C++ support¶
This chapter supports some C++ compiler features.
Exception Handling¶
Chapter11_2 can be built and run using the C++ polymorphism example code in
ch12_inherit.cpp as follows:
lbdex/input/ch12_inherit.cpp
...
class CPolygon { // _ZTVN10__cxxabiv117__class_type_infoE for parent class
...
#ifdef COUT_TEST
// generate IR nvoke, landing, resume and unreachable on iMac
{ cout << this->area() << endl; }
#else
{ printf("%d\n", this->area()); }
#endif
};
...
If you use cout instead of printf in ch12_inherit.cpp, it will not
generate exception handling IR on Linux. However, it will generate exception
handling IRs such as invoke, landingpad, resume, and
unreachable on iMac.
The example code ch12_eh.cpp, which includes try and catch
exception handling, will generate these exception-related IRs on both iMac
and Linux.
lbdex/input/ch12_eh.cpp
class Ex1 {};
void throw_exception(int a, int b) {
Ex1 ex1;
if (a > b) {
throw ex1;
}
}
int test_try_catch() {
try {
throw_exception(2, 1);
}
catch(...) {
return 1;
}
return 0;
}
JonathantekiiMac:input Jonathan$ clang -c ch12_eh.cpp -emit-llvm
-o ch12_eh.bc
JonathantekiiMac:input Jonathan$ /Users/Jonathan/llvm/test/build/
bin/llvm-dis ch12_eh.bc -o -
../lbdex/output/ch12_eh.ll
...
define dso_local i32 @_Z14test_try_catchv() #0 personality i8* bitcast (i32 (...
)* @__gxx_personality_v0 to i8*) {
entry:
...
invoke void @_Z15throw_exceptionii(i32 signext 2, i32 signext 1)
to label %invoke.cont unwind label %lpad
invoke.cont: ; preds = %entry
br label %try.cont
lpad: ; preds = %entry
%0 = landingpad { i8*, i32 }
catch i8* null
...
}
...
JonathantekiiMac:input Jonathan$ /Users/Jonathan/llvm/test/build/
bin/llc -march=cpu0 -relocation-model=static -filetype=asm ch12_eh.bc -o -
.section .mdebug.abi32
.previous
.file "ch12_eh.bc"
llc: /Users/Jonathan/llvm/test/llvm/lib/CodeGen/LiveVariables.cpp:133: void llvm::
LiveVariables::HandleVirtRegUse(unsigned int, llvm::MachineBasicBlock *, llvm
::MachineInstr *): Assertion `MRI->getVRegDef(reg) && "Register use before
def!"' failed.
A description of the C++ exception table formats can be found here [2].
For details about the LLVM IR used in exception handling, please refer to [1].
Chapter12_1 supports the LLVM IRs that correspond to the C++ try and
catch keywords. It can compile ch12_eh.bc as follows:
lbdex/chapters/Chapter12_1/Cpu0ISelLowering.h
/// If a physical register, this returns the register that receives the
/// exception address on entry to an EH pad.
Register
getExceptionPointerRegister(const Constant *PersonalityFn) const override {
return Cpu0::A0;
}
/// If a physical register, this returns the register that receives the
/// exception typeid on entry to a landing pad.
Register
getExceptionSelectorRegister(const Constant *PersonalityFn) const override {
return Cpu0::A1;
}
JonathantekiiMac:input Jonathan$ /Users/Jonathan/llvm/test/build/
bin/llc -march=cpu0 -relocation-model=static -filetype=asm ch12_eh.bc -o -
../lbdex/output/ch12_eh.cpu0.s
.type _Z14test_try_catchv,@function
.ent _Z14test_try_catchv # @_Z14test_try_catchv
_Z14test_try_catchv:
...
$tmp0:
addiu $4, $zero, 2
addiu $5, $zero, 1
jsub _Z15throw_exceptionii
nop
$tmp1:
# %bb.1: # %invoke.cont
jmp $BB1_4
$BB1_2: # %lpad
$tmp2:
st $4, 16($fp)
st $5, 12($fp)
# %bb.3: # %catch
ld $4, 16($fp)
jsub __cxa_begin_catch
nop
addiu $2, $zero, 1
st $2, 20($fp)
jsub __cxa_end_catch
nop
jmp $BB1_5
$BB1_4: # %try.cont
addiu $2, $zero, 0
st $2, 20($fp)
$BB1_5: # %return
ld $2, 20($fp)
...
Thread variable¶
C++ support thread variable as the following file ch12_thread_var.cpp.
lbdex/input/ch12_thread_var.cpp
__thread int a = 0;
thread_local int b = 0; // need option -std=c++11
int test_thread_var()
{
a = 2;
return a;
}
int test_thread_var_2()
{
b = 3;
return b;
}
While a global variable is a single instance shared by all threads in a process, a thread-local variable has a separate instance for each thread in the process. The same thread accesses the same instance of the thread-local variable, while different threads have their own instances with the same variable name [3].
To support thread-local variables, symbols such as tlsgd, tlsldm, dtp_hi, dtp_lo, gottp, tp_hi, and tp_lo must be handled in both evaluateRelocExpr() of Cpu0AsmParser.cpp and printImpl() of Cpu0MCExpr.cpp.
Most of these symbols are used for relocation record handling, because the actual thread-local storage is created by the OS or language runtime that supports multi-threaded programming.
lbdex/chapters/Chapter12_1/MCTargetDesc/Cpu0AsmBackend.cpp
const MCFixupKindInfo &Cpu0AsmBackend::
getFixupKindInfo(MCFixupKind Kind) const {
unsigned JSUBReloRec = 0;
if (HasLLD) {
JSUBReloRec = MCFixupKindInfo::FKF_IsPCRel;
}
else {
JSUBReloRec = MCFixupKindInfo::FKF_IsPCRel | MCFixupKindInfo::FKF_Constant;
}
const static MCFixupKindInfo Infos[Cpu0::NumTargetFixupKinds] = {
// This table *must* be in same the order of fixup_* kinds in
// Cpu0FixupKinds.h.
//
// name offset bits flags
{ "fixup_Cpu0_TLSGD", 0, 16, 0 },
{ "fixup_Cpu0_GOTTP", 0, 16, 0 },
{ "fixup_Cpu0_TP_HI", 0, 16, 0 },
{ "fixup_Cpu0_TP_LO", 0, 16, 0 },
{ "fixup_Cpu0_TLSLDM", 0, 16, 0 },
{ "fixup_Cpu0_DTP_HI", 0, 16, 0 },
{ "fixup_Cpu0_DTP_LO", 0, 16, 0 },
...
};
...
}
lbdex/chapters/Chapter12_1/MCTargetDesc/Cpu0BaseInfo.h
namespace Cpu0II {
/// Target Operand Flag enum.
enum TOF {
//===------------------------------------------------------------------===//
// Cpu0 Specific MachineOperand flags.
/// MO_TLSGD - Represents the offset into the global offset table at which
// the module ID and TSL block offset reside during execution (General
// Dynamic TLS).
MO_TLSGD,
/// MO_TLSLDM - Represents the offset into the global offset table at which
// the module ID and TSL block offset reside during execution (Local
// Dynamic TLS).
MO_TLSLDM,
MO_DTP_HI,
MO_DTP_LO,
/// MO_GOTTPREL - Represents the offset from the thread pointer (Initial
// Exec TLS).
MO_GOTTPREL,
/// MO_TPREL_HI/LO - Represents the hi and low part of the offset from
// the thread pointer (Local Exec TLS).
MO_TP_HI,
MO_TP_LO,
...
};
...
}
lbdex/chapters/Chapter12_1/MCTargetDesc/Cpu0ELFObjectWriter.cpp
unsigned Cpu0ELFObjectWriter::getRelocType(MCContext &Ctx,
const MCValue &Target,
const MCFixup &Fixup,
bool IsPCRel) const {
// determine the type of the relocation
unsigned Type = (unsigned)ELF::R_CPU0_NONE;
unsigned Kind = (unsigned)Fixup.getKind();
switch (Kind) {
case Cpu0::fixup_Cpu0_TLSGD:
Type = ELF::R_CPU0_TLS_GD;
break;
case Cpu0::fixup_Cpu0_GOTTPREL:
Type = ELF::R_CPU0_TLS_GOTTPREL;
break;
...
}
lbdex/chapters/Chapter12_1/MCTargetDesc/Cpu0FixupKinds.h
enum Fixups {
// resulting in - R_CPU0_TLS_GD.
fixup_Cpu0_TLSGD,
// resulting in - R_CPU0_TLS_GOTTPREL.
fixup_Cpu0_GOTTPREL,
// resulting in - R_CPU0_TLS_TPREL_HI16.
fixup_Cpu0_TP_HI,
// resulting in - R_CPU0_TLS_TPREL_LO16.
fixup_Cpu0_TP_LO,
// resulting in - R_CPU0_TLS_LDM.
fixup_Cpu0_TLSLDM,
// resulting in - R_CPU0_TLS_DTP_HI16.
fixup_Cpu0_DTP_HI,
// resulting in - R_CPU0_TLS_DTP_LO16.
fixup_Cpu0_DTP_LO,
...
};
lbdex/chapters/Chapter12_1/MCTargetDesc/Cpu0MCCodeEmitter.cpp
unsigned Cpu0MCCodeEmitter::
getExprOpValue(const MCExpr *Expr,SmallVectorImpl<MCFixup> &Fixups,
const MCSubtargetInfo &STI) const {
case Cpu0MCExpr::CEK_TLSGD:
FixupKind = Cpu0::fixup_Cpu0_TLSGD;
break;
case Cpu0MCExpr::CEK_TLSLDM:
FixupKind = Cpu0::fixup_Cpu0_TLSLDM;
break;
case Cpu0MCExpr::CEK_DTP_HI:
FixupKind = Cpu0::fixup_Cpu0_DTP_HI;
break;
case Cpu0MCExpr::CEK_DTP_LO:
FixupKind = Cpu0::fixup_Cpu0_DTP_LO;
break;
case Cpu0MCExpr::CEK_GOTTPREL:
FixupKind = Cpu0::fixup_Cpu0_GOTTPREL;
break;
case Cpu0MCExpr::CEK_TP_HI:
FixupKind = Cpu0::fixup_Cpu0_TP_HI;
break;
case Cpu0MCExpr::CEK_TP_LO:
FixupKind = Cpu0::fixup_Cpu0_TP_LO;
break;
...
}
lbdex/chapters/Chapter12_1/Cpu0InstrInfo.td
// TlsGd node is used to handle General Dynamic TLS
def Cpu0TlsGd : SDNode<"Cpu0ISD::TlsGd", SDTIntUnaryOp>;
// TpHi and TpLo nodes are used to handle Local Exec TLS
def Cpu0TpHi : SDNode<"Cpu0ISD::TpHi", SDTIntUnaryOp>;
def Cpu0TpLo : SDNode<"Cpu0ISD::TpLo", SDTIntUnaryOp>;
let Predicates = [Ch12_1] in {
def : Pat<(Cpu0Hi tglobaltlsaddr:$in), (LUi tglobaltlsaddr:$in)>;
}
let Predicates = [Ch12_1] in {
def : Pat<(Cpu0Lo tglobaltlsaddr:$in), (ORi ZERO, tglobaltlsaddr:$in)>;
}
let Predicates = [Ch12_1] in {
def : Pat<(add CPURegs:$hi, (Cpu0Lo tglobaltlsaddr:$lo)),
(ORi CPURegs:$hi, tglobaltlsaddr:$lo)>;
}
let Predicates = [Ch12_1] in {
def : WrapperPat<tglobaltlsaddr, ORi, CPURegs>;
}
lbdex/chapters/Chapter12_1/Cpu0SelLowering.cpp
Cpu0TargetLowering::Cpu0TargetLowering(const Cpu0TargetMachine &TM,
const Cpu0Subtarget &STI)
: TargetLowering(TM), Subtarget(STI), ABI(TM.getABI()) {
setOperationAction(ISD::GlobalTLSAddress, MVT::i32, Custom);
...
}
SDValue Cpu0TargetLowering::
LowerOperation(SDValue Op, SelectionDAG &DAG) const
{
switch (Op.getOpcode())
{
case ISD::GlobalTLSAddress: return lowerGlobalTLSAddress(Op, DAG);
...
}
...
}
SDValue Cpu0TargetLowering::
lowerGlobalTLSAddress(SDValue Op, SelectionDAG &DAG) const
{
// If the relocation model is PIC, use the General Dynamic TLS Model or
// Local Dynamic TLS model, otherwise use the Initial Exec or
// Local Exec TLS Model.
GlobalAddressSDNode *GA = cast<GlobalAddressSDNode>(Op);
if (DAG.getTarget().Options.EmulatedTLS)
return LowerToTLSEmulatedModel(GA, DAG);
SDLoc DL(GA);
const GlobalValue *GV = GA->getGlobal();
EVT PtrVT = getPointerTy(DAG.getDataLayout());
TLSModel::Model model = getTargetMachine().getTLSModel(GV);
if (model == TLSModel::GeneralDynamic || model == TLSModel::LocalDynamic) {
// General Dynamic and Local Dynamic TLS Model.
unsigned Flag = (model == TLSModel::LocalDynamic) ? Cpu0II::MO_TLSLDM
: Cpu0II::MO_TLSGD;
SDValue TGA = DAG.getTargetGlobalAddress(GV, DL, PtrVT, 0, Flag);
SDValue Argument = DAG.getNode(Cpu0ISD::Wrapper, DL, PtrVT,
getGlobalReg(DAG, PtrVT), TGA);
unsigned PtrSize = PtrVT.getSizeInBits();
IntegerType *PtrTy = Type::getIntNTy(*DAG.getContext(), PtrSize);
SDValue TlsGetAddr = DAG.getExternalSymbol("__tls_get_addr", PtrVT);
ArgListTy Args;
ArgListEntry Entry;
Entry.Node = Argument;
Entry.Ty = PtrTy;
Args.push_back(Entry);
TargetLowering::CallLoweringInfo CLI(DAG);
CLI.setDebugLoc(DL).setChain(DAG.getEntryNode())
.setCallee(CallingConv::C, PtrTy, TlsGetAddr, std::move(Args));
std::pair<SDValue, SDValue> CallResult = LowerCallTo(CLI);
SDValue Ret = CallResult.first;
if (model != TLSModel::LocalDynamic)
return Ret;
SDValue TGAHi = DAG.getTargetGlobalAddress(GV, DL, PtrVT, 0,
Cpu0II::MO_DTP_HI);
SDValue Hi = DAG.getNode(Cpu0ISD::Hi, DL, PtrVT, TGAHi);
SDValue TGALo = DAG.getTargetGlobalAddress(GV, DL, PtrVT, 0,
Cpu0II::MO_DTP_LO);
SDValue Lo = DAG.getNode(Cpu0ISD::Lo, DL, PtrVT, TGALo);
SDValue Add = DAG.getNode(ISD::ADD, DL, PtrVT, Hi, Ret);
return DAG.getNode(ISD::ADD, DL, PtrVT, Add, Lo);
}
SDValue Offset;
if (model == TLSModel::InitialExec) {
// Initial Exec TLS Model
SDValue TGA = DAG.getTargetGlobalAddress(GV, DL, PtrVT, 0,
Cpu0II::MO_GOTTPREL);
TGA = DAG.getNode(Cpu0ISD::Wrapper, DL, PtrVT, getGlobalReg(DAG, PtrVT),
TGA);
Offset =
DAG.getLoad(PtrVT, DL, DAG.getEntryNode(), TGA, MachinePointerInfo());
} else {
// Local Exec TLS Model
assert(model == TLSModel::LocalExec);
SDValue TGAHi = DAG.getTargetGlobalAddress(GV, DL, PtrVT, 0,
Cpu0II::MO_TP_HI);
SDValue TGALo = DAG.getTargetGlobalAddress(GV, DL, PtrVT, 0,
Cpu0II::MO_TP_LO);
SDValue Hi = DAG.getNode(Cpu0ISD::Hi, DL, PtrVT, TGAHi);
SDValue Lo = DAG.getNode(Cpu0ISD::Lo, DL, PtrVT, TGALo);
Offset = DAG.getNode(ISD::ADD, DL, PtrVT, Hi, Lo);
}
return Offset;
}
lbdex/chapters/Chapter12_1/Cpu0ISelLowering.h
SDValue lowerGlobalTLSAddress(SDValue Op, SelectionDAG &DAG) const;
lbdex/chapters/Chapter12_1/Cpu0MCInstLower.cpp
MCOperand Cpu0MCInstLower::LowerSymbolOperand(const MachineOperand &MO,
MachineOperandType MOTy,
unsigned Offset) const {
MCSymbolRefExpr::VariantKind Kind = MCSymbolRefExpr::VK_None;
Cpu0MCExpr::Cpu0ExprKind TargetKind = Cpu0MCExpr::CEK_None;
const MCSymbol *Symbol;
switch(MO.getTargetFlags()) {
case Cpu0II::MO_TLSGD:
TargetKind = Cpu0MCExpr::CEK_TLSGD;
break;
case Cpu0II::MO_TLSLDM:
TargetKind = Cpu0MCExpr::CEK_TLSLDM;
break;
case Cpu0II::MO_DTP_HI:
TargetKind = Cpu0MCExpr::CEK_DTP_HI;
break;
case Cpu0II::MO_DTP_LO:
TargetKind = Cpu0MCExpr::CEK_DTP_LO;
break;
case Cpu0II::MO_GOTTPREL:
TargetKind = Cpu0MCExpr::CEK_GOTTPREL;
break;
case Cpu0II::MO_TP_HI:
TargetKind = Cpu0MCExpr::CEK_TP_HI;
break;
case Cpu0II::MO_TP_LO:
TargetKind = Cpu0MCExpr::CEK_TP_LO;
break;
...
}
...
}
JonathantekiiMac:input Jonathan$ clang -target mips-unknown-linux-gnu -c
ch12_thread_var.cpp -emit-llvm -std=c++11 -o ch12_thread_var.bc
JonathantekiiMac:input Jonathan$ /Users/Jonathan/llvm/test/build/
bin/llvm-dis ch12_thread_var.bc -o -
../lbdex/output/ch12_thread_var.ll
...
@a = dso_local thread_local global i32 0, align 4
@b = dso_local thread_local global i32 0, align 4
; Function Attrs: noinline nounwind optnone mustprogress
define dso_local i32 @_Z15test_thread_varv() #0 {
entry:
store i32 2, i32* @a, align 4
%0 = load i32, i32* @a, align 4
ret i32 %0
}
; Function Attrs: noinline nounwind optnone mustprogress
define dso_local i32 @_Z17test_thread_var_2v() #0 {
entry:
store i32 3, i32* @b, align 4
%0 = load i32, i32* @b, align 4
ret i32 %0
}
...
JonathantekiiMac:input Jonathan$ /Users/Jonathan/llvm/test/build/
bin/llc -march=cpu0 -relocation-model=pic -filetype=asm ch12_thread_var.bc
-o ch12_thread_var.cpu0.pic.s
JonathantekiiMac:input Jonathan$ cat ch12_thread_var.cpu0.pic.s
../lbdex/output/ch12_thread_var.cpu0.pic.s
...
.ent _Z15test_thread_varv # @_Z15test_thread_varv
_Z15test_thread_varv:
...
ori $4, $gp, %tlsldm(a)
ld $t9, %call16(__tls_get_addr)($gp)
jalr $t9
nop
ld $gp, 8($fp)
lui $3, %dtp_hi(a)
addu $2, $3, $2
ori $2, $2, %dtp_lo(a)
...
In PIC (Position-Independent Code) mode, the __thread variable is accessed by calling the function __tls_get_addr with the address of the thread-local variable as an argument.
For C++11 thread_local variables, the compiler generates a call to the function _ZTW1b, which internally calls __tls_get_addr to retrieve the address of the thread_local variable.
In static mode, thread-local variables are accessed directly by loading their addresses using machine instructions. For example, variables a and b are accessed through direct address calculation instructions.
JonathantekiiMac:input Jonathan$ /Users/Jonathan/llvm/test/build/
bin/llc -march=cpu0 -relocation-model=static -filetype=asm
ch12_thread_var.bc -o ch12_thread_var.cpu0.static.s
JonathantekiiMac:input Jonathan$ cat ch12_thread_var.cpu0.static.s
../lbdex/output/ch12_thread_var.cpu0.static.s
...
lui $2, %tp_hi(a)
ori $2, $2, %tp_lo(a)
...
lui $2, %tp_hi(b)
ori $2, $2, %tp_lo(b)
...
While MIPS uses the rdhwr instruction to access thread-local variables, Cpu0 accesses thread-local variables without introducing any new instructions.
Thread-local variables in Cpu0 are stored in a dedicated thread-local memory region, which is accessed through %tp_hi and %tp_lo. This memory section is protected by the kernel, meaning it can only be accessed in kernel mode.
As a result, user-mode programs cannot access this memory region, leaving no room for potential exploits or malicious programs to interfere with thread-local storage.
JonathantekiiMac:input Jonathan$ /Users/Jonathan/llvm/test/build/
bin/llc -march=mips -relocation-model=static -filetype=asm
ch12_thread_var.bc -o -
...
lui $1, %tprel_hi(a)
ori $1, $1, %tprel_lo(a)
.set push
.set mips32r2
rdhwr $3, $29
.set pop
addu $1, $3, $1
addiu $2, $zero, 2
sw $2, 0($1)
addiu $2, $zero, 2
...
In static mode, the thread variable is similar to global variable. In general, they are same in IRs, DAGs and machine code translation. List them in the following tables. You can check them with debug option enabled.
In static mode, the thread variable behaves similarly to a global variable. In general, they are the same in terms of LLVM IR, DAG, and machine code translation.
You can refer to the following tables for a detailed comparison.
To observe this in action, compile and check with debug options enabled.
stage |
DAG |
|---|---|
IR |
load i32* @a, align 4; |
Legalized selection DAG |
(add Cpu0ISD::Hi Cpu0ISD::Lo); |
Instruction Selection |
ori $2, $zero, %tp_lo(a); |
lui $3, %tp_hi(a); |
|
addu $3, $3, $2; |
stage |
DAG |
|---|---|
IR |
ret i32* @b; |
Legalized selection DAG |
%0=(add Cpu0ISD::Hi Cpu0ISD::Lo);… |
Instruction Selection |
ori $2, $zero, %tp_lo(a); |
lui $3, %tp_hi(a); |
|
addu $3, $3, $2; |
C++ Memory Order [4] [5] [6]¶
Source Code Compatibility¶
Memory Order:
Memory Order is the rules that define how operations on shared memory appear to multiple threads — especially the ordering of reads/writes.
These rules ensure correct execution in parallel programs.
C++ Memory Order makes “source code compatible” across different platforms as shown below.
volatile bool ready(false);
void producer() {
// Populate data
for (int i = 0; i < 10; ++i) {
data.push_back(i * 10);
}
asm("__sync__"); // rely on sync or barrier in CPU instruction.
// Release store: Ensures all writes to 'data' are visible before 'ready' is set.
ready = true; // Release signal
}
void consumer() {
// Acquire load: Ensures all writes that happened before the release store are visible.
while (!ready); // Wait for ready signal
// Ensure that this print sees the correct value of `data`
for (int i = 0; i < 10; ++i) {
std::cout << data[i];
}
}
![digraph MemoryOrderAcquireCache {
rankdir=TB;
node [shape=box, fontname="Helvetica"];
// Main memory
MainMemory [label="Main Memory", shape=cylinder, style=filled, fillcolor=lightgray];
// CPU caches
subgraph cluster_cache1 {
label="CPU Core 1 Cache (Thread 1 - Producer)";
style=dashed;
Cache1_Data [label="data.push_back(i * 10);"];
Cache1_Ready [label="ready=true"];
}
subgraph cluster_cache2 {
label="CPU Core 2 Cache (Thread 2 - Consumer)";
style=dashed;
Cache2_Data [label="std::cout << data[i];"];
Cache2_Ready [label="ready=false"];
}
// Threads
Thread1 [label="Thread 1 (Producer)"];
Thread2 [label="Thread 2 (Consumer)"];
// Memory operations in Thread 1 (Producer)
Thread1 -> Cache1_Data;
Thread1 -> Cache1_Ready [label="ready.store(true, release)"];
// Memory propagation
Cache1_Ready -> MainMemory [label="ready=true propagated", color=red];
MainMemory -> Cache2_Ready [label="Consumer sees ready=true (Acquire)", color=red];
// Memory operations in Thread 2 (Consumer)
Thread2 -> Cache2_Ready [label="while (!ready.load(acquire));"];
Cache2_Ready -> Cache2_Data [label="data.load(relaxed)", color=blue];
// Synchronization path
Cache1_Ready -> Cache2_Ready [label="Acquire-Release Sync", style=dashed, color=purple];
}](_images/graphviz-d1a47bb72182b805f8b7fe7f5f431c71ef946f76.png)
Fig. 56 Diagram for mem-order-ex1.cpp¶
Diagram Explanation:
CPU Core 1 (Thread 1 - Producer)
Writes all elements to ‘data’ (not immediately visible).
asm(“__sync__”) ensuring prior stores are visible before writing true to ready, “ready = true”.
All memory access instructions (load/store) must be completed after asm(“__sync__”).
Main Memory
‘ready=true’ propagates to main memory, making it visible to all cores.
CPU Core 2 (Thread 2 - Consumer)
Waits until ‘ready=true’, ensuring visibility of all previous writes.
After acquiring ready, output all elements from ‘data’, which are now reliably published by the producer thread..
Above inline assembly asm(“__sync__”) has the following problem:
No standard atomic operations → source code imcompatible.
Developers had to use compiler-specific intrinsics (like GCC’s __sync_*, MSVC’s Interlocked*) or inline assembly, making source code imcompatible.
The following C++11 example solve the problem of source code imcompatible.
References/c++/mem-order-ex1.cpp (C++ code of memory order for producer-consumer)
#include <iostream>
#include <thread>
#include <vector>
#include <atomic>
std::atomic<int> data(0);
std::atomic<bool> ready(false);
void producer() {
// Populate data
for (int i = 0; i < 10; ++i) {
data.push_back(i * 10);
}
// Release store: Ensures all writes to 'data' are visible before 'ready' is set.
ready.store(true, std::memory_order_release); // Release signal
}
void consumer() {
// Acquire load: Ensures all writes that happened before the release store are visible.
while (!ready.load(std::memory_order_acquire)); // Wait for ready signal
// Ensure that this print sees the correct value of `data`
for (int i = 0; i < 10; ++i) {
std::cout << data[i];
}
}
int main() {
std::thread t1(producer);
std::thread t2(consumer);
t1.join();
t2.join();
return 0;
}
memory_order::release
Same as asm(“__sync__”), read and write operations appearing before the operation in the program must occur before it and are completed after “ready.store(true, std::memory_order_release)”.
memory_order::acquire
Same as load volatile varaible “ready”, read and write operations appearing after the operation in the program must occur after it (i.e., they cannot be re-ordered before the operation, “while (!ready.load(std::memory_order_acquire))”).
Summary:
C++ Memory Order makes “source code compatible” across different platforms.
The Problem Before C++11¶
Before C++11, multi-threaded programming relied on mutexes, volatile variables, and platform-specific atomic operations (such as atomic_load(&a) and atomic_store(&a, 42), which often led to inefficiencies and undefined behavior.
For RISC CPUs, only load/store instructions access memory. Atomic instructions ensure memory consistency across multiple cores.
CPUs provide atomic operations such as compare-and-swap [7] or ll/sc (load-linked/store-conditional), along with BARRIER or SYNC instructions to enforce memory ordering. However, C++03 did not have a language feature to tell the compiler how to control memory order for load/store instructions.
To address this, C++11 introduced memory orderings via `std::atomic`, giving programmers fine-grained control over synchronization and memory consistency.
No standard atomic operations → source code imcompatible.
Developers had to use compiler-specific intrinsics (like GCC’s __sync_*, MSVC’s Interlocked*) or inline assembly, making source code imcompatible.
Unspecified Behavior in Multi-threading
The C++98/03 standard had no formal memory model.
Compilers optimized code aggressively, leading to race conditions.
Reliance on Volatile and Platform-specific Primitives
volatile did not prevent reordering by the compiler.
Though some compilers may choose to avoid reordering around volatile accesses.
Programmers had to use OS-specific APIs (e.g., `pthread_mutex`).
Inefficient Synchronization Mechanisms
Mutexes ensured correctness but caused performance overhead.
Spin-locks wasted CPU cycles due to busy-waiting.
C++11 Memory Model Solution¶
Note
Non-blocking algorithm: In computer science, an algorithm is called non-blocking if failure or suspension of any thread cannot cause failure or suspension of another thread.
If a suspended thread can temporarily release its mutex and reacquire it upon resuming, while always producing correct results, then the algorithm is non-blocking.
Wait-free: no starvation.
An algorithm is wait-free if every operation has a bound on the number of steps the algorithm will take before the operation completes. In other words, wait-free algorithm has no starvation.
Lock-free: progressive, allow starvation.
Lock-freedom allows individual threads to starve but guarantees system-wide throughput. An algorithm is lock-free if, when the program threads are run for a sufficiently long time, at least one of the threads makes progress (for some sensible definition of progress).
All wait-free algorithms are lock-free. In particular, if one thread is suspended, then a lock-free algorithm guarantees that the remaining threads can still make progress. Hence, if two threads can contend for the same mutex lock or spinlock, then the algorithm is not lock-free. (If we suspend one thread that holds the lock, then the second thread will block.) [8].
Based on this definition, any algorithm that retains a mutex without allowing temporary release does not qualify as lock-free.
C++11 introduced a well-defined memory model and atomic operations with memory orderings, allowing programmers to control hardware-level optimizations.
Feature |
Description |
Benefit |
|---|---|---|
std::atomic |
Provides lock-free atomic variables |
Faster than mutexes |
Memory Orderings (std::memory_order) |
Controls instruction reordering |
Fine-grained optimization |
Sequential Consistency (memory_order_seq_cst) |
Strongest ordering, default behavior |
Prevents race conditions |
Acquire-Release (memory_order_acquire/release) |
Synchronization without mutexes |
Efficient producer-consumer |
Relaxed Ordering (memory_order_relaxed) |
Allows reordering for performance |
Best for atomic counters |
Memory Order |
Description |
Use Cases |
|---|---|---|
memory_order_relaxed |
No ordering guarantees; only atomicity. |
Non-dependent atomic counters, statistics. |
memory_order_consume |
Data-dependent ordering (deprecated in practice). |
Rarely used; intended for pointer chains. |
memory_order_acquire |
Ensures preceding reads/writes are visible. |
Locks, consumer threads. |
memory_order_release |
Ensures following reads/writes are visible. |
Locks, producer threads. |
memory_order_acq_rel |
Combines acquire + release. |
Read-modify-write operations, synchronization. |
memory_order_seq_cst |
Strongest ordering; global sequential consistency. |
Default behavior, safest but can be slow. |
Explanation:
Sequential Consistency (`memory_order_seq_cst`)
Prevents reordering globally.
Ensures all threads observe operations in the same order.
Default behavior of std::atomic.
Provides global order of operations, preventing out-of-order execution.
The safest but can cause performance overhead.
Acquire-Release (`memory_order_acquire/release`)
Efficient alternative to mutexes.
acquire: Ensures earlier loads are visible.
release: Ensures later stores are visible.
Relaxed Ordering (`memory_order_relaxed`)
Allows maximum performance without ordering constraints.
Best for counters and statistics that don’t need synchronization.
Example: Atomic counters that don’t require ordering.
`memory_order_acq_rel`
Used in atomic read-modify-write operations like fetch_add.
Ensures proper ordering in concurrent updates.
Summary:
Use `memory_order_relaxed` for performance when ordering is unnecessary.
Use `memory_order_acquire/release` for synchronization between threads.
Use `memory_order_seq_cst` when you need global ordering but at a performance cost.
Cpu0 implementation for memory-order¶
In order to support atomic in C++ and java, llvm provides the atomic IRs and memory ordering here [9] [10].
The chapter 19 of book DPC++ [11] explains the memory ordering better and I add the related code fragment of lbdex/input/atomics.ll to it for explanation as follows,
memory_order::relaxed
Read and write operations can be re-ordered before or after the operation with no restrictions. There are no ordering guarantees.
define i8 @load_i8_unordered(i8* %mem) {
; CHECK-LABEL: load_i8_unordered
; CHECK: ll
; CHECK: sc
; CHECK-NOT: sync
%val = load atomic i8, i8* %mem unordered, align 1
ret i8 %val
}
No sync from CodeGen instructions above.
memory_order::acquire
Read and write operations appearing after the operation in the program must occur after it (i.e., they cannot be re-ordered before the operation).
define i32 @load_i32_acquire(i32* %mem) {
; CHECK-LABEL: load_i32_acquire
; CHECK: ll
; CHECK: sc
%val = load atomic i32, i32* %mem acquire, align 4
; CHECK: sync
ret i32 %val
}
Sync guarantees “load atomic” complete before the next R/W (Read/Write). All writes in other threads that release the same atomic variable are visible in the current thread.
memory_order::release
Read and write operations appearing before the operation in the program must occur before it (i.e., they cannot be re-ordered after the operation), and preceding write operations are guaranteed to be visible to other program instances which have been synchronized by a corresponding acquire operation (i.e., an atomic operation using the same variable and memory_order::acquire or a barrier function).
define void @store_i32_release(i32* %mem) {
; CHECK-LABEL: store_i32_release
; CHECK: sync
; CHECK: ll
; CHECK: sc
store atomic i32 42, i32* %mem release, align 4
ret void
}
Sync guarantees preceding R/W complete before “store atomic”. Mips’ ll and sc guarantee that “store atomic release” is visible to other processors.
memory_order::acq_rel
The operation acts as both an acquire and a release. Read and write operations cannot be re-ordered around the operation, and preceding writes must be made visible as previously described for memory_order::release.
define i32 @cas_strong_i32_acqrel_acquire(i32* %mem) {
; CHECK-LABEL: cas_strong_i32_acqrel_acquire
; CHECK: ll
; CHECK: sc
%val = cmpxchg i32* %mem, i32 0, i32 1 acq_rel acquire
; CHECK: sync
%loaded = extractvalue { i32, i1} %val, 0
ret i32 %loaded
}
Sync guarantees preceding R/W complete before “cmpxchg”. Other processors’ preceding write operations are guaranteed to be visible to this “cmpxchg acquire” (Mips’s ll and sc quarantee it).
memory_order::seq_cst
The operation acts as an acquire, release, or both depending on whether it is a read, write, or read-modify-write operation, respectively. All operations with this memory order are observed in a sequentially consistent order.
define i8 @cas_strong_i8_sc_sc(i8* %mem) {
; CHECK-LABEL: cas_strong_i8_sc_sc
; CHECK: sync
; CHECK: ll
; CHECK: sc
%val = cmpxchg i8* %mem, i8 0, i8 1 seq_cst seq_cst
; CHECK: sync
%loaded = extractvalue { i8, i1} %val, 0
ret i8 %loaded
}
First sync guarantees preceding R/W complete before “cmpxchg seq_cst” and visible to “cmpxchg seq_cst”. For seq_cst, a store performs a release operation. Which means “cmpxchg seq_cst” are visible to other threads/processors that acquire the same atomic variable as the memory_order_release definition. Mips’ ll and sc quarantees this feature of “cmpxchg seq_cst”. Second Sync guarantees “cmpxchg seq_cst” complete before the next R/W.
There are several restrictions on which memory orders are supported by each operation. Fig. 57 (from book Figure 19-10) summarizes which combinations are valid.
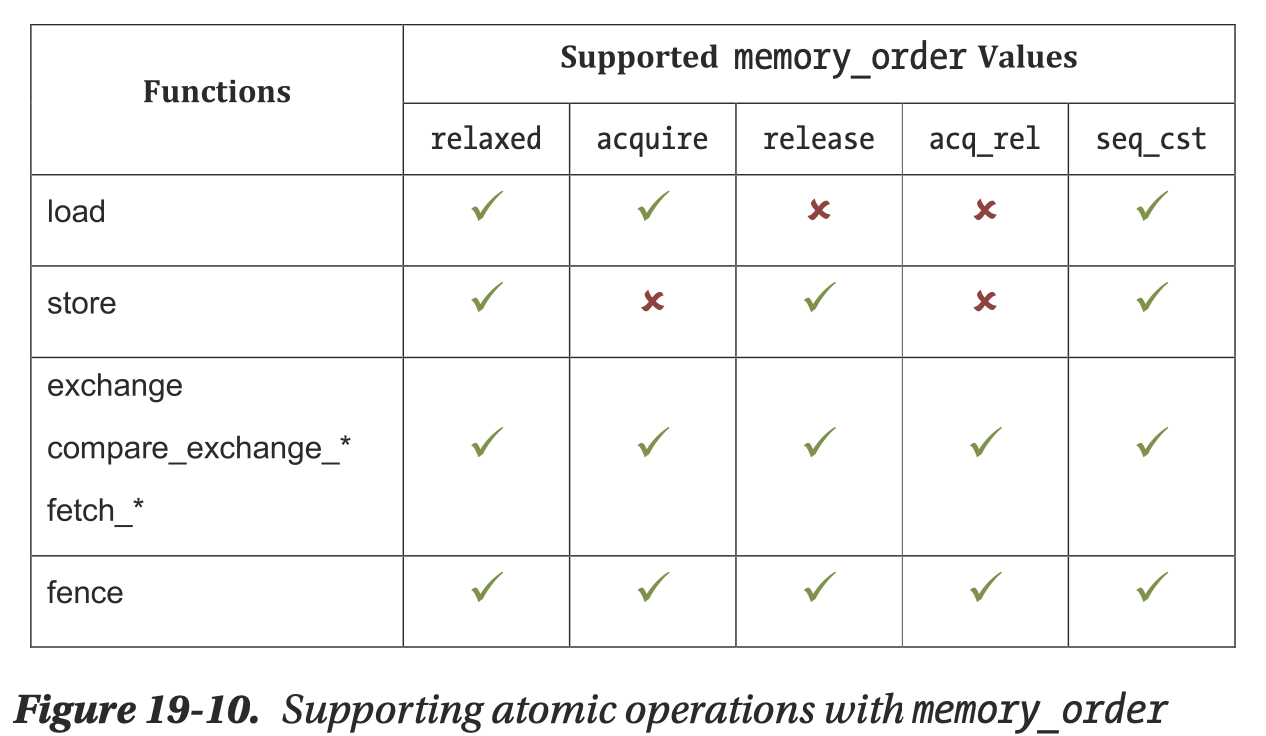
Fig. 57 Supporting atomic operations with memory_order¶
Load operations do not write values to memory and are therefore incompatible with release semantics. Similarly, store operations do not read values from memory and are therefore incompatible with acquire semantics. The remaining read-modify-write atomic operations and fences are compatible with all memory orderings [11].
Note
C++ memory_order_consume
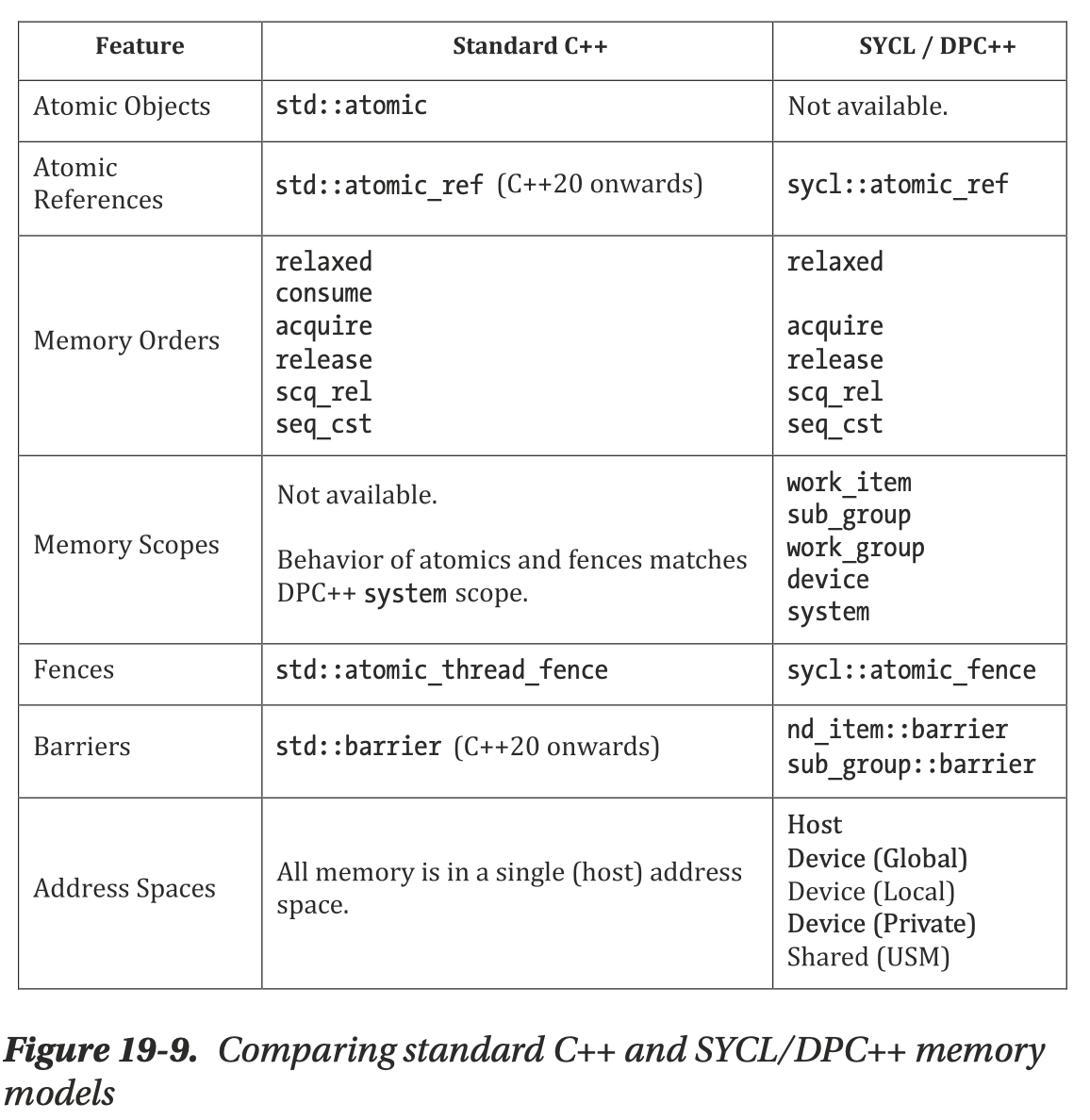
Fig. 58 Comparing standard C++ and SYCL/DPC++ memory models¶
The C++ memory model additionally includes memory_order::consume, with similar behavior to memory_order::acquire. however, the C++17 standard discourages its use, noting that its definition is being revised. its inclusion in dpC++ has therefore been postponed to a future version.
For a few years now, compilers have treated consume as a synonym for acquire [12].
The current expectation is that the replacement facility will rely on core memory model and atomics definitions very similar to what’s currently there. Since memory_order_consume does have a profound impact on the memory model, removing this text would allow drastic simplification, but conversely would make it very difficult to add anything along the lines of memory_order_consume back in later, especially if the standard evolves in the meantime, as expected. Thus we are not proposing to remove the current wording [13].
The following test files are extracted from memory_checks() in clang/test/Sema/atomic-ops.c. The __c11_atomic_xxx built-in functions used by Clang are defined in clang/include/clang/Basic/Builtins.def. Compiling these files with Clang produces the same results as shown in Fig. 57.
Note: Clang compiles memory_order_consume to the same result as memory_order_acquire.
lbdex/input/ch12_sema_atomic-ops.c
// clang -S ch12_sema_atomic-ops.c -emit-llvm -o -
// Uses /opt/homebrew/opt/llvm/bin/clang in macOS.
#include <stdatomic.h>
// From memory_checks() of Sema/atomic-ops.c
void memory_checks(_Atomic(int) *Ap, int *p, int val) {
(void)__c11_atomic_load(Ap, memory_order_relaxed);
(void)__c11_atomic_load(Ap, memory_order_acquire);
(void)__c11_atomic_load(Ap, memory_order_consume);
(void)__c11_atomic_load(Ap, memory_order_release); // expected-warning {{memory order argument to atomic operation is invalid}}
(void)__c11_atomic_load(Ap, memory_order_acq_rel); // expected-warning {{memory order argument to atomic operation is invalid}}
(void)__c11_atomic_load(Ap, memory_order_seq_cst);
(void)__c11_atomic_load(Ap, val);
(void)__c11_atomic_load(Ap, -1); // expected-warning {{memory order argument to atomic operation is invalid}}
(void)__c11_atomic_load(Ap, 42); // expected-warning {{memory order argument to atomic operation is invalid}}
(void)__c11_atomic_store(Ap, val, memory_order_relaxed);
(void)__c11_atomic_store(Ap, val, memory_order_acquire); // expected-warning {{memory order argument to atomic operation is invalid}}
(void)__c11_atomic_store(Ap, val, memory_order_consume); // expected-warning {{memory order argument to atomic operation is invalid}}
(void)__c11_atomic_store(Ap, val, memory_order_release);
(void)__c11_atomic_store(Ap, val, memory_order_acq_rel); // expected-warning {{memory order argument to atomic operation is invalid}}
(void)__c11_atomic_store(Ap, val, memory_order_seq_cst);
(void)__c11_atomic_exchange(Ap, val, memory_order_relaxed);
(void)__c11_atomic_exchange(Ap, val, memory_order_acquire);
(void)__c11_atomic_exchange(Ap, val, memory_order_consume);
(void)__c11_atomic_exchange(Ap, val, memory_order_release);
(void)__c11_atomic_exchange(Ap, val, memory_order_acq_rel);
(void)__c11_atomic_exchange(Ap, val, memory_order_seq_cst);
(void)__c11_atomic_compare_exchange_strong(Ap, p, val, memory_order_relaxed, memory_order_relaxed);
(void)__c11_atomic_compare_exchange_strong(Ap, p, val, memory_order_acquire, memory_order_relaxed);
(void)__c11_atomic_compare_exchange_strong(Ap, p, val, memory_order_consume, memory_order_relaxed);
(void)__c11_atomic_compare_exchange_strong(Ap, p, val, memory_order_release, memory_order_relaxed);
(void)__c11_atomic_compare_exchange_strong(Ap, p, val, memory_order_acq_rel, memory_order_relaxed);
(void)__c11_atomic_compare_exchange_strong(Ap, p, val, memory_order_seq_cst, memory_order_relaxed);
(void)__c11_atomic_compare_exchange_weak(Ap, p, val, memory_order_relaxed, memory_order_relaxed);
(void)__c11_atomic_compare_exchange_weak(Ap, p, val, memory_order_acquire, memory_order_relaxed);
(void)__c11_atomic_compare_exchange_weak(Ap, p, val, memory_order_consume, memory_order_relaxed);
(void)__c11_atomic_compare_exchange_weak(Ap, p, val, memory_order_release, memory_order_relaxed);
(void)__c11_atomic_compare_exchange_weak(Ap, p, val, memory_order_acq_rel, memory_order_relaxed);
(void)__c11_atomic_compare_exchange_weak(Ap, p, val, memory_order_seq_cst, memory_order_relaxed);
atomic_thread_fence(memory_order_relaxed);
atomic_thread_fence(memory_order_acquire);
atomic_thread_fence(memory_order_consume); // For a few years now, compilers have treated consume as a synonym for acquire.
atomic_thread_fence(memory_order_release);
atomic_thread_fence(memory_order_acq_rel);
atomic_thread_fence(memory_order_seq_cst);
atomic_signal_fence(memory_order_seq_cst);
}
lbdex/input/ch12_sema_atomic-fetch.c
// clang -S ch12_sema_atomic-fetch.c -emit-llvm -o -
// Uses /opt/homebrew/opt/llvm/bin/clang in macOS.
#include <stdatomic.h>
//#define WANT_COMPILE_FAIL
// From __c11_atomic_fetch_xxx of memory_checks() of Sema/atomic-ops.c
void memory_checks(_Atomic(int) *Ap, int *p, int val) {
(void)__c11_atomic_fetch_add(Ap, 1, memory_order_relaxed);
(void)__c11_atomic_fetch_add(Ap, 1, memory_order_acquire);
(void)__c11_atomic_fetch_add(Ap, 1, memory_order_consume);
(void)__c11_atomic_fetch_add(Ap, 1, memory_order_release);
(void)__c11_atomic_fetch_add(Ap, 1, memory_order_acq_rel);
(void)__c11_atomic_fetch_add(Ap, 1, memory_order_seq_cst);
#ifdef WANT_COMPILE_FAIL // fail to compile:
(void)__c11_atomic_fetch_add(
(struct Incomplete * _Atomic *)0, // expected-error {{incomplete type 'struct Incomplete'}}
1, memory_order_seq_cst);
#endif
(void)__c11_atomic_init(Ap, val);
(void)__c11_atomic_init(Ap, val);
(void)__c11_atomic_init(Ap, val);
(void)__c11_atomic_init(Ap, val);
(void)__c11_atomic_init(Ap, val);
(void)__c11_atomic_init(Ap, val);
(void)__c11_atomic_fetch_sub(Ap, val, memory_order_relaxed);
(void)__c11_atomic_fetch_sub(Ap, val, memory_order_acquire);
(void)__c11_atomic_fetch_sub(Ap, val, memory_order_consume);
(void)__c11_atomic_fetch_sub(Ap, val, memory_order_release);
(void)__c11_atomic_fetch_sub(Ap, val, memory_order_acq_rel);
(void)__c11_atomic_fetch_sub(Ap, val, memory_order_seq_cst);
(void)__c11_atomic_fetch_and(Ap, val, memory_order_relaxed);
(void)__c11_atomic_fetch_and(Ap, val, memory_order_acquire);
(void)__c11_atomic_fetch_and(Ap, val, memory_order_consume);
(void)__c11_atomic_fetch_and(Ap, val, memory_order_release);
(void)__c11_atomic_fetch_and(Ap, val, memory_order_acq_rel);
(void)__c11_atomic_fetch_and(Ap, val, memory_order_seq_cst);
(void)__c11_atomic_fetch_or(Ap, val, memory_order_relaxed);
(void)__c11_atomic_fetch_or(Ap, val, memory_order_acquire);
(void)__c11_atomic_fetch_or(Ap, val, memory_order_consume);
(void)__c11_atomic_fetch_or(Ap, val, memory_order_release);
(void)__c11_atomic_fetch_or(Ap, val, memory_order_acq_rel);
(void)__c11_atomic_fetch_or(Ap, val, memory_order_seq_cst);
(void)__c11_atomic_fetch_xor(Ap, val, memory_order_relaxed);
(void)__c11_atomic_fetch_xor(Ap, val, memory_order_acquire);
(void)__c11_atomic_fetch_xor(Ap, val, memory_order_consume);
(void)__c11_atomic_fetch_xor(Ap, val, memory_order_release);
(void)__c11_atomic_fetch_xor(Ap, val, memory_order_acq_rel);
(void)__c11_atomic_fetch_xor(Ap, val, memory_order_seq_cst);
(void)__c11_atomic_fetch_nand(Ap, val, memory_order_relaxed);
(void)__c11_atomic_fetch_nand(Ap, val, memory_order_acquire);
(void)__c11_atomic_fetch_nand(Ap, val, memory_order_consume);
(void)__c11_atomic_fetch_nand(Ap, val, memory_order_release);
(void)__c11_atomic_fetch_nand(Ap, val, memory_order_acq_rel);
(void)__c11_atomic_fetch_nand(Ap, val, memory_order_seq_cst);
(void)__c11_atomic_fetch_min(Ap, val, memory_order_relaxed);
(void)__c11_atomic_fetch_min(Ap, val, memory_order_acquire);
(void)__c11_atomic_fetch_min(Ap, val, memory_order_consume);
(void)__c11_atomic_fetch_min(Ap, val, memory_order_release);
(void)__c11_atomic_fetch_min(Ap, val, memory_order_acq_rel);
(void)__c11_atomic_fetch_min(Ap, val, memory_order_seq_cst);
(void)__c11_atomic_fetch_max(Ap, val, memory_order_relaxed);
(void)__c11_atomic_fetch_max(Ap, val, memory_order_acquire);
(void)__c11_atomic_fetch_max(Ap, val, memory_order_consume);
(void)__c11_atomic_fetch_max(Ap, val, memory_order_release);
(void)__c11_atomic_fetch_max(Ap, val, memory_order_acq_rel);
(void)__c11_atomic_fetch_max(Ap, val, memory_order_seq_cst);
}
clang’s builtin |
llvm ir |
|---|---|
__c11_atomic_load |
load atomic |
__c11_atomic_store |
store atomic |
__c11_atomic_exchange_xxx |
cmpxchg |
atomic_thread_fence |
fence |
__c11_atomic_fetch_xxx |
atomicrmw xxx |
C++ atomic functions are supported by calling implementation functions from the C++ standard library. These functions eventually call the __c11_atomic_xxx built-in functions for actual implementation.
Therefore, __c11_atomic_xxx functions, listed above, provide a lower-level and higher-performance interface for C++ programmers. An example is shown below:
lbdex/input/ch12_c++_atomics.cpp
// ~/llvm/debug/build/bin/clang -S ch12_c++_atomics.cpp -emit-llvm -o -
// Uses /opt/homebrew/opt/llvm/bin/clang in macOS.
#include <atomic>
std::atomic<bool> winner (false);
int test_atomics() {
int count = 0;
bool res = winner.exchange(true);
if (res) count++;
return count;
}
To support LLVM atomic IR instructions, the following code is added to Chapter12_1.
lbdex/chapters/Chapter12_1/Disassembler/Cpu0Disassembler.cpp
static DecodeStatus DecodeMem(MCInst &Inst,
unsigned Insn,
uint64_t Address,
const void *Decoder) {
if(Inst.getOpcode() == Cpu0::SC){
Inst.addOperand(MCOperand::createReg(Reg));
}
...
}
lbdex/chapters/Chapter12_1/Cpu0InstrInfo.td
def SDT_Sync : SDTypeProfile<0, 1, [SDTCisVT<0, i32>]>;
def Cpu0Sync : SDNode<"Cpu0ISD::Sync", SDT_Sync, [SDNPHasChain]>;
def PtrRC : Operand<iPTR> {
let MIOperandInfo = (ops ptr_rc);
let DecoderMethod = "DecodeCPURegsRegisterClass";
}
// Atomic instructions with 2 source operands (ATOMIC_SWAP & ATOMIC_LOAD_*).
class Atomic2Ops<PatFrag Op, RegisterClass DRC> :
PseudoSE<(outs DRC:$dst), (ins PtrRC:$ptr, DRC:$incr),
[(set DRC:$dst, (Op iPTR:$ptr, DRC:$incr))]>;
// Atomic Compare & Swap.
class AtomicCmpSwap<PatFrag Op, RegisterClass DRC> :
PseudoSE<(outs DRC:$dst), (ins PtrRC:$ptr, DRC:$cmp, DRC:$swap),
[(set DRC:$dst, (Op iPTR:$ptr, DRC:$cmp, DRC:$swap))]>;
class LLBase<bits<8> Opc, string opstring, RegisterClass RC, Operand Mem> :
FMem<Opc, (outs RC:$ra), (ins Mem:$addr),
!strconcat(opstring, "\t$ra, $addr"), [], IILoad> {
let mayLoad = 1;
}
class SCBase<bits<8> Opc, string opstring, RegisterOperand RO, Operand Mem> :
FMem<Opc, (outs RO:$dst), (ins RO:$ra, Mem:$addr),
!strconcat(opstring, "\t$ra, $addr"), [], IIStore> {
let mayStore = 1;
let Constraints = "$ra = $dst";
}
let Predicates = [Ch12_1] in {
let usesCustomInserter = 1 in {
def ATOMIC_LOAD_ADD_I8 : Atomic2Ops<atomic_load_add_8, CPURegs>;
def ATOMIC_LOAD_ADD_I16 : Atomic2Ops<atomic_load_add_16, CPURegs>;
def ATOMIC_LOAD_ADD_I32 : Atomic2Ops<atomic_load_add_32, CPURegs>;
def ATOMIC_LOAD_SUB_I8 : Atomic2Ops<atomic_load_sub_8, CPURegs>;
def ATOMIC_LOAD_SUB_I16 : Atomic2Ops<atomic_load_sub_16, CPURegs>;
def ATOMIC_LOAD_SUB_I32 : Atomic2Ops<atomic_load_sub_32, CPURegs>;
def ATOMIC_LOAD_AND_I8 : Atomic2Ops<atomic_load_and_8, CPURegs>;
def ATOMIC_LOAD_AND_I16 : Atomic2Ops<atomic_load_and_16, CPURegs>;
def ATOMIC_LOAD_AND_I32 : Atomic2Ops<atomic_load_and_32, CPURegs>;
def ATOMIC_LOAD_OR_I8 : Atomic2Ops<atomic_load_or_8, CPURegs>;
def ATOMIC_LOAD_OR_I16 : Atomic2Ops<atomic_load_or_16, CPURegs>;
def ATOMIC_LOAD_OR_I32 : Atomic2Ops<atomic_load_or_32, CPURegs>;
def ATOMIC_LOAD_XOR_I8 : Atomic2Ops<atomic_load_xor_8, CPURegs>;
def ATOMIC_LOAD_XOR_I16 : Atomic2Ops<atomic_load_xor_16, CPURegs>;
def ATOMIC_LOAD_XOR_I32 : Atomic2Ops<atomic_load_xor_32, CPURegs>;
def ATOMIC_LOAD_NAND_I8 : Atomic2Ops<atomic_load_nand_8, CPURegs>;
def ATOMIC_LOAD_NAND_I16 : Atomic2Ops<atomic_load_nand_16, CPURegs>;
def ATOMIC_LOAD_NAND_I32 : Atomic2Ops<atomic_load_nand_32, CPURegs>;
def ATOMIC_SWAP_I8 : Atomic2Ops<atomic_swap_8, CPURegs>;
def ATOMIC_SWAP_I16 : Atomic2Ops<atomic_swap_16, CPURegs>;
def ATOMIC_SWAP_I32 : Atomic2Ops<atomic_swap_32, CPURegs>;
def ATOMIC_CMP_SWAP_I8 : AtomicCmpSwap<atomic_cmp_swap_8, CPURegs>;
def ATOMIC_CMP_SWAP_I16 : AtomicCmpSwap<atomic_cmp_swap_16, CPURegs>;
def ATOMIC_CMP_SWAP_I32 : AtomicCmpSwap<atomic_cmp_swap_32, CPURegs>;
}
}
let Predicates = [Ch12_1] in {
let hasSideEffects = 1 in
def SYNC : Cpu0Inst<(outs), (ins i32imm:$stype), "sync $stype",
[(Cpu0Sync imm:$stype)], NoItinerary, FrmOther>
{
bits<5> stype;
let Opcode = 0x60;
let Inst{25-11} = 0;
let Inst{10-6} = stype;
let Inst{5-0} = 0;
}
}
/// Load-linked, Store-conditional
def LL : LLBase<0x61, "ll", CPURegs, mem>;
def SC : SCBase<0x62, "sc", RegisterOperand<CPURegs>, mem>;
def : Cpu0InstAlias<"sync",
(SYNC 0), 1>;
lbdex/chapters/Chapter12_1/Cpu0ISelLowering.h
MachineBasicBlock *
EmitInstrWithCustomInserter(MachineInstr &MI,
MachineBasicBlock *MBB) const override;
SDValue lowerATOMIC_FENCE(SDValue Op, SelectionDAG& DAG) const;
bool shouldInsertFencesForAtomic(const Instruction *I) const override {
return true;
}
/// Emit a sign-extension using shl/sra appropriately.
MachineBasicBlock *emitSignExtendToI32InReg(MachineInstr &MI,
MachineBasicBlock *BB,
unsigned Size, unsigned DstReg,
unsigned SrcRec) const;
MachineBasicBlock *emitAtomicBinary(MachineInstr &MI, MachineBasicBlock *BB,
unsigned Size, unsigned BinOpcode, bool Nand = false) const;
MachineBasicBlock *emitAtomicBinaryPartword(MachineInstr &MI,
MachineBasicBlock *BB, unsigned Size, unsigned BinOpcode,
bool Nand = false) const;
MachineBasicBlock *emitAtomicCmpSwap(MachineInstr &MI,
MachineBasicBlock *BB, unsigned Size) const;
MachineBasicBlock *emitAtomicCmpSwapPartword(MachineInstr &MI,
MachineBasicBlock *BB, unsigned Size) const;
lbdex/chapters/Chapter12_1/Cpu0SelLowering.cpp
const char *Cpu0TargetLowering::getTargetNodeName(unsigned Opcode) const {
case Cpu0ISD::Sync: return "Cpu0ISD::Sync";
...
}
Cpu0TargetLowering::Cpu0TargetLowering(const Cpu0TargetMachine &TM,
const Cpu0Subtarget &STI)
: TargetLowering(TM), Subtarget(STI), ABI(TM.getABI()) {
setOperationAction(ISD::ATOMIC_LOAD, MVT::i32, Expand);
setOperationAction(ISD::ATOMIC_LOAD, MVT::i64, Expand);
setOperationAction(ISD::ATOMIC_STORE, MVT::i32, Expand);
setOperationAction(ISD::ATOMIC_STORE, MVT::i64, Expand);
SDValue Cpu0TargetLowering::
LowerOperation(SDValue Op, SelectionDAG &DAG) const
{
switch (Op.getOpcode())
{
case ISD::ATOMIC_FENCE: return lowerATOMIC_FENCE(Op, DAG);
...
}
MachineBasicBlock *
Cpu0TargetLowering::EmitInstrWithCustomInserter(MachineInstr &MI,
MachineBasicBlock *BB) const {
switch (MI.getOpcode()) {
default:
llvm_unreachable("Unexpected instr type to insert");
case Cpu0::ATOMIC_LOAD_ADD_I8:
return emitAtomicBinaryPartword(MI, BB, 1, Cpu0::ADDu);
case Cpu0::ATOMIC_LOAD_ADD_I16:
return emitAtomicBinaryPartword(MI, BB, 2, Cpu0::ADDu);
case Cpu0::ATOMIC_LOAD_ADD_I32:
return emitAtomicBinary(MI, BB, 4, Cpu0::ADDu);
case Cpu0::ATOMIC_LOAD_AND_I8:
return emitAtomicBinaryPartword(MI, BB, 1, Cpu0::AND);
case Cpu0::ATOMIC_LOAD_AND_I16:
return emitAtomicBinaryPartword(MI, BB, 2, Cpu0::AND);
case Cpu0::ATOMIC_LOAD_AND_I32:
return emitAtomicBinary(MI, BB, 4, Cpu0::AND);
case Cpu0::ATOMIC_LOAD_OR_I8:
return emitAtomicBinaryPartword(MI, BB, 1, Cpu0::OR);
case Cpu0::ATOMIC_LOAD_OR_I16:
return emitAtomicBinaryPartword(MI, BB, 2, Cpu0::OR);
case Cpu0::ATOMIC_LOAD_OR_I32:
return emitAtomicBinary(MI, BB, 4, Cpu0::OR);
case Cpu0::ATOMIC_LOAD_XOR_I8:
return emitAtomicBinaryPartword(MI, BB, 1, Cpu0::XOR);
case Cpu0::ATOMIC_LOAD_XOR_I16:
return emitAtomicBinaryPartword(MI, BB, 2, Cpu0::XOR);
case Cpu0::ATOMIC_LOAD_XOR_I32:
return emitAtomicBinary(MI, BB, 4, Cpu0::XOR);
case Cpu0::ATOMIC_LOAD_NAND_I8:
return emitAtomicBinaryPartword(MI, BB, 1, 0, true);
case Cpu0::ATOMIC_LOAD_NAND_I16:
return emitAtomicBinaryPartword(MI, BB, 2, 0, true);
case Cpu0::ATOMIC_LOAD_NAND_I32:
return emitAtomicBinary(MI, BB, 4, 0, true);
case Cpu0::ATOMIC_LOAD_SUB_I8:
return emitAtomicBinaryPartword(MI, BB, 1, Cpu0::SUBu);
case Cpu0::ATOMIC_LOAD_SUB_I16:
return emitAtomicBinaryPartword(MI, BB, 2, Cpu0::SUBu);
case Cpu0::ATOMIC_LOAD_SUB_I32:
return emitAtomicBinary(MI, BB, 4, Cpu0::SUBu);
case Cpu0::ATOMIC_SWAP_I8:
return emitAtomicBinaryPartword(MI, BB, 1, 0);
case Cpu0::ATOMIC_SWAP_I16:
return emitAtomicBinaryPartword(MI, BB, 2, 0);
case Cpu0::ATOMIC_SWAP_I32:
return emitAtomicBinary(MI, BB, 4, 0);
case Cpu0::ATOMIC_CMP_SWAP_I8:
return emitAtomicCmpSwapPartword(MI, BB, 1);
case Cpu0::ATOMIC_CMP_SWAP_I16:
return emitAtomicCmpSwapPartword(MI, BB, 2);
case Cpu0::ATOMIC_CMP_SWAP_I32:
return emitAtomicCmpSwap(MI, BB, 4);
}
}
// This function also handles Cpu0::ATOMIC_SWAP_I32 (when BinOpcode == 0), and
// Cpu0::ATOMIC_LOAD_NAND_I32 (when Nand == true)
MachineBasicBlock *Cpu0TargetLowering::emitAtomicBinary(
MachineInstr &MI, MachineBasicBlock *BB, unsigned Size, unsigned BinOpcode,
bool Nand) const {
assert((Size == 4) && "Unsupported size for EmitAtomicBinary.");
MachineFunction *MF = BB->getParent();
MachineRegisterInfo &RegInfo = MF->getRegInfo();
const TargetRegisterClass *RC = getRegClassFor(MVT::getIntegerVT(Size * 8));
const TargetInstrInfo *TII = Subtarget.getInstrInfo();
DebugLoc DL = MI.getDebugLoc();
unsigned LL, SC, AND, XOR, ZERO, BEQ;
LL = Cpu0::LL;
SC = Cpu0::SC;
AND = Cpu0::AND;
XOR = Cpu0::XOR;
ZERO = Cpu0::ZERO;
BEQ = Cpu0::BEQ;
unsigned OldVal = MI.getOperand(0).getReg();
unsigned Ptr = MI.getOperand(1).getReg();
unsigned Incr = MI.getOperand(2).getReg();
unsigned StoreVal = RegInfo.createVirtualRegister(RC);
unsigned AndRes = RegInfo.createVirtualRegister(RC);
unsigned AndRes2 = RegInfo.createVirtualRegister(RC);
unsigned Success = RegInfo.createVirtualRegister(RC);
// insert new blocks after the current block
const BasicBlock *LLVM_BB = BB->getBasicBlock();
MachineBasicBlock *loopMBB = MF->CreateMachineBasicBlock(LLVM_BB);
MachineBasicBlock *exitMBB = MF->CreateMachineBasicBlock(LLVM_BB);
MachineFunction::iterator It = ++BB->getIterator();
MF->insert(It, loopMBB);
MF->insert(It, exitMBB);
// Transfer the remainder of BB and its successor edges to exitMBB.
exitMBB->splice(exitMBB->begin(), BB,
std::next(MachineBasicBlock::iterator(MI)), BB->end());
exitMBB->transferSuccessorsAndUpdatePHIs(BB);
// thisMBB:
// ...
// fallthrough --> loopMBB
BB->addSuccessor(loopMBB);
loopMBB->addSuccessor(loopMBB);
loopMBB->addSuccessor(exitMBB);
// loopMBB:
// ll oldval, 0(ptr)
// <binop> storeval, oldval, incr
// sc success, storeval, 0(ptr)
// beq success, $0, loopMBB
BB = loopMBB;
BuildMI(BB, DL, TII->get(LL), OldVal).addReg(Ptr).addImm(0);
if (Nand) {
// and andres, oldval, incr
// xor storeval, $0, andres
// xor storeval2, $0, storeval
BuildMI(BB, DL, TII->get(AND), AndRes).addReg(OldVal).addReg(Incr);
BuildMI(BB, DL, TII->get(XOR), StoreVal).addReg(ZERO).addReg(AndRes);
BuildMI(BB, DL, TII->get(XOR), AndRes2).addReg(ZERO).addReg(AndRes);
} else if (BinOpcode) {
// <binop> storeval, oldval, incr
BuildMI(BB, DL, TII->get(BinOpcode), StoreVal).addReg(OldVal).addReg(Incr);
} else {
StoreVal = Incr;
}
BuildMI(BB, DL, TII->get(SC), Success).addReg(StoreVal).addReg(Ptr).addImm(0);
BuildMI(BB, DL, TII->get(BEQ)).addReg(Success).addReg(ZERO).addMBB(loopMBB);
MI.eraseFromParent(); // The instruction is gone now.
return exitMBB;
}
MachineBasicBlock *Cpu0TargetLowering::emitSignExtendToI32InReg(
MachineInstr &MI, MachineBasicBlock *BB, unsigned Size, unsigned DstReg,
unsigned SrcReg) const {
const TargetInstrInfo *TII = Subtarget.getInstrInfo();
DebugLoc DL = MI.getDebugLoc();
MachineFunction *MF = BB->getParent();
MachineRegisterInfo &RegInfo = MF->getRegInfo();
const TargetRegisterClass *RC = getRegClassFor(MVT::i32);
unsigned ScrReg = RegInfo.createVirtualRegister(RC);
assert(Size < 32);
int64_t ShiftImm = 32 - (Size * 8);
BuildMI(BB, DL, TII->get(Cpu0::SHL), ScrReg).addReg(SrcReg).addImm(ShiftImm);
BuildMI(BB, DL, TII->get(Cpu0::SRA), DstReg).addReg(ScrReg).addImm(ShiftImm);
return BB;
}
MachineBasicBlock *Cpu0TargetLowering::emitAtomicBinaryPartword(
MachineInstr &MI, MachineBasicBlock *BB, unsigned Size, unsigned BinOpcode,
bool Nand) const {
assert((Size == 1 || Size == 2) &&
"Unsupported size for EmitAtomicBinaryPartial.");
MachineFunction *MF = BB->getParent();
MachineRegisterInfo &RegInfo = MF->getRegInfo();
const TargetRegisterClass *RC = getRegClassFor(MVT::i32);
const TargetInstrInfo *TII = Subtarget.getInstrInfo();
DebugLoc DL = MI.getDebugLoc();
unsigned Dest = MI.getOperand(0).getReg();
unsigned Ptr = MI.getOperand(1).getReg();
unsigned Incr = MI.getOperand(2).getReg();
unsigned AlignedAddr = RegInfo.createVirtualRegister(RC);
unsigned ShiftAmt = RegInfo.createVirtualRegister(RC);
unsigned Mask = RegInfo.createVirtualRegister(RC);
unsigned Mask2 = RegInfo.createVirtualRegister(RC);
unsigned Mask3 = RegInfo.createVirtualRegister(RC);
unsigned NewVal = RegInfo.createVirtualRegister(RC);
unsigned OldVal = RegInfo.createVirtualRegister(RC);
unsigned Incr2 = RegInfo.createVirtualRegister(RC);
unsigned MaskLSB2 = RegInfo.createVirtualRegister(RC);
unsigned PtrLSB2 = RegInfo.createVirtualRegister(RC);
unsigned MaskUpper = RegInfo.createVirtualRegister(RC);
unsigned AndRes = RegInfo.createVirtualRegister(RC);
unsigned BinOpRes = RegInfo.createVirtualRegister(RC);
unsigned BinOpRes2 = RegInfo.createVirtualRegister(RC);
unsigned MaskedOldVal0 = RegInfo.createVirtualRegister(RC);
unsigned StoreVal = RegInfo.createVirtualRegister(RC);
unsigned MaskedOldVal1 = RegInfo.createVirtualRegister(RC);
unsigned SrlRes = RegInfo.createVirtualRegister(RC);
unsigned Success = RegInfo.createVirtualRegister(RC);
// insert new blocks after the current block
const BasicBlock *LLVM_BB = BB->getBasicBlock();
MachineBasicBlock *loopMBB = MF->CreateMachineBasicBlock(LLVM_BB);
MachineBasicBlock *sinkMBB = MF->CreateMachineBasicBlock(LLVM_BB);
MachineBasicBlock *exitMBB = MF->CreateMachineBasicBlock(LLVM_BB);
MachineFunction::iterator It = ++BB->getIterator();
MF->insert(It, loopMBB);
MF->insert(It, sinkMBB);
MF->insert(It, exitMBB);
// Transfer the remainder of BB and its successor edges to exitMBB.
exitMBB->splice(exitMBB->begin(), BB,
std::next(MachineBasicBlock::iterator(MI)), BB->end());
exitMBB->transferSuccessorsAndUpdatePHIs(BB);
BB->addSuccessor(loopMBB);
loopMBB->addSuccessor(loopMBB);
loopMBB->addSuccessor(sinkMBB);
sinkMBB->addSuccessor(exitMBB);
// thisMBB:
// addiu masklsb2,$0,-4 # 0xfffffffc
// and alignedaddr,ptr,masklsb2
// andi ptrlsb2,ptr,3
// sll shiftamt,ptrlsb2,3
// ori maskupper,$0,255 # 0xff
// sll mask,maskupper,shiftamt
// xor mask2,$0,mask
// xor mask3,$0,mask2
// sll incr2,incr,shiftamt
int64_t MaskImm = (Size == 1) ? 255 : 65535;
BuildMI(BB, DL, TII->get(Cpu0::ADDiu), MaskLSB2)
.addReg(Cpu0::ZERO).addImm(-4);
BuildMI(BB, DL, TII->get(Cpu0::AND), AlignedAddr)
.addReg(Ptr).addReg(MaskLSB2);
BuildMI(BB, DL, TII->get(Cpu0::ANDi), PtrLSB2).addReg(Ptr).addImm(3);
if (Subtarget.isLittle()) {
BuildMI(BB, DL, TII->get(Cpu0::SHL), ShiftAmt).addReg(PtrLSB2).addImm(3);
} else {
unsigned Off = RegInfo.createVirtualRegister(RC);
BuildMI(BB, DL, TII->get(Cpu0::XORi), Off)
.addReg(PtrLSB2).addImm((Size == 1) ? 3 : 2);
BuildMI(BB, DL, TII->get(Cpu0::SHL), ShiftAmt).addReg(Off).addImm(3);
}
BuildMI(BB, DL, TII->get(Cpu0::ORi), MaskUpper)
.addReg(Cpu0::ZERO).addImm(MaskImm);
BuildMI(BB, DL, TII->get(Cpu0::SHLV), Mask)
.addReg(MaskUpper).addReg(ShiftAmt);
BuildMI(BB, DL, TII->get(Cpu0::XOR), Mask2).addReg(Cpu0::ZERO).addReg(Mask);
BuildMI(BB, DL, TII->get(Cpu0::XOR), Mask3).addReg(Cpu0::ZERO).addReg(Mask2);
BuildMI(BB, DL, TII->get(Cpu0::SHLV), Incr2).addReg(Incr).addReg(ShiftAmt);
// atomic.load.binop
// loopMBB:
// ll oldval,0(alignedaddr)
// binop binopres,oldval,incr2
// and newval,binopres,mask
// and maskedoldval0,oldval,mask3
// or storeval,maskedoldval0,newval
// sc success,storeval,0(alignedaddr)
// beq success,$0,loopMBB
// atomic.swap
// loopMBB:
// ll oldval,0(alignedaddr)
// and newval,incr2,mask
// and maskedoldval0,oldval,mask3
// or storeval,maskedoldval0,newval
// sc success,storeval,0(alignedaddr)
// beq success,$0,loopMBB
BB = loopMBB;
unsigned LL = Cpu0::LL;
BuildMI(BB, DL, TII->get(LL), OldVal).addReg(AlignedAddr).addImm(0);
if (Nand) {
// and andres, oldval, incr2
// xor binopres, $0, andres
// xor binopres2, $0, binopres
// and newval, binopres, mask
BuildMI(BB, DL, TII->get(Cpu0::AND), AndRes).addReg(OldVal).addReg(Incr2);
BuildMI(BB, DL, TII->get(Cpu0::XOR), BinOpRes)
.addReg(Cpu0::ZERO).addReg(AndRes);
BuildMI(BB, DL, TII->get(Cpu0::XOR), BinOpRes2)
.addReg(Cpu0::ZERO).addReg(BinOpRes);
BuildMI(BB, DL, TII->get(Cpu0::AND), NewVal).addReg(BinOpRes).addReg(Mask);
} else if (BinOpcode) {
// <binop> binopres, oldval, incr2
// and newval, binopres, mask
BuildMI(BB, DL, TII->get(BinOpcode), BinOpRes).addReg(OldVal).addReg(Incr2);
BuildMI(BB, DL, TII->get(Cpu0::AND), NewVal).addReg(BinOpRes).addReg(Mask);
} else { // atomic.swap
// and newval, incr2, mask
BuildMI(BB, DL, TII->get(Cpu0::AND), NewVal).addReg(Incr2).addReg(Mask);
}
BuildMI(BB, DL, TII->get(Cpu0::AND), MaskedOldVal0)
.addReg(OldVal).addReg(Mask2);
BuildMI(BB, DL, TII->get(Cpu0::OR), StoreVal)
.addReg(MaskedOldVal0).addReg(NewVal);
unsigned SC = Cpu0::SC;
BuildMI(BB, DL, TII->get(SC), Success)
.addReg(StoreVal).addReg(AlignedAddr).addImm(0);
BuildMI(BB, DL, TII->get(Cpu0::BEQ))
.addReg(Success).addReg(Cpu0::ZERO).addMBB(loopMBB);
// sinkMBB:
// and maskedoldval1,oldval,mask
// srl srlres,maskedoldval1,shiftamt
// sign_extend dest,srlres
BB = sinkMBB;
BuildMI(BB, DL, TII->get(Cpu0::AND), MaskedOldVal1)
.addReg(OldVal).addReg(Mask);
BuildMI(BB, DL, TII->get(Cpu0::SHRV), SrlRes)
.addReg(MaskedOldVal1).addReg(ShiftAmt);
BB = emitSignExtendToI32InReg(MI, BB, Size, Dest, SrlRes);
MI.eraseFromParent(); // The instruction is gone now.
return exitMBB;
}
MachineBasicBlock * Cpu0TargetLowering::emitAtomicCmpSwap(MachineInstr &MI,
MachineBasicBlock *BB,
unsigned Size) const {
assert((Size == 4) && "Unsupported size for EmitAtomicCmpSwap.");
MachineFunction *MF = BB->getParent();
MachineRegisterInfo &RegInfo = MF->getRegInfo();
const TargetRegisterClass *RC = getRegClassFor(MVT::getIntegerVT(Size * 8));
const TargetInstrInfo *TII = Subtarget.getInstrInfo();
DebugLoc DL = MI.getDebugLoc();
unsigned LL, SC, ZERO, BNE, BEQ;
LL = Cpu0::LL;
SC = Cpu0::SC;
ZERO = Cpu0::ZERO;
BNE = Cpu0::BNE;
BEQ = Cpu0::BEQ;
unsigned Dest = MI.getOperand(0).getReg();
unsigned Ptr = MI.getOperand(1).getReg();
unsigned OldVal = MI.getOperand(2).getReg();
unsigned NewVal = MI.getOperand(3).getReg();
unsigned Success = RegInfo.createVirtualRegister(RC);
// insert new blocks after the current block
const BasicBlock *LLVM_BB = BB->getBasicBlock();
MachineBasicBlock *loop1MBB = MF->CreateMachineBasicBlock(LLVM_BB);
MachineBasicBlock *loop2MBB = MF->CreateMachineBasicBlock(LLVM_BB);
MachineBasicBlock *exitMBB = MF->CreateMachineBasicBlock(LLVM_BB);
MachineFunction::iterator It = ++BB->getIterator();
MF->insert(It, loop1MBB);
MF->insert(It, loop2MBB);
MF->insert(It, exitMBB);
// Transfer the remainder of BB and its successor edges to exitMBB.
exitMBB->splice(exitMBB->begin(), BB,
std::next(MachineBasicBlock::iterator(MI)), BB->end());
exitMBB->transferSuccessorsAndUpdatePHIs(BB);
// thisMBB:
// ...
// fallthrough --> loop1MBB
BB->addSuccessor(loop1MBB);
loop1MBB->addSuccessor(exitMBB);
loop1MBB->addSuccessor(loop2MBB);
loop2MBB->addSuccessor(loop1MBB);
loop2MBB->addSuccessor(exitMBB);
// loop1MBB:
// ll dest, 0(ptr)
// bne dest, oldval, exitMBB
BB = loop1MBB;
BuildMI(BB, DL, TII->get(LL), Dest).addReg(Ptr).addImm(0);
BuildMI(BB, DL, TII->get(BNE))
.addReg(Dest).addReg(OldVal).addMBB(exitMBB);
// loop2MBB:
// sc success, newval, 0(ptr)
// beq success, $0, loop1MBB
BB = loop2MBB;
BuildMI(BB, DL, TII->get(SC), Success)
.addReg(NewVal).addReg(Ptr).addImm(0);
BuildMI(BB, DL, TII->get(BEQ))
.addReg(Success).addReg(ZERO).addMBB(loop1MBB);
MI.eraseFromParent(); // The instruction is gone now.
return exitMBB;
}
MachineBasicBlock *
Cpu0TargetLowering::emitAtomicCmpSwapPartword(MachineInstr &MI,
MachineBasicBlock *BB,
unsigned Size) const {
assert((Size == 1 || Size == 2) &&
"Unsupported size for EmitAtomicCmpSwapPartial.");
MachineFunction *MF = BB->getParent();
MachineRegisterInfo &RegInfo = MF->getRegInfo();
const TargetRegisterClass *RC = getRegClassFor(MVT::i32);
const TargetInstrInfo *TII = Subtarget.getInstrInfo();
DebugLoc DL = MI.getDebugLoc();
unsigned Dest = MI.getOperand(0).getReg();
unsigned Ptr = MI.getOperand(1).getReg();
unsigned CmpVal = MI.getOperand(2).getReg();
unsigned NewVal = MI.getOperand(3).getReg();
unsigned AlignedAddr = RegInfo.createVirtualRegister(RC);
unsigned ShiftAmt = RegInfo.createVirtualRegister(RC);
unsigned Mask = RegInfo.createVirtualRegister(RC);
unsigned Mask2 = RegInfo.createVirtualRegister(RC);
unsigned Mask3 = RegInfo.createVirtualRegister(RC);
unsigned ShiftedCmpVal = RegInfo.createVirtualRegister(RC);
unsigned OldVal = RegInfo.createVirtualRegister(RC);
unsigned MaskedOldVal0 = RegInfo.createVirtualRegister(RC);
unsigned ShiftedNewVal = RegInfo.createVirtualRegister(RC);
unsigned MaskLSB2 = RegInfo.createVirtualRegister(RC);
unsigned PtrLSB2 = RegInfo.createVirtualRegister(RC);
unsigned MaskUpper = RegInfo.createVirtualRegister(RC);
unsigned MaskedCmpVal = RegInfo.createVirtualRegister(RC);
unsigned MaskedNewVal = RegInfo.createVirtualRegister(RC);
unsigned MaskedOldVal1 = RegInfo.createVirtualRegister(RC);
unsigned StoreVal = RegInfo.createVirtualRegister(RC);
unsigned SrlRes = RegInfo.createVirtualRegister(RC);
unsigned Success = RegInfo.createVirtualRegister(RC);
// insert new blocks after the current block
const BasicBlock *LLVM_BB = BB->getBasicBlock();
MachineBasicBlock *loop1MBB = MF->CreateMachineBasicBlock(LLVM_BB);
MachineBasicBlock *loop2MBB = MF->CreateMachineBasicBlock(LLVM_BB);
MachineBasicBlock *sinkMBB = MF->CreateMachineBasicBlock(LLVM_BB);
MachineBasicBlock *exitMBB = MF->CreateMachineBasicBlock(LLVM_BB);
MachineFunction::iterator It = ++BB->getIterator();
MF->insert(It, loop1MBB);
MF->insert(It, loop2MBB);
MF->insert(It, sinkMBB);
MF->insert(It, exitMBB);
// Transfer the remainder of BB and its successor edges to exitMBB.
exitMBB->splice(exitMBB->begin(), BB,
std::next(MachineBasicBlock::iterator(MI)), BB->end());
exitMBB->transferSuccessorsAndUpdatePHIs(BB);
BB->addSuccessor(loop1MBB);
loop1MBB->addSuccessor(sinkMBB);
loop1MBB->addSuccessor(loop2MBB);
loop2MBB->addSuccessor(loop1MBB);
loop2MBB->addSuccessor(sinkMBB);
sinkMBB->addSuccessor(exitMBB);
// FIXME: computation of newval2 can be moved to loop2MBB.
// thisMBB:
// addiu masklsb2,$0,-4 # 0xfffffffc
// and alignedaddr,ptr,masklsb2
// andi ptrlsb2,ptr,3
// shl shiftamt,ptrlsb2,3
// ori maskupper,$0,255 # 0xff
// shl mask,maskupper,shiftamt
// xor mask2,$0,mask
// xor mask3,$0,mask2
// andi maskedcmpval,cmpval,255
// shl shiftedcmpval,maskedcmpval,shiftamt
// andi maskednewval,newval,255
// shl shiftednewval,maskednewval,shiftamt
int64_t MaskImm = (Size == 1) ? 255 : 65535;
BuildMI(BB, DL, TII->get(Cpu0::ADDiu), MaskLSB2)
.addReg(Cpu0::ZERO).addImm(-4);
BuildMI(BB, DL, TII->get(Cpu0::AND), AlignedAddr)
.addReg(Ptr).addReg(MaskLSB2);
BuildMI(BB, DL, TII->get(Cpu0::ANDi), PtrLSB2).addReg(Ptr).addImm(3);
if (Subtarget.isLittle()) {
BuildMI(BB, DL, TII->get(Cpu0::SHL), ShiftAmt).addReg(PtrLSB2).addImm(3);
} else {
unsigned Off = RegInfo.createVirtualRegister(RC);
BuildMI(BB, DL, TII->get(Cpu0::XORi), Off)
.addReg(PtrLSB2).addImm((Size == 1) ? 3 : 2);
BuildMI(BB, DL, TII->get(Cpu0::SHL), ShiftAmt).addReg(Off).addImm(3);
}
BuildMI(BB, DL, TII->get(Cpu0::ORi), MaskUpper)
.addReg(Cpu0::ZERO).addImm(MaskImm);
BuildMI(BB, DL, TII->get(Cpu0::SHLV), Mask)
.addReg(MaskUpper).addReg(ShiftAmt);
BuildMI(BB, DL, TII->get(Cpu0::XOR), Mask2).addReg(Cpu0::ZERO).addReg(Mask);
BuildMI(BB, DL, TII->get(Cpu0::XOR), Mask3).addReg(Cpu0::ZERO).addReg(Mask2);
BuildMI(BB, DL, TII->get(Cpu0::ANDi), MaskedCmpVal)
.addReg(CmpVal).addImm(MaskImm);
BuildMI(BB, DL, TII->get(Cpu0::SHLV), ShiftedCmpVal)
.addReg(MaskedCmpVal).addReg(ShiftAmt);
BuildMI(BB, DL, TII->get(Cpu0::ANDi), MaskedNewVal)
.addReg(NewVal).addImm(MaskImm);
BuildMI(BB, DL, TII->get(Cpu0::SHLV), ShiftedNewVal)
.addReg(MaskedNewVal).addReg(ShiftAmt);
// loop1MBB:
// ll oldval,0(alginedaddr)
// and maskedoldval0,oldval,mask
// bne maskedoldval0,shiftedcmpval,sinkMBB
BB = loop1MBB;
unsigned LL = Cpu0::LL;
BuildMI(BB, DL, TII->get(LL), OldVal).addReg(AlignedAddr).addImm(0);
BuildMI(BB, DL, TII->get(Cpu0::AND), MaskedOldVal0)
.addReg(OldVal).addReg(Mask);
BuildMI(BB, DL, TII->get(Cpu0::BNE))
.addReg(MaskedOldVal0).addReg(ShiftedCmpVal).addMBB(sinkMBB);
// loop2MBB:
// and maskedoldval1,oldval,mask3
// or storeval,maskedoldval1,shiftednewval
// sc success,storeval,0(alignedaddr)
// beq success,$0,loop1MBB
BB = loop2MBB;
BuildMI(BB, DL, TII->get(Cpu0::AND), MaskedOldVal1)
.addReg(OldVal).addReg(Mask3);
BuildMI(BB, DL, TII->get(Cpu0::OR), StoreVal)
.addReg(MaskedOldVal1).addReg(ShiftedNewVal);
unsigned SC = Cpu0::SC;
BuildMI(BB, DL, TII->get(SC), Success)
.addReg(StoreVal).addReg(AlignedAddr).addImm(0);
BuildMI(BB, DL, TII->get(Cpu0::BEQ))
.addReg(Success).addReg(Cpu0::ZERO).addMBB(loop1MBB);
// sinkMBB:
// srl srlres,maskedoldval0,shiftamt
// sign_extend dest,srlres
BB = sinkMBB;
BuildMI(BB, DL, TII->get(Cpu0::SHRV), SrlRes)
.addReg(MaskedOldVal0).addReg(ShiftAmt);
BB = emitSignExtendToI32InReg(MI, BB, Size, Dest, SrlRes);
MI.eraseFromParent(); // The instruction is gone now.
return exitMBB;
}
SDValue Cpu0TargetLowering::lowerATOMIC_FENCE(SDValue Op,
SelectionDAG &DAG) const {
// FIXME: Need pseudo-fence for 'singlethread' fences
// FIXME: Set SType for weaker fences where supported/appropriate.
unsigned SType = 0;
SDLoc DL(Op);
return DAG.getNode(Cpu0ISD::Sync, DL, MVT::Other, Op.getOperand(0),
DAG.getConstant(SType, DL, MVT::i32));
}
lbdex/chapters/Chapter12_1/Cpu0RegisterInfo.h
/// Code Generation virtual methods...
const TargetRegisterClass *getPointerRegClass(const MachineFunction &MF,
unsigned Kind) const override;
lbdex/chapters/Chapter12_1/Cpu0RegisterInfo.cpp
const TargetRegisterClass *
Cpu0RegisterInfo::getPointerRegClass(const MachineFunction &MF,
unsigned Kind) const {
return &Cpu0::CPURegsRegClass;
}
lbdex/chapters/Chapter12_1/Cpu0SEISelLowering.cpp
Cpu0SETargetLowering::Cpu0SETargetLowering(const Cpu0TargetMachine &TM,
const Cpu0Subtarget &STI)
: Cpu0TargetLowering(TM, STI) {
setOperationAction(ISD::ATOMIC_FENCE, MVT::Other, Custom);
...
}
lbdex/chapters/Chapter12_1/Cpu0TargetMachine.cpp
/// Cpu0 Code Generator Pass Configuration Options.
class Cpu0PassConfig : public TargetPassConfig {
void addIRPasses() override;
...
};
void Cpu0PassConfig::addIRPasses() {
TargetPassConfig::addIRPasses();
addPass(createAtomicExpandPass());
}
Since the SC instruction uses RegisterOperand type in Cpu0InstrInfo.td and SC uses the FMem node whose DecoderMethod is DecodeMem, the DecodeMem() function in Cpu0Disassembler.cpp needs to be modified accordingly.
The atomic node defined in let usesCustomInserter = 1 in within Cpu0InstrInfo.td tells LLVM to call EmitInstrWithCustomInserter() in Cpu0ISelLowering.cpp after the Instruction Selection stage, specifically in the Cpu0TargetLowering::EmitInstrWithCustomInserter() function invoked during the ExpandISelPseudos::runOnMachineFunction() phase.
For example, the declaration def ATOMIC_LOAD_ADD_I8 : Atomic2Ops<atomic_load_add_8, CPURegs>; will trigger a call to EmitInstrWithCustomInserter() with the machine instruction opcode ATOMIC_LOAD_ADD_I8 when the IR load atomic i8* is encountered.
The call to setInsertFencesForAtomic(true); in Cpu0ISelLowering.cpp will trigger the addIRPasses() function in Cpu0TargetMachine.cpp, which in turn invokes createAtomicExpandPass() to create the LLVM IR ATOMIC_FENCE.
Later, lowerATOMIC_FENCE() in Cpu0ISelLowering.cpp will emit a Cpu0ISD::Sync when it sees an ATOMIC_FENCE IR, because of the statement setOperationAction(ISD::ATOMIC_FENCE, MVT::Other, Custom); in Cpu0SEISelLowering.cpp.
Finally, the pattern defined in Cpu0InstrInfo.td will translate the DAG node into the actual sync instruction via def SYNC and its alias SYNC 0.
This part of the Cpu0 backend code is similar to Mips, except that Cpu0 does not include the nor instruction.
Below is a table listing the atomic IRs, their corresponding DAG nodes, and machine opcodes.
IR |
DAG |
Opcode |
|---|---|---|
load atomic |
AtomicLoad |
ATOMIC_CMP_SWAP_XXX |
store atomic |
AtomicStore |
ATOMIC_SWAP_XXX |
atomicrmw add |
AtomicLoadAdd |
ATOMIC_LOAD_ADD_XXX |
atomicrmw sub |
AtomicLoadSub |
ATOMIC_LOAD_SUB_XXX |
atomicrmw xor |
AtomicLoadXor |
ATOMIC_LOAD_XOR_XXX |
atomicrmw and |
AtomicLoadAnd |
ATOMIC_LOAD_AND_XXX |
atomicrmw nand |
AtomicLoadNand |
ATOMIC_LOAD_NAND_XXX |
atomicrmw or |
AtomicLoadOr |
ATOMIC_LOAD_OR_XXX |
cmpxchg |
AtomicCmpSwapWithSuccess |
ATOMIC_CMP_SWAP_XXX |
atomicrmw xchg |
AtomicLoadSwap |
ATOMIC_SWAP_XXX |
The input files atomics.ll and atomics-fences.ll include tests for LLVM atomic IRs.
The C++ source files ch12_atomics.cpp and ch12_atomics-fences.cpp are used to generate the corresponding LLVM atomic IRs. To compile these files, use the following clang++ options:
clang++ -pthread -std=c++11