCOptions;
AsmInfo = TheTarget->createMCAsmInfo(*MRI, TripleName, MCOptions);
if (!AsmInfo)
reportError("no assembly info for target " + TripleName);
// Create member variable STI
STI = createSTI(TheTarget);
MCObjectFileInfo MOFI;
Ctx = new MCContext(AsmInfo, MRI, &MOFI);
// FIXME: for now initialize MCObjectFileInfo with default value
MOFI.InitMCObjectFileInfo(Triple(TripleName), false, *Ctx);
// Create member variable DisAsm
std:: unique_ptr<MCDisassembler> DisAsm(
TheTarget->createMCDisassembler(*STI, *Ctx));
if (!DisAsm)
reportError("error: no disassembler for target " + TripleName);
this->DisAsm = std::move(DisAsm);
int AsmPrinterVariant = AsmInfo->getAssemblerDialect();
const MCInstrInfo *MII = TheTarget->createMCInstrInfo();
if (!MII)
reportError("error: no instruction info for target " + TripleName);
// Create member variable IP
std::unique_ptr<MCInstPrinter> IP(TheTarget->createMCInstPrinter(
Triple(TripleName), AsmPrinterVariant, *AsmInfo, *MII, *MRI));
if (!IP)
reportError("error: no instruction printer for target " + TripleName);
this->IP = std::move(IP);
}
// Hex -> MCInst
// Convert Hex string to MCInst
// Output:
// Inst
// Input:
// Hex
bool DisAs::getInstruction(const ArrayRef<uint8_t> Bytes, MCInst &Inst) const {
#if 0
outs() << "Bytes size: " << Bytes.size() << "\n";
dumpBytes(Bytes, outs());
outs() << "\n" ;
#endif
uint64_t Size = 0;
SmallString<40> Comments;
raw_svector_ostream CommentStream(Comments);
bool Disassembled = DisAsm->getInstruction(Inst, Size, Bytes, 0, CommentStream);
if (!Disassembled) {
reportError("error: DisAsm->getInstruction");
}
return Disassembled;
}
// Bin -> MCInst
// Convert a Binary Instruction to MCInst.
// Output:
// RSO
// Input:
// Bytes
bool DisAs::disassemble(const ArrayRef<uint8_t> Bytes, llvm::raw_string_ostream &RSO) const {
MCInst Inst;
bool Disassembled = getInstruction(Bytes, Inst);
if (Disassembled) {
IP->printInst(&Inst, 0, "", *STI, RSO);
}
return Disassembled;
}
// Initialize LLVM targets and components, and create both MCDisassembler
// (DisAsm) and MCInstPrinter(IP) for the "disassembler task".
DisAs::DisAs(const Triple TheTriple) {
initLLVM();
create(TheTriple);
}
To support the commands llvm-objdump -d and llvm-objdump -t for Cpu0, the following code is added to llvm-objdump.cpp:
exlbt/llvm-objdump/llvm-objdump.cpp
case ELF::EM_CPU0: //Cpu0
Create Cpu0 backend under LLD¶
LLD introduction¶
In general, the linker performs relocation record resolution as described in the ELF support chapter. Some optimizations cannot be completed during the compiler stage. One such optimization opportunity in the linker is Dead Code Stripping, which is explained as follows:
Dead code stripping - example (modified from llvm lto document web)
a.h
extern int foo1(void);
extern void foo2(void);
extern int foo4(void);
a.cpp
#include "a.h"
static signed int i = 0;
void foo2(void) {
i = -1;
}
static int foo3() {
return (10+foo4());
}
int foo1(void) {
int data = 0;
if (i < 0)
data = foo3();
data = data + 42;
return data;
}
ch13_1.cpp
#include "a.h"
void ISR() {
asm("ISR:");
return;
}
int foo4(void) {
return 5;
}
int main() {
return foo1();
}
The above code can be simplified to Fig. 4 to perform mark and sweep in the graph for Dead Code Stripping.
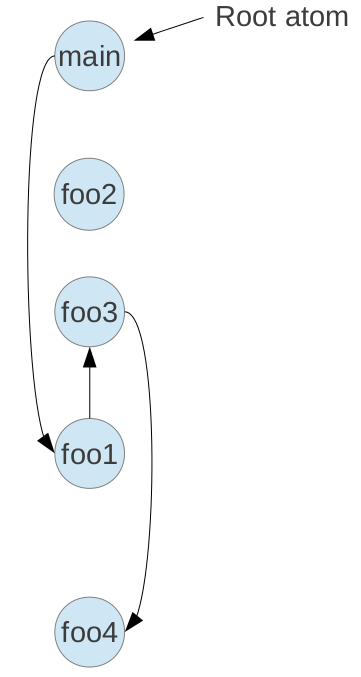
Fig. 4 Atom classified (from lld web)¶
As shown in the above example, the function foo2() is an isolated node without any references. It is dead code and should be removed during linker optimization. We tested this example using Makefile.ch13_1 and found that foo2() was not removed.
There are two possible reasons for this behavior. First, the dead code stripping optimization in LLD might not be enabled by default in the command line. Second, LLD may not have implemented this optimization yet, which is reasonable given that LLD was in its early stages of development at the time.
We did not investigate further since the Cpu0 backend tutorial only requires a linker to complete relocation record resolution and to run the program on a PC.
Note that llvm-linker works at the LLVM IR level and performs linker optimizations there. However, if you only have object files (e.g., a.o), the native linker (such as LLD) has the opportunity to perform dead code stripping, while the IR linker cannot.
Static linker¶
Let’s run the static linker first and explain it next.
File printf-stdarg.c [3] comes from an internet download and
is under the GPL2 license. GPL2 is more restrictive than the LLVM license.
exlbt/input/printf-stdarg-1.c
/*
Copyright 2001, 2002 Georges Menie (www.menie.org)
stdarg version contributed by Christian Ettinger
This program is free software; you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as published by
the Free Software Foundation; either version 2 of the License, or
(at your option) any later version.
This program is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public License
along with this program; if not, write to the Free Software
Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA
*/
/*
putchar is the only external dependency for this file,
if you have a working putchar, leave it commented out.
If not, uncomment the define below and
replace outbyte(c) by your own function call.
#define putchar(c) outbyte(c)
*/
// gcc printf-stdarg-1.c
// ./a.out
#include <stdio.h>
#define TEST_PRINTF
#ifdef TEST_PRINTF
int main(void)
{
char *ptr = "Hello world!";
char *np = 0;
int i = 5;
unsigned int bs = sizeof(int)*8;
int mi;
char buf[80];
mi = (1 << (bs-1)) + 1;
printf("%s\n", ptr);
printf("printf test\n");
printf("%s is null pointer\n", np);
printf("%d = 5\n", i);
printf("%d = - max int\n", mi);
printf("char %c = 'a'\n", 'a');
printf("hex %x = ff\n", 0xff);
printf("hex %02x = 00\n", 0);
printf("signed %d = unsigned %u = hex %x\n", -3, -3, -3);
printf("%d %s(s)%", 0, "message");
printf("\n");
printf("%d %s(s) with %%\n", 0, "message");
sprintf(buf, "justif: \"%-10s\"\n", "left"); printf("%s", buf);
sprintf(buf, "justif: \"%10s\"\n", "right"); printf("%s", buf);
sprintf(buf, " 3: %04d zero padded\n", 3); printf("%s", buf);
sprintf(buf, " 3: %-4d left justif.\n", 3); printf("%s", buf);
sprintf(buf, " 3: %4d right justif.\n", 3); printf("%s", buf);
sprintf(buf, "-3: %04d zero padded\n", -3); printf("%s", buf);
sprintf(buf, "-3: %-4d left justif.\n", -3); printf("%s", buf);
sprintf(buf, "-3: %4d right justif.\n", -3); printf("%s", buf);
return 0;
}
/*
* if you compile this file with
* gcc -Wall $(YOUR_C_OPTIONS) -DTEST_PRINTF -c printf.c
* you will get a normal warning:
* printf.c:214: warning: spurious trailing `%' in format
* this line is testing an invalid % at the end of the format string.
*
* this should display (on 32bit int machine) :
*
* Hello world!
* printf test
* (null) is null pointer
* 5 = 5
* -2147483647 = - max int
* char a = 'a'
* hex ff = ff
* hex 00 = 00
* signed -3 = unsigned 4294967293 = hex fffffffd
* 0 message(s)
* 0 message(s) with %
* justif: "left "
* justif: " right"
* 3: 0003 zero padded
* 3: 3 left justif.
* 3: 3 right justif.
* -3: -003 zero padded
* -3: -3 left justif.
* -3: -3 right justif.
*/
#endif
exlbt/input/printf-stdarg-def.c
#include "print.h"
// Definition putchar(int c) for printf-stdarg.c
// For memory IO
int putchar(int c)
{
char *p = (char*)IOADDR;
*p = c;
return 0;
}
exlbt/input/printf-stdarg.c
/*
Copyright 2001, 2002 Georges Menie (www.menie.org)
stdarg version contributed by Christian Ettinger
This program is free software; you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as published by
the Free Software Foundation; either version 2 of the License, or
(at your option) any later version.
This program is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public License
along with this program; if not, write to the Free Software
Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA
*/
/*
putchar is the only external dependency for this file,
if you have a working putchar, leave it commented out.
If not, uncomment the define below and
replace outbyte(c) by your own function call.
#define putchar(c) outbyte(c)
*/
#include <stdarg.h>
static void printchar(char **str, int c)
{
extern int putchar(int c);
if (str) {
**str = c;
++(*str);
}
else (void)putchar(c);
}
#define PAD_RIGHT 1
#define PAD_ZERO 2
static int prints(char **out, const char *string, int width, int pad)
{
int pc = 0, padchar = ' ';
if (width > 0) {
int len = 0;
const char *ptr;
for (ptr = string; *ptr; ++ptr) ++len;
if (len >= width) width = 0;
else width -= len;
if (pad & PAD_ZERO) padchar = '0';
}
if (!(pad & PAD_RIGHT)) {
for ( ; width > 0; --width) {
printchar (out, padchar);
++pc;
}
}
for ( ; *string ; ++string) {
printchar (out, *string);
++pc;
}
for ( ; width > 0; --width) {
printchar (out, padchar);
++pc;
}
return pc;
}
/* the following should be enough for 32 bit int */
#define PRINT_BUF_LEN 12
static int printi(char **out, int i, int b, int sg, int width, int pad, int letbase)
{
char print_buf[PRINT_BUF_LEN];
char *s;
int t, neg = 0, pc = 0;
unsigned int u = i;
if (i == 0) {
print_buf[0] = '0';
print_buf[1] = '\0';
return prints (out, print_buf, width, pad);
}
if (sg && b == 10 && i < 0) {
neg = 1;
u = -i;
}
s = print_buf + PRINT_BUF_LEN-1;
*s = '\0';
while (u) {
t = u % b;
if( t >= 10 )
t += letbase - '0' - 10;
*--s = t + '0';
u /= b;
}
if (neg) {
if( width && (pad & PAD_ZERO) ) {
printchar (out, '-');
++pc;
--width;
}
else {
*--s = '-';
}
}
return pc + prints (out, s, width, pad);
}
static int print(char **out, const char *format, va_list args )
{
int width, pad;
int pc = 0;
char scr[2];
for (; *format != 0; ++format) {
if (*format == '%') {
++format;
width = pad = 0;
if (*format == '\0') break;
if (*format == '%') goto out;
if (*format == '-') {
++format;
pad = PAD_RIGHT;
}
//bool have_ll = (format[0] == 'l' && format[1] == 'l');
//pc += have_ll * 2;
while (*format == '0') {
++format;
pad |= PAD_ZERO;
}
for ( ; *format >= '0' && *format <= '9'; ++format) {
width *= 10;
width += *format - '0';
}
if( *format == 's' ) {
char *s = (char *)va_arg( args, int );
pc += prints (out, s?s:"(null)", width, pad);
continue;
}
if( *format == 'd' ) {
pc += printi (out, va_arg( args, int ), 10, 1, width, pad, 'a');
continue;
}
if( *format == 'x' ) {
pc += printi (out, va_arg( args, int ), 16, 0, width, pad, 'a');
continue;
}
if( *format == 'X' ) {
pc += printi (out, va_arg( args, int ), 16, 0, width, pad, 'A');
continue;
}
if( *format == 'u' ) {
pc += printi (out, va_arg( args, int ), 10, 0, width, pad, 'a');
continue;
}
if( *format == 'c' ) {
/* char are converted to int then pushed on the stack */
scr[0] = (char)va_arg( args, int );
scr[1] = '\0';
pc += prints (out, scr, width, pad);
continue;
}
}
else {
out:
printchar (out, *format);
++pc;
}
}
if (out) **out = '\0';
va_end( args );
return pc;
}
int printf(const char *format, ...)
{
va_list args;
va_start( args, format );
return print( 0, format, args );
}
int sprintf(char *out, const char *format, ...)
{
va_list args;
va_start( args, format );
return print( &out, format, args );
}
#ifdef TEST_PRINTF
int main(void)
{
char ptr[] = "Hello world!";
char *np = 0;
int i = 5;
unsigned int bs = sizeof(int)*8;
int mi;
char buf[80];
mi = (1 << (bs-1)) + 1;
printf("%s\n", ptr);
printf("printf test\n");
printf("%s is null pointer\n", np);
printf("%d = 5\n", i);
printf("%d = - max int\n", mi);
printf("char %c = 'a'\n", 'a');
printf("hex %x = ff\n", 0xff);
printf("hex %02x = 00\n", 0);
printf("signed %d = unsigned %u = hex %x\n", -3, -3, -3);
printf("%d %s(s)", 0, "message");
printf("\n");
printf("%d %s(s) with %%\n", 0, "message");
sprintf(buf, "justif: \"%-10s\"\n", "left"); printf("%s", buf);
sprintf(buf, "justif: \"%10s\"\n", "right"); printf("%s", buf);
sprintf(buf, " 3: %04d zero padded\n", 3); printf("%s", buf);
sprintf(buf, " 3: %-4d left justif.\n", 3); printf("%s", buf);
sprintf(buf, " 3: %4d right justif.\n", 3); printf("%s", buf);
sprintf(buf, "-3: %04d zero padded\n", -3); printf("%s", buf);
sprintf(buf, "-3: %-4d left justif.\n", -3); printf("%s", buf);
sprintf(buf, "-3: %4d right justif.\n", -3); printf("%s", buf);
return 0;
}
/*
* if you compile this file with
* gcc -Wall $(YOUR_C_OPTIONS) -DTEST_PRINTF -c printf.c
* you will get a normal warning:
* printf.c:214: warning: spurious trailing `%' in format
* this line is testing an invalid % at the end of the format string.
*
* this should display (on 32bit int machine) :
*
* Hello world!
* printf test
* (null) is null pointer
* 5 = 5
* -2147483647 = - max int
* char a = 'a'
* hex ff = ff
* hex 00 = 00
* signed -3 = unsigned 4294967293 = hex fffffffd
* 0 message(s)
* 0 message(s) with %
* justif: "left "
* justif: " right"
* 3: 0003 zero padded
* 3: 3 left justif.
* 3: 3 right justif.
* -3: -003 zero padded
* -3: -3 left justif.
* -3: -3 right justif.
*/
#endif
exlbt/input/start.cpp
#include "start.h"
extern int main();
// Real entry (first instruction) is from cpu0BootAtomContent of
// Cpu0RelocationPass.cpp jump to asm("start:") of start.cpp.
void start() {
asm("start:");
INIT_SP
initRegs();
main();
asm("addiu $lr, $ZERO, -1");
asm("ret $lr");
}
exlbt/input/lib_cpu0.c
// This file provides function symbols used for c++ in lld
void _start() {}
void __stack_chk_fail() {}
void __stack_chk_guard() {}
void _ZdlPv() {}
void __dso_handle() {}
void _ZNSt8ios_base4InitC1Ev() {}
void __cxa_atexit() {}
void _ZTVN10__cxxabiv120__si_class_type_infoE() {}
void _ZTVN10__cxxabiv117__class_type_infoE() {}
void _Znwm() {}
void __cxa_pure_virtual() {}
void ZNSt8ios_base4InitD1Ev() {}
exlbt/input/Common.mk
# Thanks https://makefiletutorial.com
TARGET_EXEC := a.out
BUILD_DIR := ./build-$(CPU)-$(ENDIAN)
TARGET := $(BUILD_DIR)/$(TARGET_EXEC)
SRC_DIR := ./
TOOLDIR := ~/llvm/test/build/bin
CC := $(TOOLDIR)/clang
LLC := $(TOOLDIR)/llc
LD := $(TOOLDIR)/ld.lld
AS := $(TOOLDIR)/clang -static -fintegrated-as -c
RANLIB := $(TOOLDIR)/llvm-ranlib
READELF := $(TOOLDIR)/llvm-readelf
# String substitution for every C/C++ file.
# As an example, hello.cpp turns into ./build/hello.cpp.o
OBJS := $(SRCS:%=$(BUILD_DIR)/%.o)
# String substitution (suffix version without %).
# As an example, ./build/hello.cpp.o turns into ./build/hello.cpp.d
DEPS := $(OBJS:.o=.d)
# Add a prefix to INC_DIRS. So moduleA would become -ImoduleA. GCC understands
# this -I flag
INC_FLAGS := $(addprefix -I,$(INC_DIRS))
# The -MMD and -MP flags together generate Makefiles for us!
# These files will have .d instead of .o as the output.
# fintegrated-as: for asm code in C/C++
CPPFLAGS := -MMD -MP -target cpu0$(ENDIAN)-unknown-linux-gnu -static \
-fintegrated-as $(INC_FLAGS) -march=cpu0$(ENDIAN) -mcpu=$(CPU) \
-mllvm -has-lld=true -DHAS_COMPLEX
LLFLAGS := -mcpu=$(CPU) -relocation-model=static \
-filetype=obj -has-lld=true
CFLAGS := -target cpu0$(ENDIAN)-unknown-linux-gnu -static -mcpu=$(CPU) \
-fintegrated-as -Wno-error=implicit-function-declaration
CONFIGURE := CC="$(CC)" CFLAGS="$(CFAGS)" AS="$(AS)" RANLIB="$(RANLIB)" \
READELF="$(READELF)" ../newlib/configure --host=cpu0
#FIND_LIBBUILTINS_DIR := $(shell find . -iname $(LIBBUILTINS_DIR))
$(TARGET): $(OBJS) $(LIBS)
$(LD) -o $@ $(OBJS) $(LIBS)
$(LIBS):
ifdef LIBBUILTINS_DIR
$(MAKE) -C $(LIBBUILTINS_DIR)
endif
ifdef NEWLIB_DIR
$(MAKE) -C $(NEWLIB_DIR)/$(BUILD_DIR)
endif
# Build step for C source
$(BUILD_DIR)/%.c.o: %.c
mkdir -p $(dir $@)
$(CC) $(CPPFLAGS) $(CFLAGS) -c $< -o $@
# Build step for C++ source
$(BUILD_DIR)/%.cpp.o: %.cpp
mkdir -p $(dir $@)
$(CC) $(CPPFLAGS) $(CXXFLAGS) -c $< -o $@
.PHONY: clean
clean:
rm -rf $(BUILD_DIR)
ifdef LIBBUILTINS_DIR
cd $(LIBBUILTINS_DIR) && $(MAKE) -f Makefile clean
endif
ifdef NEWLIB_DIR
cd $(NEWLIB_DIR) && rm -rf build-$(CPU)-$(ENDIAN)/*
endif
# Include the .d makefiles. The - at the f.cnt suppresses the er.crs.cf missing
# Makefiles. Initially, all the .d files will be missing, and we .cn't want t.cse
# er.crs .c s.cw up.
-include $(DEPS)
With the printf() function from the GPL source code, we can write more test
code to verify the previously generated LLVM Cpu0 backend program. The
following code serves this purpose.
exlbt/input/debug.cpp
#include "debug.h"
extern "C" int printf(const char *format, ...);
// With read variable form asm, such as sw in this example, the function,
// ISR_Handler() must entry from beginning. The ISR() enter from "ISR:" will
// has incorrect value for reload instruction in offset.
// For example, the correct one is:
// "addiu $sp, $sp, -12"
// "mov $fp, $sp"
// ISR:
// "ld $2, 32($fp)"
// Go to ISR directly, then the $fp is 12+ than original, then it will get
// "ld $2, 20($fp)" actually.
void ISR_Handler() {
SAVE_REGISTERS;
asm("lui $7, 0xffff");
asm("ori $7, $7, 0xfdff");
asm("and $sw, $sw, $7"); // clear `IE
volatile int sw;
__asm__ __volatile__("addiu %0, $sw, 0"
:"=r"(sw)
);
int interrupt = (sw & INT);
int softint = (sw & SOFTWARE_INT);
int overflow = (sw & OVERFLOW);
int int1 = (sw & INT1);
int int2 = (sw & INT2);
if (interrupt) {
if (softint) {
if (overflow) {
printf("Overflow exception\n");
CLEAR_OVERFLOW;
}
else {
printf("Software interrupt\n");
}
CLEAR_SOFTWARE_INT;
}
else if (int1) {
printf("Harware interrupt 0\n");
asm("lui $7, 0xffff");
asm("ori $7, $7, 0x7fff");
asm("and $sw, $sw, $7");
}
else if (int2) {
printf("Harware interrupt 1\n");
asm("lui $7, 0xfffe");
asm("ori $7, $7, 0xffff");
asm("and $sw, $sw, $7");
}
asm("lui $7, 0xffff");
asm("ori $7, $7, 0xdfff");
asm("and $sw, $sw, $7"); // clear `I
}
asm("ori $sw, $sw, 0x200"); // int enable
RESTORE_REGISTERS;
return;
}
void ISR() {
asm("ISR:");
asm("lui $at, 7");
asm("ori $at, $at, 0xff00");
asm("st $14, 48($at)");
ISR_Handler();
asm("lui $at, 7");
asm("ori $at, $at, 0xff00");
asm("ld $14, 48($at)");
asm("c0mov $pc, $epc");
}
void int_sim() {
asm("ori $sw, $sw, 0x200"); // int enable
asm("ori $sw, $sw, 0x2000"); // set interrupt
asm("ori $sw, $sw, 0x4000"); // Software interrupt
asm("ori $sw, $sw, 0x200"); // int enable
asm("ori $sw, $sw, 0x2000"); // set interrupt
asm("ori $sw, $sw, 0x8000"); // hardware interrupt 0
asm("ori $sw, $sw, 0x200"); // int enable
asm("ori $sw, $sw, 0x2000"); // set interrupt
asm("lui $at, 1");
asm("or $sw, $sw, $at"); // hardware interrupt 1
return;
}
exlbt/input/ch_lld_staticlink.h
#include "debug.h"
#include "print.h"
//#define PRINT_TEST
extern "C" int printf(const char *format, ...);
extern "C" int sprintf(char *out, const char *format, ...);
extern unsigned char sBuffer[4];
extern int test_overflow();
extern int test_add_overflow();
extern int test_sub_overflow();
extern int test_ctrl2();
extern int test_phinode(int a, int b, int c);
extern int test_blockaddress(int x);
extern int test_longbranch();
extern int test_func_arg_struct();
extern int test_tailcall(int a);
extern bool exceptionOccur;
extern int test_detect_exception(bool exception);
extern int test_staticlink();
exlbt/input/ch_lld_staticlink.cpp
#include "ch4_1_addsuboverflow.cpp"
#include "ch8_1_br_jt.cpp"
#include "ch8_2_phinode.cpp"
#include "ch8_1_blockaddr.cpp"
#include "ch8_2_longbranch.cpp"
#include "ch9_2_tailcall.cpp"
#include "ch9_3_detect_exception.cpp"
void test_printf() {
char ptr[] = "Hello world!";
char *np = 0;
int i = 5;
unsigned int bs = sizeof(int)*8;
int mi;
char buf[80];
mi = (1 << (bs-1)) + 1;
printf("%s\n", ptr);
printf("printf test\n");
printf("%s is null pointer\n", np);
printf("%d = 5\n", i);
printf("%d = - max int\n", mi);
printf("char %c = 'a'\n", 'a');
printf("hex %x = ff\n", 0xff);
printf("hex %02x = 00\n", 0);
printf("signed %d = unsigned %u = hex %x\n", -3, -3, -3);
printf("%d %s(s)", 0, "message");
printf("\n");
printf("%d %s(s) with %%\n", 0, "message");
sprintf(buf, "justif: \"%-10s\"\n", "left"); printf("%s", buf);
sprintf(buf, "justif: \"%10s\"\n", "right"); printf("%s", buf);
sprintf(buf, " 3: %04d zero padded\n", 3); printf("%s", buf);
sprintf(buf, " 3: %-4d left justif.\n", 3); printf("%s", buf);
sprintf(buf, " 3: %4d right justif.\n", 3); printf("%s", buf);
sprintf(buf, "-3: %04d zero padded\n", -3); printf("%s", buf);
sprintf(buf, "-3: %-4d left justif.\n", -3); printf("%s", buf);
sprintf(buf, "-3: %4d right justif.\n", -3); printf("%s", buf);
}
void verify_test_ctrl2()
{
int a = -1;
int b = -1;
int c = -1;
int d = -1;
sBuffer[0] = (unsigned char)0x35;
sBuffer[1] = (unsigned char)0x35;
a = test_ctrl2();
sBuffer[0] = (unsigned char)0x30;
sBuffer[1] = (unsigned char)0x29;
b = test_ctrl2();
sBuffer[0] = (unsigned char)0x35;
sBuffer[1] = (unsigned char)0x35;
c = test_ctrl2();
sBuffer[0] = (unsigned char)0x34;
d = test_ctrl2();
printf("test_ctrl2(): a = %d, b = %d, c = %d, d = %d", a, b, c, d);
if (a == 1 && b == 0 && c == 1 && d == 0)
printf(", PASS\n");
else
printf(", FAIL\n");
return;
}
int test_staticlink()
{
int a = 0;
// pre-defined compiler macro (from llc -march=cpu0${ENDIAN} or
// clang -target cpu0${ENDIAN}-unknown-linux-gnu
// http://beefchunk.com/documentation/lang/c/pre-defined-c/prearch.html
#ifdef __CPU0EB__
printf("__CPU0EB__\n");
#endif
#ifdef __CPU0EL__
printf("__CPU0EL__\n");
#endif
test_printf();
a = test_add_overflow();
a = test_sub_overflow();
a = test_global(); // gI = 100
printf("global variable gI = %d", a);
if (a == 100)
printf(", PASS\n");
else
printf(", FAIL\n");
verify_test_ctrl2();
a = test_phinode(3, 1, 0);
printf("test_phinode(3, 1) = %d", a); // a = 3
if (a == 3)
printf(", PASS\n");
else
printf(", FAIL\n");
a = test_blockaddress(1);
printf("test_blockaddress(1) = %d", a); // a = 1
if (a == 1)
printf(", PASS\n");
else
printf(", FAIL\n");
a = test_blockaddress(2);
printf("test_blockaddress(2) = %d", a); // a = 2
if (a == 2)
printf(", PASS\n");
else
printf(", FAIL\n");
a = test_longbranch();
printf("test_longbranch() = %d", a); // a = 0
if (a == 0)
printf(", PASS\n");
else
printf(", FAIL\n");
a = test_func_arg_struct();
printf("test_func_arg_struct() = %d", a); // a = 0
if (a == 0)
printf(", PASS\n");
else
printf(", FAIL\n");
a = test_constructor();
printf("test_constructor() = %d", a); // a = 0
if (a == 0)
printf(", PASS\n");
else
printf(", FAIL\n");
a = test_template();
printf("test_template() = %d", a); // a = 15
if (a == 15)
printf(", PASS\n");
else
printf(", FAIL\n");
long long res = test_template_ll();
printf("test_template_ll() = 0x%X-%X", (int)(res>>32), (int)res); // res = -1
if (res == -1)
printf(", PASS\n");
else
printf(", FAIL\n");
a = test_tailcall(5);
printf("test_tailcall(5) = %d", a); // a = 15
if (a == 120)
printf(", PASS\n");
else
printf(", FAIL\n");
test_detect_exception(true);
printf("exceptionOccur= %d", exceptionOccur);
if (exceptionOccur)
printf(", PASS\n");
else
printf(", FAIL\n");
test_detect_exception(false);
printf("exceptionOccur= %d", exceptionOccur);
if (!exceptionOccur)
printf(", PASS\n");
else
printf(", FAIL\n");
a = inlineasm_global(); // 4
printf("inlineasm_global() = %d", a); // a = 4
if (a == 4)
printf(", PASS\n");
else
printf(", FAIL\n");
a = test_cpp_polymorphism();
printf("test_cpp_polymorphism() = %d", a); // a = 0
if (a == 0)
printf(", PASS\n");
else
printf(", FAIL\n");
int_sim();
return 0;
}
// test passing compilation only
#include "builtins-cpu0.c"
exlbt/input/ch_slinker.cpp
#include "ch_nolld.h"
#include "ch_lld_staticlink.h"
int main()
{
bool pass = true;
pass = test_nolld();
if (pass)
printf("test_nolld(): PASS\n");
else
printf("test_nolld(): FAIL\n");
pass = true;
pass = test_staticlink();
return pass;
}
#include "ch_nolld.cpp"
#include "ch_lld_staticlink.cpp"
exlbt/input/Makefile.slinker
SRCS := start.cpp debug.cpp printf-stdarg-def.c printf-stdarg.c ch_slinker.cpp \
lib_cpu0.c
INC_DIRS := $(SRC_DIR) $(LBDEX_DIR)/input
LIBBUILTINS_DIR :=
LIBS :=
include Common.mk
exlbt/input/make.sh
#!/usr/bin/env bash
# for example:
# bash make.sh cpu032I eb Makefile.newlib
# bash make.sh cpu032I eb Makefile.builtins
# bash make.sh cpu032I el Makefile.slinker
# bash make.sh cpu032II eb Makefile.float
# bash make.sh cpu032II el Makefile.ch13_1
LBDEX_DIR=$HOME/git/lbd/lbdex
NEWLIB_DIR=$HOME/git/newlib-cygwin
ARG_NUM=$#
CPU=$1
ENDIAN=$2
MKFILE=$3
BUILD_DIR=build-$CPU-$ENDIAN
build_newlib() {
pushd $NEWLIB_DIR
rm -rf $BUILD_DIR
mkdir $BUILD_DIR
cd build
CC=$TOOLDIR/clang \
CFLAGS="-target cpu0$ENDIAN-unknown-linux-gnu -mcpu=$CPU -static \
-fintegrated-as -Wno-error=implicit-function-declaration" \
AS="$TOOLDIR/clang -static -fintegrated-as -c" \
AR="$TOOLDIR/llvm-ar" RANLIB="$TOOLDIR/llvm-ranlib" \
READELF="$TOOLDIR/llvm-readelf" ../newlib/configure --host=cpu0
make
popd
}
checkCommand() {
echo "ARG_NUM: $ARG_NUM"
if [ $ARG_NUM != 3 ]; then
echo "useage: bash make.sh cpu_type endian makefilename"
echo " cpu_type: cpu032I or cpu032II"
echo " endian: be (big ENDIAN, default) or le (little ENDIAN)"
echo " makefilename: e.g. Makefile.slinker"
echo "for example:"
echo " make.sh cpu032I el Makefile.slinker"
exit 1;
fi
if [ $CPU != cpu032I ] && [ $CPU != cpu032II ]; then
echo "1st argument is cpu032I or cpu032II"
exit 1
fi
if [ ! -f "$FILE" ]; then
echo "$FILE does not exists."
exit 0;
fi
}
prologue() {
INCDIR=../../lbdex/input
OS=`uname -s`
echo "OS =" ${OS}
TOOLDIR=~/llvm/test/build/bin
CLANG=~/llvm/test/build/bin/clang
echo "CPU =" "${CPU}"
echo "ENDIAN =" "${ENDIAN}"
if [ $ENDIAN != eb ] && [ $ENDIAN != el ]; then
echo "2nd argument is be (big ENDIAN, default) or le (little ENDIAN)"
exit 1
fi
if [ $MKFILE == "Makefile.newlib" ] || [ $MKFILE == "Makefile.builtins" ]; then
echo "build_newlib"
# build_newlib;
fi
rm $BUILD_DIR/a.out
}
isLittleEndian() {
echo "ENDIAN = " "$ENDIAN"
if [ "$ENDIAN" == "LittleEndian" ] ; then
LE="true"
elif [ "$ENDIAN" == "BigEndian" ] ; then
LE="false"
else
echo "!ENDIAN unknown"
exit 1
fi
}
elf2hex() {
${TOOLDIR}/elf2hex -le=$LE $BUILD_DIR/a.out > ${LBDEX_DIR}/verilog/cpu0.hex
if [ $LE == "true" ] ; then
echo "1 /* 0: big ENDIAN, 1: little ENDIAN */" > ${LBDEX_DIR}/verilog/cpu0.config
else
echo "0 /* 0: big ENDIAN, 1: little ENDIAN */" > ${LBDEX_DIR}/verilog/cpu0.config
fi
cat ${LBDEX_DIR}/verilog/cpu0.config
}
epilogue() {
ENDIAN=`${TOOLDIR}/llvm-readobj -h $BUILD_DIR/a.out|grep "DataEncoding"|awk '{print $2}'`
isLittleEndian;
elf2hex;
}
FILE=$3
checkCommand
prologue;
make -f $FILE CPU=${CPU} ENDIAN=${ENDIAN} LBDEX_DIR=${LBDEX_DIR} NEWLIB_DIR=${NEWLIB_DIR} clean
make -f $FILE CPU=${CPU} ENDIAN=${ENDIAN} LBDEX_DIR=${LBDEX_DIR} NEWLIB_DIR=${NEWLIB_DIR}
epilogue;
$ cd ~/git/lbd/lbdex/verilog
$ make
$ cd ~/git/lbt/exlbt/input
$ pwd
$HOME/git/lbt/exlbt/input
$ bash make.sh cpu032I el Makefile.slinker
...
endian = LittleEndian
ISR address:00020780
1 /* 0: big endian, 1: little endian */
$ cd ~/git/lbd/lbdex/verilog
$ pwd
$HOME/git/lbd/lbdex/verilog
$ ./cpu0Is
WARNING: cpu0.v:487: $readmemh(cpu0.hex): Not enough words in the file for the requested range [0:524287].
taskInterrupt(001)
74
7
0
0
253
3
1
13
3
-126
130
-32766
32770
393307
16777222
-3
-4
51
2
3
1
2147483647
-2147483648
9
12
5
0
31
49
test_nolld(): PASS
__CPU0EL__
Hello world!
printf test
(null) is null pointer
5 = 5
-2147483647 = - max int
char a = 'a'
hex ff = ff
hex 00 = 00
signed -3 = unsigned 4294967293 = hex fffffffd
0 message(s)
0 message(s) with %
justif: "left "
justif: " right"
3: 0003 zero padded
3: 3 left justif.
3: 3 right justif.
-3: -003 zero padded
-3: -3 left justif.
-3: -3 right justif.
global variable gI = 100, PASS
test_ctrl2(): a = 1, b = 0, c = 1, d = 0, PASS
test_phinode(3, 1) = 3, PASS
test_blockaddress(1) = 1, PASS
test_blockaddress(2) = 2, PASS
test_longbranch() = 0, PASS
test_func_arg_struct() = 0, PASS
test_constructor() = 0, PASS
test_template() = 15, PASS
test_template_ll() = 0xFFFFFFFF-FFFFFFFF, PASS
test_tailcall(5) = 120, PASS
exceptionOccur= 1, PASS
exceptionOccur= 0, PASS
inlineasm_global() = 4, PASS
20
10
5
test_cpp_polymorphism() = 0, PASS
taskInterrupt(011)
Software interrupt
taskInterrupt(011)
Harware interrupt 0
taskInterrupt(011)
Harware interrupt 1
...
RET to PC < 0, finished!
The above test includes verification of the printf format.
Let’s check the result by comparing it with the output of the PC program
printf-stdarg-1.c as follows,
$ cd ~/git/lbt/exlbt/input
$ pwd
$HOME/git/lbt/exlbt/input
$ clang printf-stdarg-1.c
printf-stdarg-1.c:58:19: warning: incomplete format specifier [-Wformat]
printf("%d %s(s)%", 0, "message");
^
1 warning generated.
$ ./a.out
Hello world!
printf test
(null) is null pointer
5 = 5
-2147483647 = - max int
char a = 'a'
hex ff = ff
hex 00 = 00
signed -3 = unsigned 4294967293 = hex fffffffd
0 message(s)
0 message(s) with \%
justif: "left "
justif: " right"
3: 0003 zero padded
3: 3 left justif.
3: 3 right justif.
-3: -003 zero padded
-3: -3 left justif.
-3: -3 right justif.
As described above, by leveraging open source code, Cpu0 gained a more stable
implementation of the printf() function. Once the Cpu0 backend can translate
the open source C printf() program into machine instructions, the LLVM
Cpu0 backend can be effectively verified using printf().
With the high-quality open source printf() code, the Cpu0 toolchain extends
from just a compiler backend to also support the C standard library.
(Note that while some GPL open source code may be of lower quality, many are
well-written.)
The message “Overflow exception is printed twice” means the ISR() in
debug.cpp is called twice from ch4_1_2.cpp.
The printed messages taskInterrupt(001) and taskInterrupt(011) are just
trace messages from cpu0.v code.
Dynamic linker¶
The dynamic linker demonstration was removed from version 3.9.0 because its
implementation with lld 3.9 was unclear and required extensive additions to
elf2hex, Verilog, and the Cpu0 backend in lld.
However, it can still be run with LLVM 3.7 using the following command.
1-160-136-173:test Jonathan$ pwd
/Users/Jonathan/test
1-160-136-173:test Jonathan$ git clone https://github.com/Jonathan2251/lbd
1-160-136-173:test Jonathan$ git clone https://github.com/Jonathan2251/lbt
1-160-136-173:test Jonathan$ cd lbd
1-160-136-173:lbd Jonathan$ pwd
/Users/Jonathan/test/lbd
1-160-136-173:lbd Jonathan$ git checkout release_374
1-160-136-173:lbd Jonathan$ cd ../lbt
1-160-136-173:test Jonathan$ git checkout release_374
1-160-136-173:lbt Jonathan$ make html
Then read the corresponding section in lld.html for more details.
Summary¶
Create a new backend based on LLVM¶
Thanks to the LLVM open source project, writing a linker and ELF-to-Hex tools for a new CPU architecture is both easy and reliable.
Combined with the LLVM Cpu0 backend code and Verilog code programmed in previous chapters, we designed a software toolchain to compile C/C++ code, link it, and run it on the Verilog Cpu0 simulator without any real hardware investment.
If you buy FPGA development hardware, we believe this code can run on an FPGA CPU even though we did not test it ourselves.
Extending system programming toolchains to support a new CPU instruction set can be completed just like we have shown here.
School knowledge of system programming, compiler, linker, loader, computer architecture, and CPU design has been translated into real work and demonstrated running in practice. Now this knowledge is not limited to paper.
We designed it, programmed it, and ran it in the real world.
The total code size of the LLVM Cpu0 backend compiler, Cpu0 LLD linker, elf2hex, and Cpu0 Verilog code is around 10,000 lines including comments.
In comparison, the total code size of Clang, LLVM, and LLD exceeds 1,000,000 lines excluding tests and documentation.
This means the Cpu0 backend, based on Clang, LLVM, and LLD, is only about 1% of the size of the entire infrastructure.
Moreover, the LLVM Cpu0 backend and LLD Cpu0 backend share about 70% similarity with LLVM MIPS.
Based on this fact, we believe LLVM has a well-defined architecture for compiler design.
Contribute Back to Open Source Through Working and Learning¶
Finally, 10,000 lines of source code in the Cpu0 backend is very small for a UI program, but it is quite complex for system programming based on LLVM. Open source code gives programmers the best opportunity to understand, enhance, and extend the code. However, documentation is the next most important factor to improve open source development.
The Open Source Organization recognized this and started the Open Source Document Project [4] [5] [6] [7] [8]. Open Source has grown into a giant software infrastructure powered by companies [9] [10], academic research, and countless passionate engineers.
It has ended the era when everyone tried to reinvent the wheel. Extending your software from reusable source code is the right way. Of course, if you work in business, you should consider open source licensing.
Anyone can contribute back to open source through the learning process. This book was written by learning the LLVM backend and contributing back to the LLVM open source project.
We believe this book cannot exist in traditional paper form, since few readers are interested in studying LLVM backend, despite many compiler books published. Therefore, it is published electronically and tries to follow the Open Document License Exception [11].
There is a gap between concept and realistic program implementation. For learning a large, complex software such as the LLVM backend the concept of compiler knowledge alone is not enough.
We all learned knowledge through books in and after school. If you cannot find a good way to produce documentation, consider writing documents like this book. This book’s documentation uses the Sphinx tool, just like the LLVM development team. Sphinx uses the restructured text format here [12] [13] [14].
Appendix A of the lbd book explains how to install the Sphinx tool.
Documentation work helps you re-examine your software and improve your program structure, reliability, and—most importantly—extend your code to places you did not expect.